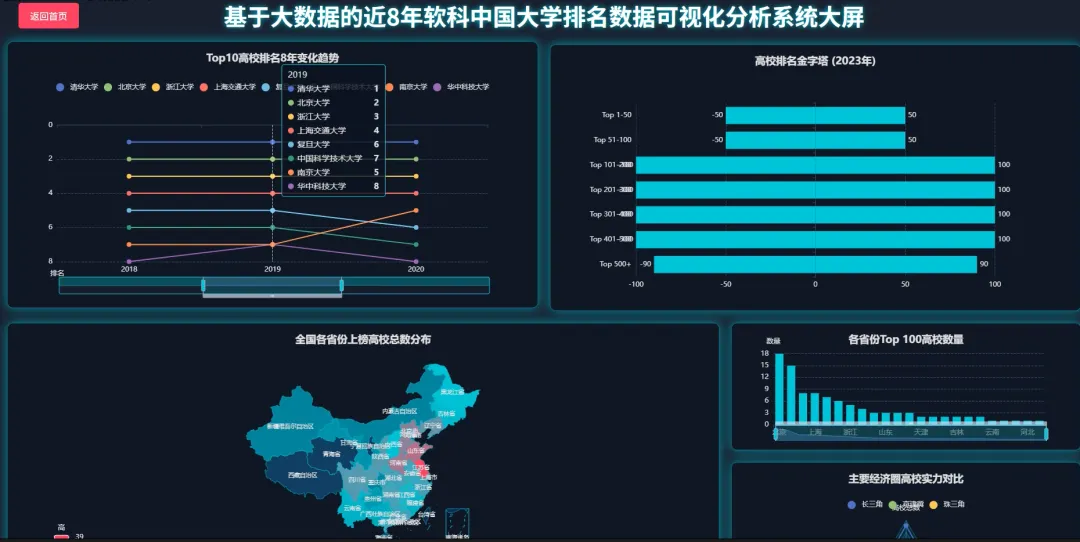
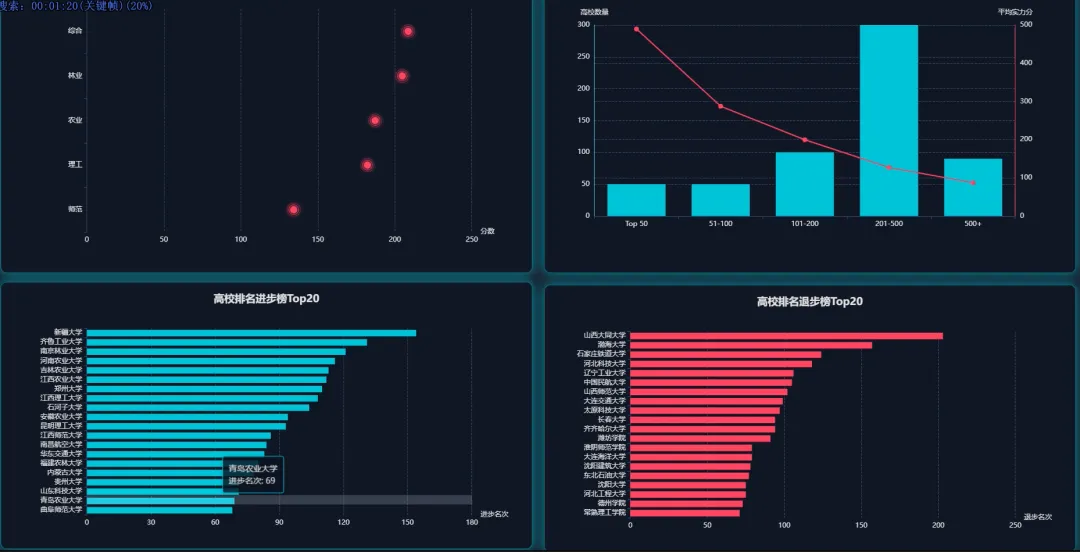
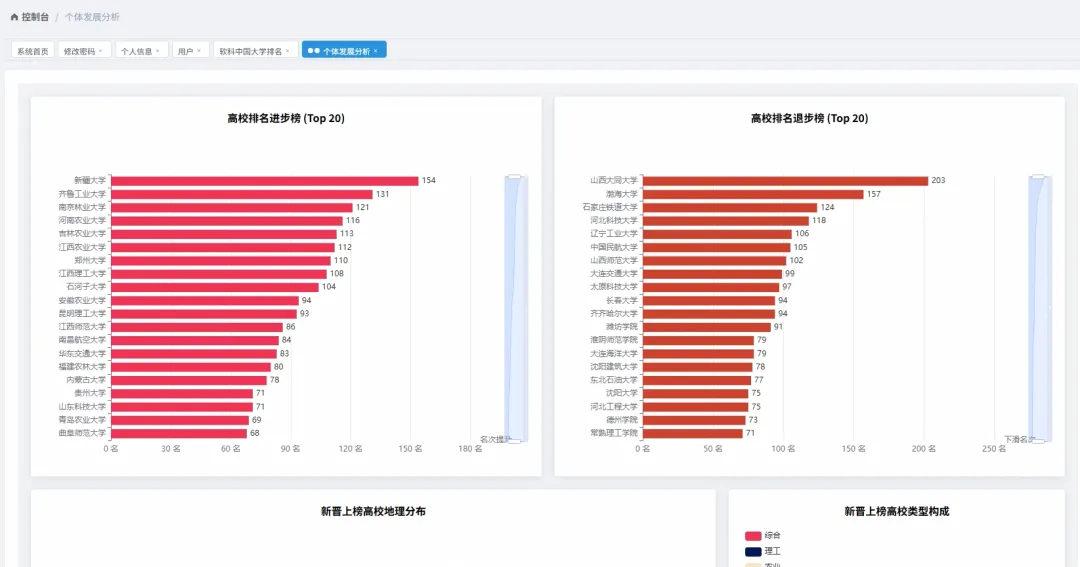
from pyspark.sql import SparkSession, Windowfrom pyspark.sql.functions import col, count, rank, desc, asc# 初始化SparkSession,这是所有Spark程序的入口spark = SparkSession.builder \ .appName("UniversityRankingAnalysis") \ .config("spark.sql.warehouse.dir", "/user/hive/warehouse") \ .enableHiveSupport() \ .getOrCreate()# 假设df是一个已经加载好的Spark DataFrame,包含Year, Rank, CN_Name, Province, Type, Score等列# df = spark.read.csv("hdfs://path/to/ranking_data.csv", header=True, inferSchema=True)def get_top10_trend(df): # 核心功能1: 顶尖高校(Top 10)近8年排名变化 # 筛选出每年排名前10的高校 top10_df = df.filter(col("Rank") <= 10) # 为了追踪变化,我们需要按学校名称和年份进行排序 # 这样在后续处理中,每个学校的排名会按时间顺序排列 sorted_df = top10_df.orderBy(asc("CN_Name"), asc("Year")) # 选择我们关心的列:年份、学校名称、排名 result_df = sorted_df.select("Year", "CN_Name", "Rank") # 将Spark DataFrame转换为Pandas DataFrame以便API返回或进一步处理 # 在实际应用中,可能直接返回JSON格式 return result_df.toPandas().to_dict(orient="records")def get_top100_by_province(df, target_year): # 核心功能2: 各省份顶尖(Top 100)高校数量 # 筛选出指定年份且排名在Top100的高校 top100_df = df.filter((col("Year") == target_year) & (col("Rank") <= 100)) # 