2026年,编程领域正经历一场静默的革命。曾几何时,开发者为获取顶级AI编程能力,不得不支付每月数百元的订阅费用;如今,以DeepSeek V3.2、GLM-4.7、Qwen3-Coder为代表的中国开源模型,正以前所未有的性能表现,重新定义AI辅助编程的行业格局。
性能突破:开源模型的全面崛起
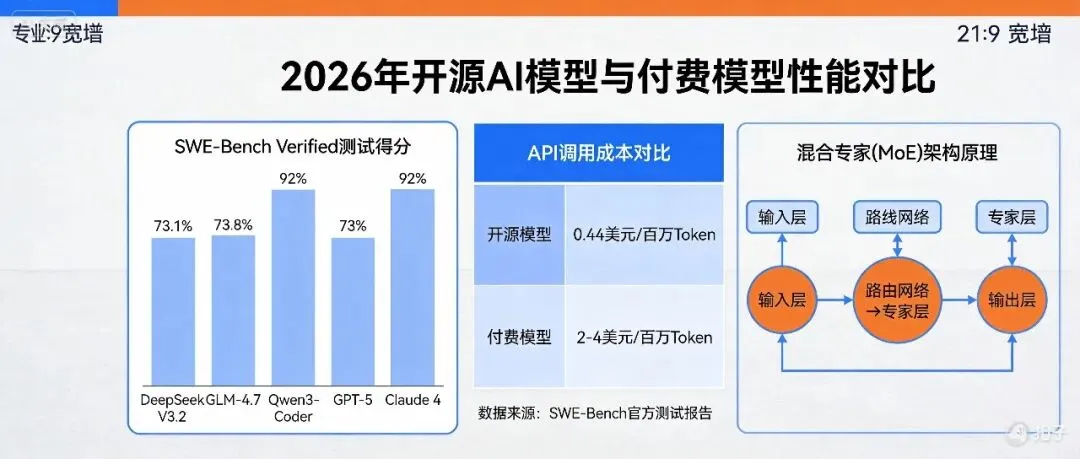
在多项权威基准测试中,国产开源模型已展现出与顶级闭源模型分庭抗礼的实力。DeepSeek V3.2-Speciale在SWE-Verified基准测试中斩获73.1%的分数,与GPT-5和Gemini 3.0 Pro相当。GLM-4.7则凭借73.8%的SWE-Bench Verified得分,稳居开
源模型榜首,其在τ²-Bench工具调用评测中获得87.4分,超越了闭源的Claude Sonnet 4.5。Qwen3-Coder在SWE-Bench Verified上取得92%的成绩,与Claude 4持平,原生支持256K token上下文并可扩展至1M长度,为大型项目智能化开发提供了坚实支撑。
技术架构:效率革命的底层逻辑
开源模型的突破性表现,源于其在架构设计上的系统性创新。混合专家(MoE)架构的广泛应用,使得模型能够在保持强大能力的同时,有效控制推理成本。DeepSeek V3.2通过稀疏注意力技术将传统注意力机制O(L²)的计算复杂度降至O(Lk),长文本处理的计算量大幅缩减84%。GLM-4.7引入的“三级思考”机制,则代表着可控推理的重大进步——交错式思考确保深度推理,保留式思考实现多轮对话思考块重用,轮级思考允许按需控制推理开销。
更值得关注的是,这些模型普遍支持超长上下文窗口。从DeepSeek的128K到Qwen3-Coder的1M,这种能力让AI能够理解整个代码库的架构逻辑,为跨文件重构、大型项目维护提供了前所未有的智能化支持。
成本优势:普惠开发的经济学
开源模型最直接的冲击,体现在其颠覆性的性价比上。以GLM-4.7为例,其API调用成本仅为0.44美元/100万Token,相较于同类闭源模型便宜4-7倍。年订阅费用可控制在240元以内,而功能相近的闭源工具往往需要每月数百元的支出。
DeepSeek V3.2的本地部署方案,进一步凸显了开源模式的灵活性。通过Ollama等工具,开发者可以在RTX 4090/5090显卡上流畅运行33B-70B模型,代码全程不离开本地环境。对于处理敏感项目或需要严格数据隐私的企业而言,这种部署方式具有不可替代的价值。
行业应用:从实验室到生产环境
开源AI编程模型的实用价值,已在多个行业场景中得到验证。在金融领域,东方财富通过DeepSeek重构投研流程,合规审核效率提升3倍;建设银行每周自动化完成180个应用的代码评审,平均发现140个漏洞。制造业中,弘信电子将DeepSeek适配国产算力后,智能质检缺陷识别率从87%升至99.2%,硬件成本降低35%。
更值得关注的是,开源模型正在重塑软件开发的工作模式。传统需要资深程序员一周完成的工作,新手借助AI工具一天即可实现;一个品牌官网的搭建,从设计到部署最快仅需5分钟。这种效率的跃迁,是开发范式的根本性变革。
挑战与展望
尽管开源模型展现出强大的竞争力,其可持续发展仍面临多重挑战。硬件门槛是首当其冲的限制因素,流畅运行高端模型需要配备24GB以上显存的显卡,成本投入达数千元。生态短板同样不容忽视——相较于付费产品的标准化支持,开源模型更多依赖社区力量。商业模式的可持续性则是核心问题,目前行业开源项目的商业转化率仅为5%,远低于全球23%的平均水平。
面向未来,开源AI编程模型的发展将呈现三大趋势:技术融合深化、生态平台化、监管规范化。当免费工具的性能追平乃至超越付费产品,开发者面临的不再是“要不要为AI付费”的选择困境,而是如何最大化利用技术红利的能力挑战。
这场变革的核心,不仅是成本的降低,更是技术民主化的推进。开源模式打破了少数巨头对先进AI能力的垄断,让更多开发者、初创企业能够以更低门槛接触到前沿技术。对于开发者而言,真正的竞争力不再仅仅是编码技能的熟练度,而是驾驭AI工具解决复杂问题的综合能力。
2026年,开源AI编程模型不仅改变了工具生态,更在重新定义“编程”本身的意义。当代码生成从手动输入转向智能协作,人类开发者的角色将从执行者转变为架构师、决策者和创新者。这场变革刚刚开始,而它的终点,将是人与机器协同进化的全新时代。