适用场景:财务审计、报销核查、税务合规、重复开票检测 技术栈:pdfplumber + pandas + hashlib + openpyxl 输入:./pdf_invoices/ 目录下所有 PDF 电子发票
pip install tabulate pdfplumber pandas openpyxl
获取发票信息代码
import os
import re
import pandas as pd
from pdfplumber import open as pdf_open
def extract_invoice_data(pdf_path):
"""
从单个PDF文件中提取发票数据,使用表格提取和文本提取。
返回基本信息和项目明细列表。
"""
with pdf_open(pdf_path) as pdf:
full_text = ""
tables_data = []
for page in pdf.pages:
page_text = page.extract_text()
if page_text:
full_text += page_text + "\n"
page_tables = page.extract_tables()
for table in page_tables:
tables_data.append(table)
if not tables_data:
return {
'发票号码': 'Unknown',
'购买方': 'Unknown', '购买税号': 'Unknown', '销售方': 'Unknown',
'销售税号': 'Unknown', '合计金额': 'Unknown', '合计税额': 'Unknown',
'价税合计(小写)': 'Unknown', '明细条数': 0
}, [] # 返回空项目列表
# 假设第一个表格包含基本信息(买方卖方)
header_table = tables_data[0] if tables_data else []
buyer_name = "Unknown"
buyer_tax = "Unknown"
seller_name = "Unknown"
seller_tax = "Unknown"
# 查找包含买方/卖方信息的表头行
for row in header_table:
if row and len(row) >= 5:
row_norm = [cell.replace('\n', ' ') if cell else '' for cell in row]
# 买方
if row_norm[0] and ('购' in row_norm[0] or '买' in row_norm[0]):
buyer_str = row_norm[1]
# 名称模式
name_pat = r'名\s*称\s*[::]?\s*([^ :统一]+?)(?=\s*[::]?\s*统一|$)'
name_match = re.search(name_pat, buyer_str)
if name_match:
buyer_name = name_match.group(1).strip()
# 税号
tax_pat = r'统一社会信用代码\s*/?\s*纳税人识别号\s*[::]?\s*([A-Z0-9]{18})'
tax_match = re.search(tax_pat, buyer_str)
if tax_match:
buyer_tax = tax_match.group(1)
# 卖方
if row_norm[3] and ('销' in row_norm[3] or '售' in row_norm[3]):
seller_str = row_norm[4]
name_pat = r'名\s*称\s*[::]?\s*([^ :统一]+?)(?=\s*[::]?\s*统一|$)'
name_match = re.search(name_pat, seller_str)
if name_match:
seller_name = name_match.group(1).strip()
tax_pat = r'统一社会信用代码\s*/?\s*纳税人识别号\s*[::]?\s*([A-Z0-9]{18})'
tax_match = re.search(tax_pat, seller_str)
if tax_match:
seller_tax = tax_match.group(1)
# 从完整文本中提取发票号码
invoice_num_pat = r'发票号码[::]?\s*(\d+)'
invoice_num_match = re.search(invoice_num_pat, full_text)
invoice_num = invoice_num_match.group(1) if invoice_num_match else "Unknown"
# 提取项目明细:使用文本解析
items = []
detail_match = re.search(r'项目名称.*?税 额\s*(.*?)(?=价税合计|合 计|开票人|备注)', full_text, re.DOTALL | re.IGNORECASE)
if detail_match:
details_text = detail_match.group(1).strip()
lines = [line.strip() for line in details_text.split('\n') if line.strip()]