按省份进行分组,然后计算每个省份内的高校数量 province_count_df = top100_df.groupBy("Province").agg(count("CN_Name").alias("university_count")) # 按高校数量降序排列,找出教育资源最集中的省份 sorted_province_df = province_count_df.orderBy(desc("university_count")) # 转换为字典列表格式返回 return sorted_province_df.toPandas().to_dict(orient="records")def get_university_progress_ranking(df, start_year, end_year): # 核心功能3: 高校排名进步榜(对比两个年份) # 分别获取起始年份和结束年份的排名数据 start_df = df.filter(col("Year") == start_year).select(col("CN_Name").alias("Name_Start"), col("Rank").alias("Rank_Start")) end_df = df.filter(col("Year") == end_year).select(col("CN_Name").alias("Name_End"), col("Rank").alias("Rank_End")) # 通过学校名称将两个年份的数据连接起来 # 使用内连接,只保留两年都在榜的高校 joined_df = start_df.join(end_df, start_df.Name_Start == end_df.Name_End, "inner") # 计算排名变化量,起始排名减去结束排名 # 结果为正数表示排名上升(进步),为负数表示下降 progress_df = joined_df.withColumn("Rank_Change", col("Rank_Start") - col("Rank_End")) # 筛选出有进步的高校(排名变化 > 0) progressed_df = progress_df.filter(col("Rank_Change") > 0) # 按排名变化量降序排列,进步最多的排在最前面 final_df = progressed_df.orderBy(desc("Rank_Change")) # 选择最终要展示的列并返回 return final_df.select(col("Name_End").alias("CN_Name"), "Rank_Start", "Rank_End", "Rank_Change").toPandas().to_dict(orient="records")