工业资产管理中的多代理协同瓶颈
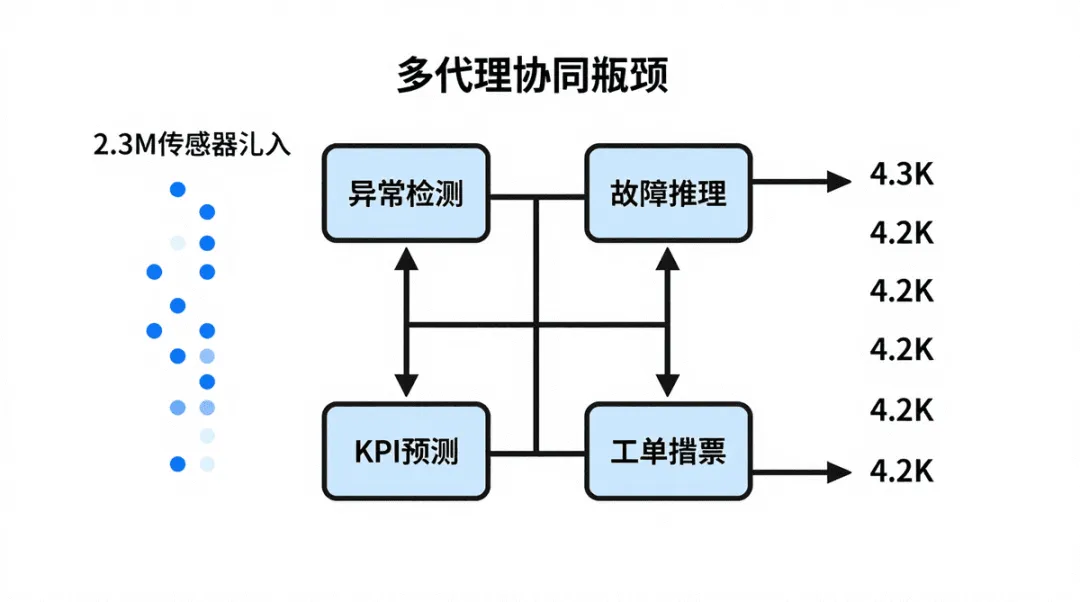
在传统 AI 基准(如代码生成、网页导航)中,评估往往聚焦单一任务的成功率,忽视了工业现场的多代理协同、时序依赖和噪声数据等关键约束。实际的资产生命周期管理涉及上万条传感器遥测(本基准提供 2.3 M 点)、数千条工单(4.2 K)以及 53 种结构化失效模式。若仅靠孤立的模型处理,容易出现锁竞争、信息孤岛以及对异常根因的错误推断,导致系统整体可靠性难以满足安全关键的工业需求。
AssetOpsBench六维评估框架与多代理工作流实现
AssetOpsBench 通过 六个定性维度 对工业 AI 代理进行全方位评估:
- Task Completion
- Retrieval Accuracy
- Result Verification
- Sequence Correctness
- Clarity and Justification
- Hallucination Rate
这些维度覆盖了 决策追溯质量、证据依据、失效感知与可操作性,直接映射到工业现场的安全与可解释性需求。
关键数据资产
- 传感器遥测:2.3 M 条时间序列点,覆盖冷水机组、空气处理单元等。
- 场景库:140 + 条精心策划的情景,涉及四类代理的交叉任务。
- 工单池:4.2 K 条工单,覆盖维护、故障修复、优先级调度等。
- 失效模式
多代理工作流概述
每一次评估运行,四个代理(Anomaly Detector、Failure Reasoner、KPI Forecaster、Work Order Summarizer)在同一场景下并行或顺序协作。以下伪代码展示了基于 Python 的评估循环结构,严格依据源材料中的评分维度实现:
import jsonfrom typing importList, Dict# ---- 数据加载(已在资产库中预置)----telemetry = load_telemetry("sensor_data.parquet") # 2.3M pointsscenarios = json.load(open("scenarios.json")) # 140+ 场景work_orders = json.load(open("work_orders.json")) # 4.2K 条工单failure_modes = json.load(open("failure_modes.json")) # 53 种# ---- 代理接口(抽象)----classAgent:def__init__(self, name: str):self.name = namedefrun(self, context: Dict) -> Dict:"""返回包含结果、证据、步骤序列的字典"""raise NotImplementedError# 四类代理的实现(示例占位,实际由研究团队提供)classAnomalyDetector(Agent): ...classFailureReasoner(Agent): ...classKPIForecaster(Agent): ...classWorkOrderSummarizer(Agent): ...agents = [ AnomalyDetector("AnomalyDetector"), FailureReasoner("FailureReasoner"), KPIForecaster("KPIForecaster"), WorkOrderSummarizer("WorkOrderSummarizer")]# ---- 评估函数,依据六维指标打分 ----defevaluate(agent_output: Dict, scenario: Dict) -> Dict: scores = {"Task Completion": int(agent_output.get("task_done", False)),"Retrieval Accuracy": compute_retrieval_accuracy(agent_output, scenario),"Result Verification": compute_verification(agent_output),"Sequence Correctness": compute_sequence_correctness(agent_output),"Clarity and Justification": compute_clarity(agent_output),"Hallucination Rate": compute_hallucination(agent_output) }return scores# ---- 主评估循环 ----all_results = []for scen in scenarios: ctx = {"telemetry": telemetry.filter_by(scen["asset_id"]),"work_orders": work_orders.filter_by(scen["work_order_ids"]),"failure_modes": failure_modes } scenario_results = {"scenario_id": scen["id"], "agent_scores": {}}for ag in agents: out = ag.run(ctx) scenario_results["agent_scores"][ag.name] = evaluate(out, scen) all_results.append(scenario_results)# ---- 汇总报告 ----report = aggregate_results(all_results)print(json.dumps(report, indent=2, ensure_ascii=False))
关键实现要点
- 上下文统一:所有代理共享同一
ctx,确保信息一致性,避免因数据碎片导致的误判。 - 多维评分:每一步均调用专门的质量函数(如
compute_hallucination),实现对 Hallucination Rate 的细粒度监控。 - 可解释轨迹:
agent_output 必须包含 证据链(如关联的传感器片段、故障模式标签),满足 Clarity and Justification 要求。
通过上述框架,评测不仅给出 任务完成率,更提供 失败根因定位、证据完整性 等工业现场真正在意的维度。
评估维度的收益与实现成本
收益:
- 可解释性提升:多维评分迫使模型输出证据链,帮助运维人员快速定位异常根因。
- 真实场景适配:通过 53 种失效模式的显式标注,模型在噪声、缺失数据下仍能保持鲁棒性。
- 跨代理协同:统一上下文促进信息共享,显著降低传统单代理方案的锁竞争与信息孤岛问题。
代价:
- 标注开销:构建 150 + 场景、53 种失效模式需要行业专家深度参与,前期投入大。
- 评估复杂度:六维打分需要实现多套质量函数,计算开销约为单一成功率的 2–3 倍。
- 系统维护:随着资产种类扩展,需要持续更新传感器映射和工单模板,维护成本随规模线性增长。
整体来看,价值(可解释、可落地)远高于 实现成本,尤其在安全关键的工业环境中。
落地建议与核心价值概括
在生产环境部署时,建议先在子系统(如单一冷水机组)进行 AssetOpsBench 的小规模评估,验证代理的证据链质量后再逐步推广至全厂。核心价值在于通过六维质量评估,使 AI 代理从“能做事”转向“会解释、可靠且安全”,从而真正缩小实验室基准与现场运营之间的差距。