i = 0
while i < len(lines):
line = lines[i]
# 跳过表头
if '项目名称' in line:
i += 1
continue
if '*' in line:
# 尝试完整模式
pat_full = r'\*(.*?)\*\s*(.+?)\s+([A-Z0-9]+)\s+([^\d\s]+)\s+(\d+(?:\.\d+)?)\s+([\d.]+)\s+([\d.]+)\s+(\d+%)\s+([\d.]+)'
match = re.search(pat_full, line)
if match:
category, name, spec, unit, qty, price, amount, taxrate, tax = match.groups()
# 下一行描述添加到名称
desc = name
i += 1
while i < len(lines) and lines[i] and '*' not in lines[i] and not re.match(r'\d{4}|合', lines[i]):
desc += ' ' + lines[i]
i += 1
items.append({
'文件名': os.path.basename(pdf_path),
'发票号码': invoice_num,
'项目名称': category + ' ' + desc.strip(),
'规格型号': spec,
'单位': unit,
'数量': qty,
'单价': price,
'金额': amount,
'税率/征收率': taxrate,
'税额': tax
})
continue
# 尝试调整模式(无规格、单位、数量)
pat_adjust = r'\*(.*?)\*\s*(.+?)\s+(-?[\d.]+)\s+(\d+%)\s+(-?[\d.]+)'
match = re.search(pat_adjust, line)
if match:
category, name, amount, taxrate, tax = match.groups()
# 假设单价=金额
price = amount
i += 1
while i < len(lines) and lines[i] and '*' not in lines[i]:
name += ' ' + lines[i]
i += 1
items.append({
'文件名': os.path.basename(pdf_path),
'发票号码': invoice_num,
'项目名称': category + ' ' + name.strip(),
'规格型号': '',
'单位': '',
'数量': '',
'单价': price,
'金额': amount,
'税率/征收率': taxrate,
'税额': tax
})
continue
i += 1
item_count = len(items)
# 从完整文本中提取合计金额和税额作为后备或主要方法
full_text_norm = re.sub(r'\s+', ' ', full_text)
full_text_norm = full_text_norm.replace(':', ':').replace('(', '(').replace(')', ')')
# 合计金额和税额: "合 计 ¥xx.xx ¥yy.yy"
totals_pat = r'合\s*计\s*[::]?\s*¥?\s*([\d.]+)\s*¥?\s*([\d.]+)'
totals_match = re.search(totals_pat, full_text_norm)
total_amount = f"¥{totals_match.group(1)}" if totals_match else "Unknown"
total_tax = f"¥{totals_match.group(2)}" if totals_match and len(totals_match.groups()) == 2 else "Unknown"
# 如果未找到,在表格中查找
if total_amount == "Unknown":
for row in tables_data[0] if tables_data else []:
if row and any('合 计' in str(cell) for cell in row):
cell_with_totals = next((cell for cell in row if cell and '¥' in str(cell)), None)
if cell_with_totals:
cell_str = str(cell_with_totals).replace('\n', ' ')
amounts = re.findall(r'¥([\d.]+)', cell_str)
if len(amounts) >= 1:
total_amount = f"¥{amounts[0]}"
if len(amounts) >= 2:
total_tax = f"¥{amounts[1]}"
# 价税合计(小写)
price_tax_pat = r'\(小写\)\s*[·¥]?\s*([\d.]+)'
price_tax_match = re.search(price_tax_pat, full_text_norm)
