HMM(隐马尔可夫模型)简易教学示例:使用 depmixS4 快速上手
视频版(包含理论讲解):https://www.bilibili.com/video/BV1LnzKBrEto
交流群(过期可关注公众号获取):
本脚本分为三部分:
1) 用 depmixS4 在 sp500 数据上拟合一个最基本的 HMM,并做可视化
2) 用信息准则(BIC/AIC/logLik)比较不同状态数,辅助选择HMM的状态数
3) 多响应 + 多被试 + 含分类变量的 HMM 拟合与可视化
依赖包:
library(depmixS4)library(ggplot2)
1) depmixS4 拟合 HMM:以 sp500 数据集为例
数据说明:
- 其中变量logret表示对数收益率(log return),这里作为观测序列
模型设定:
- logret ~ 1 表示每个状态下 logret 的均值为常数(只有截距项)
- nstates=2 表示有两个隐状态(可理解为“低波动/高波动”之类的潜在市场机制)
- depmix 默认会为观测方程与转移概率构建参数化形式,然后用 fit() 估计
data(sp500)model <- depmix(logret~1,data=sp500,nstates=2)fit <- fit(model)summary(fit)
Initial state probabilities model1.1) 信息提取
posterior(type="smoothing"):
- 计算在“看到全序列观测值”之后,每个时刻属于各隐状态的后验概率
- 结果是一个矩阵:每行对应时间 t,每列对应某个状态的概率
viterbi(fit)$state:
这里我们把:
组织成一个 data.frame,方便 ggplot 作图
pst <- posterior(fit,type='smoothing')df <- data.frame( t = seq_len(nrow(sp500)), logret = sp500$logret, S1 = pst[,1], S2 = pst[,2], state=factor(viterbi(fit)$state))
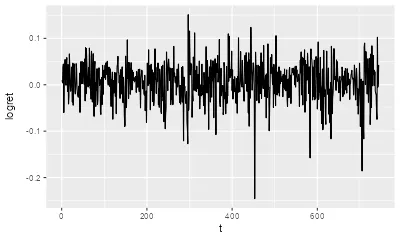
1.2) 可视化:原始收益率随时间变化
目标:
ggplot(df,aes(x=t,y=logret))+ geom_line()
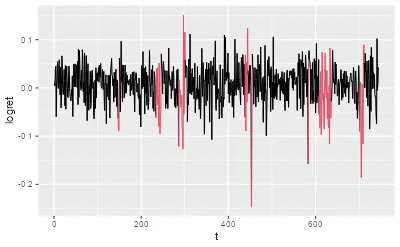
1.3) 可视化:按 Viterbi 解码的状态区分观测序列
目标:
- 使用 Viterbi 的 state 给每个时刻一个“最可能状态标签”
- 从而观察不同状态对应的收益率水平/波动特征是否不同
ggplot(df,aes(x=t,y=logret))+ geom_line(color=df$state)
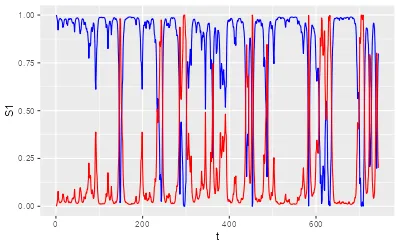
1.4) 可视化:两种隐状态的后验概率随时间变化
目标:
- 若某些时段 S1 接近 1、S2 接近 0,说明该段更确定属于状态1
- 若两者都在中间(例如 0.4/0.6),说明模型对状态归属不那么确定
这里画两条线:
ggplot(df) + geom_line(aes(t, S1),color='blue') + geom_line(aes(t, S2),color='red')
2) 如何决定状态数:比较不同K下的模型指标
核心思想:
- K 越大,模型越灵活,logLik(对数似然)通常越高
- 信息准则(AIC/BIC)在“拟合优度”和“模型复杂度”之间做折中
常见选择习惯:
- 也可以同时看 AIC / logLik 曲线作为参考
下面做法:
K <- 6bic <- aic <- ll <- numeric(K)for(n in 1:K){ fit <- fit(depmix(logret~1,data=sp500,nstates=n)) bic[n] <- BIC(fit) aic[n] <- AIC(fit) ll[n] <- logLik(fit)}info <- data.frame( K=1:K, BIC=bic, AIC=aic, logLik=ll)info
2.1) 可视化:BIC 随 K 变化,并标注最优 K(BIC 最小)
目标:
ggplot(info,aes(K,BIC))+ geom_line()+ geom_point()+ geom_vline(xintercept = info$K[which.min(info$BIC)],linetype=2)
3) 多响应、多被试、包含分类变量:以 speed 数据为例
数据说明:
- 包含 3 个被试(s1=168, s2=134, s3=137 个时间点)
1) rt:反应时(连续变量),用 gaussian() 建模
2) corr:正确与否(0/1),用 binomial() 建模
建模要点:
- list(rt
1, corr1):表示有两个观测响应 - family=list(gaussian(), binomial()):为每个响应指定分布族
- ntimes=nt:告诉模型每个被试序列长度,用于把长向量切成 3 段序列
结果提取与可视化:
- 将 sub、time、rt、corr、state 组织成 df_rt
- 分别对 rt 和 corr 做可视化,从而观察不同隐状态下行为表现差异
data(speed)nt <- c(168,134,137)fitmod <- fit(depmix(list(rt~1,corr~1), data=speed, nstates=2,family=list(gaussian(),binomial()), ntimes=nt))df_rt <- data.frame( sub = rep(1:3, nt), time = sequence(nt), rt = speed$rt, corr = speed$corr, state= factor(viterbi(fitmod)$state))
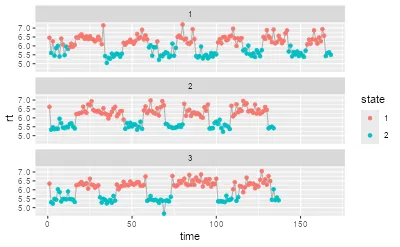
3.1) 可视化:反应时(rt)随时间变化,并按状态着色,分被试展示
目标:
- 直观观察:某些状态是否对应更快/更慢的反应时水平或波动模式
ggplot(df_rt, aes(time, rt)) + geom_line(color="grey70") + geom_point(aes(color=state)) + facet_wrap(~sub, ncol=1)
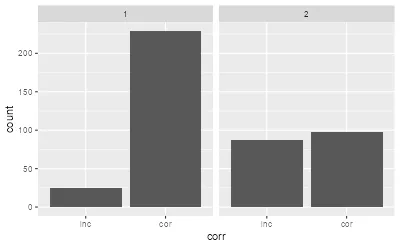
3.2) 可视化:正确率(corr)在不同状态下的分布
目标:
- corr 是分类变量(0/1),这里先用柱状图看频数
- facet_wrap(~state) 把不同隐状态分开,比较:
在状态1 vs 状态2 下,正确/错误的比例是否不同
- 这能帮助解释“隐状态”在行为层面的含义
ggplot(df_rt, aes(corr)) + geom_bar() + facet_wrap(~state)

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