price_tax_total = f"¥{price_tax_match.group(1)}" if price_tax_match else "Unknown"
# 如果未找到,在表格中查找
if price_tax_total == "Unknown":
for row in tables_data[0] if tables_data else []:
if row and any('价税合计' in str(cell) for cell in row):
cell_with_price = next((cell for cell in row if cell and '小写' in str(cell)), None)
if cell_with_price:
cell_str = str(cell_with_price).replace('\n', ' ')
pt_match = re.search(r'\(小写\)\s*[·¥]?\s*([\d.]+)', cell_str)
if pt_match:
price_tax_total = f"¥{pt_match.group(1)}"
# 后备: 如果价税合计未知,从金额+税额计算
if price_tax_total == "Unknown" and total_amount != "Unknown" and total_tax != "Unknown":
try:
amt = float(re.search(r'[\d.]+', total_amount).group())
tx = float(re.search(r'[\d.]+', total_tax).group())
price_tax_total = f"¥{amt + tx:.2f}"
except (ValueError, AttributeError):
pass
basic_info = {
'发票号码': invoice_num,
'购买方': buyer_name,
'购买税号': buyer_tax,
'销售方': seller_name,
'销售税号': seller_tax,
'合计金额': total_amount,
'合计税额': total_tax,
'价税合计(小写)': price_tax_total,
'明细条数': item_count
}
return basic_info, items
def process_folder(folder_path, output_file='output.xlsx'):
"""
处理文件夹中的所有PDF文件,创建DataFrame,基于发票号码去除重复项,
计算价税合计(小写)的总和,并输出到Excel,包括五个工作表:'基本信息' (不包含项目明细的基本信息),
'项目明细' (所有项目详情), '汇总' (无明细的汇总),
'销售明细' (按卖方分组的销售明细),
'重复发票' (重复的发票文件列表)。
"""
basic_data = []
all_items = []
pdf_files = [f for f in os.listdir(folder_path) if f.lower().endswith('.pdf')]
pdf_files.sort()
for filename in pdf_files:
pdf_path = os.path.join(folder_path, filename)
try:
basic_info, items = extract_invoice_data(pdf_path)
basic_info['文件名'] = filename
basic_data.append(basic_info)
all_items.extend(items)
except Exception as e:
print(f"处理 {filename} 时出错: {e}")
basic_data.append({
'文件名': filename,
'发票号码': 'Unknown',
'购买方': f'Error: {str(e)[:50]}', '购买税号': '', '销售方': '',
'销售税号': '', '合计金额': '', '合计税额': '', '价税合计(小写)': '',
'明细条数': 0
})
all_items.append({
'文件名': filename,
'发票号码': 'Unknown',
'项目名称': '', '规格型号': '', '单位': '', '数量': '', '单价': '',
'金额': '', '税率/征收率': '', '税额': ''
})
df_basic = pd.DataFrame(basic_data)
columns_order_basic = ['文件名', '发票号码', '购买方', '购买税号', '销售方', '销售税号', '合计金额', '合计税额', '价税合计(小写)', '明细条数']
df_basic = df_basic.reindex(columns=columns_order_basic)
# 基于'发票号码'去除重复项,保留第一个出现
initial_count = len(df_basic)
# 找出所有重复行(包括第一次和后续)
df_duplicates_mask = df_basic.duplicated(subset=['发票号码'], keep=False)
df_duplicates = df_basic[df_duplicates_mask].copy()
# 只保留重复的部分(排除第一次出现)
df_duplicates = df_duplicates[df_duplicates.duplicated(subset=['发票号码'], keep='first')]
df_basic = df_basic.drop_duplicates(subset=['发票号码'], keep='first')
duplicate_count = initial_count - len(df_basic)
if duplicate_count > 0:
print(f"基于发票号码移除了 {duplicate_count} 个重复发票。")
# 创建重复发票的DataFrame,只包含文件名和发票号码
df_duplicates_list = df_duplicates[['文件名', '发票号码']].copy()
df_duplicates_list = df_duplicates_list.sort_values('发票号码')
else:
# 如果没有重复,创建空DataFrame
df_duplicates_list = pd.DataFrame(columns=['文件名', '发票号码'])
# 创建项目明细DataFrame
df_items = pd.DataFrame(all_items)
columns_order_items = ['文件名', '发票号码', '项目名称', '规格型号', '单位', '数量', '单价', '金额', '税率/征收率', '税额']
df_items = df_items.reindex(columns=columns_order_items)
# 计算价税合计(小写)的总和
def parse_amount(val):
if isinstance(val, str) and val != 'Unknown' and '¥' in val:
try:
return float(re.search(r'[\d.]+', val).group())
except (ValueError, AttributeError):
return 0.0
return 0.0
total_sum = df_basic['价税合计(小写)'].apply(parse_amount).sum()
# 创建汇总DataFrame(无明细,仅总计)
summary_data = {'总价税合计(小写)': [f"¥{total_sum:.2f}"]}
summary_df = pd.DataFrame(summary_data)
# 创建销售明细:按销售方分组,合计价税合计(小写),计数发票
df_numeric = df_basic.copy()
df_numeric['价税合计数值'] = df_numeric['价税合计(小写)'].apply(parse_amount)
sales_group = df_numeric.groupby('销售方').agg({
'价税合计数值': ['sum', 'count']
}).round(2)
sales_group.columns = ['销售总价税合计(小写)', '发票数量']
sales_group = sales_group.reset_index()
sales_group['销售总价税合计(小写)'] = sales_group['销售总价税合计(小写)'].apply(lambda x: f"¥{x}")
# 输出到Excel,包括五个工作表
with pd.ExcelWriter(output_file, engine='openpyxl') as writer:
df_basic.to_excel(writer, sheet_name='基本信息', index=False)
df_items.to_excel(writer, sheet_name='项目明细', index=False)
summary_df.to_excel(writer, sheet_name='汇总', index=False)
sales_group.to_excel(writer, sheet_name='销售明细', index=False)
df_duplicates_list.to_excel(writer, sheet_name='重复发票', index=False)
print(f"数据已导出到 {output_file}")
print(f"总价税合计(小写) 总和: ¥{total_sum:.2f}")
print(f"总项目条数: {len(df_items)}")
print(df_basic.to_markdown(index=False)) # 打印Markdown预览
return df_basic, df_items
# 使用示例:
folder_path = r'./pdf_invoices' # 替换为您的文件夹路径
df_basic, df_items = process_folder(folder_path)
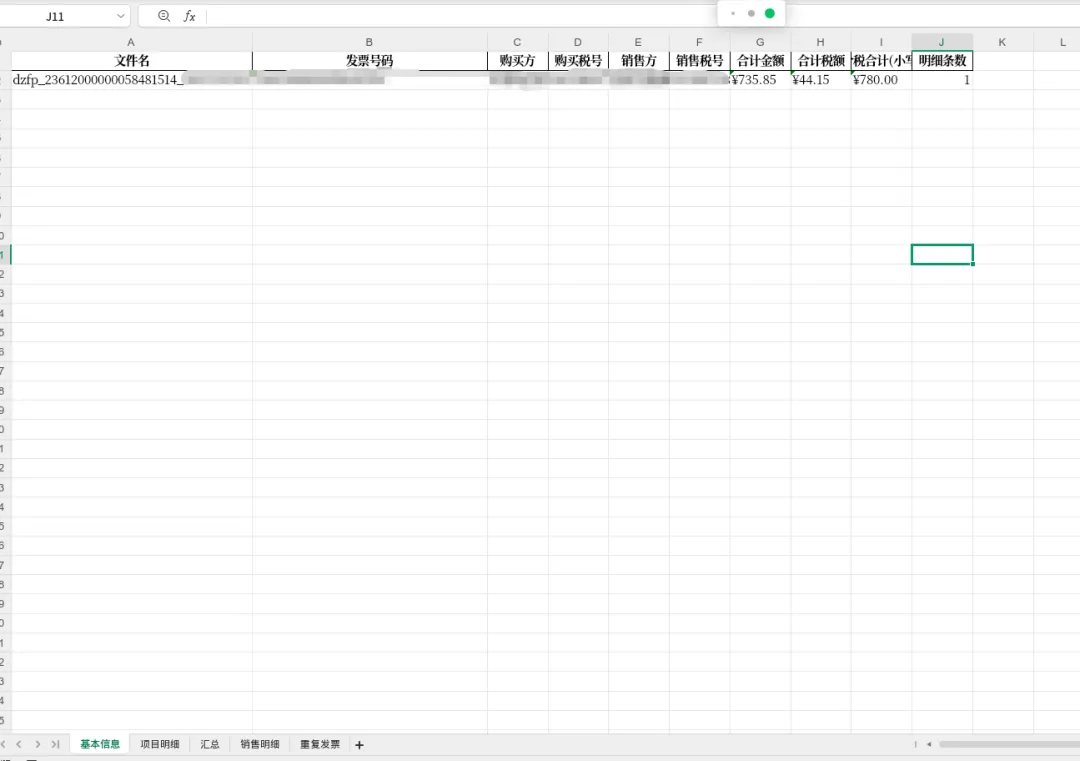
最终效果
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
