Step1:导入所需要的库
import pandas as pd
import glob
import os
pandas:用于处理表格数据
glob:用于查找符合特定规则的文件路径名(比如查找所有以xls结尾的文件)。
os:用于与操作系统交互,比如更改工作文件夹路径。
Step2:设置工作路径
path = r"D:\Users\Python"
os.chdir(path)
path = r"...":定义数据存放路径。前面的字母 r 表示“原始字符串”(Raw String),这样Python就不会把路径里的反斜杠 \ 当作转义字符(比如 \n 是换行),这是Windows路径的标准写法。也可以去掉r,使用/。
os.chdir(path):Change Directory的缩写。让Python将“当前工作目录”切换到指定的文件夹。之后的读取和保存文件操作都会默认在这个文件夹中进行。
Step3:寻找当前目录下所有以 .xls 或 .xlsx 结尾的 Excel 文件
file_pattern = '*.xls*'
file_list = glob.glob(file_pattern)
print(f"共找到 {len(file_list)} 个 Excel 文件,正在处理中...")
melted_dfs = []
file_pattern = '*.xls*':定义搜索规则。* 是通配符,表示任何字符。*.xls* 意味着匹配所有以 .xls 结尾的文件(包括旧版的 .xls 和新版的 .xlsx)。
file_list = glob.glob(file_pattern):执行搜索,将找到的所有文件名存入一个名为 file_list 的列表中。
print(...):在屏幕上打印找到了多少个文件,方便您确认有没有漏掉文件。len(file_list) 计算文件的数量。
melted_dfs = []:创建一个空的列表,就像一个“篮子”,用来装后面处理好的每一张子表格。
Step4:遍历每一个Excel
for file in file_list:
try:
# 读取 Excel 文件的第一个工作表 (sheet_name=0 相当于 Sheet0)
# 如果您的数据在其他工作表,可以修改 sheet_name 的值
df_raw = pd.read_excel(file, sheet_name=0, header=None)
# 步骤A:转置数据,把年份从行名变成列名
df_t = df_raw.T
# 步骤B:将第一行设为列名 (指标, 地区, 频度, 单位, 2000, 2001...)
df_t.columns = df_t.iloc[0]
df_t = df_t[1:]
df_t.columns.name = None
# 步骤C:将年份列融化(melt)成长数据
id_vars = ['指标', '地区', '频度', '单位']
# 检查是否包含必需的列
if all(var in df_t.columns for var in id_vars):
df_melted = pd.melt(df_t, id_vars=id_vars, var_name='年份', value_name='数值')
melted_dfs.append(df_melted)
else:
print(f"跳过文件 {file}:未找到标识列 {id_vars}")
except Exception as e:
print(f"读取文件 {file} 时出错: {e}")
all_data = pd.concat(melted_dfs, ignore_index=True)
==代码详细解读==
df_t = df_raw.T # 转置数据,把年份从行名变成列名
df_t.columns = df_t.iloc[0]
把 df_t 的“第 1 行数据”,设置成“列名”
iloc:按位置取数据
0:第 1 行(Python 从 0 开始)
df_t = df_t[1:]
把第一行去掉,只保留第 2 行及以后的数据
: 是 切片操作
1: 表示 从第 1 行开始,到最后一行
df_t.columns.name = None
删除 DataFrame 列名的名字(name)
if all(var in df_t.columns for var in id_vars):
如果 id_vars 里的每一列,都能在 df_t 的列名中找到
id_vars:希望保留不变的“标识列”
df_t.columns:当前 DataFrame 的所有列名
all(...):所有都满足才返回 True
df_melted = pd.melt(df_t, id_vars=id_vars, var_name='年份', value_name='数值')
pd.melt: 把“多列年份”压缩成两列:年份 + 数值,将宽表转换为长表
id_vars=id_vars:不变的列
var_name='年份':原来列名(2000/2001/2002)变成“年份”这一列
value_name='数值':原来单元格的值,统一放到“数值”列
print(df_melted)
指标 地区 频度 单位 年份 数值
0 GDP 北京 年 亿元 20003328
1 GDP 天津 年 亿元 20001608.4
2 GDP 河北 年 亿元 20004663.7
3 GDP 石家庄 年 万元 20009625186
4 GDP 唐山 年 万元 20008222024
5 GDP 北京 年 亿元 20013935.4
6 GDP 天津 年 亿元 20011778.3
7 GDP 河北 年 亿元 20015107.8
8 GDP 石家庄 年 万元 200110555803
9 GDP 唐山 年 万元 20019849163
10 GDP 北京 年 亿元 20024634.9
11 GDP 天津 年 亿元 20021952.3
12 GDP 河北 年 亿元 20025574.9
13 GDP 石家庄 年 万元 200211646487
14 GDP 唐山 年 万元 200210745437
15 GDP 北京 年 亿元 20035400.1
16 GDP 天津 年 亿元 20032288.7
17 GDP 河北 年 亿元 20036406.6
18 GDP 石家庄 年 万元 200313245121
19 GDP 唐山 年 万元 200311167992
20 GDP 北京 年 亿元 20046424.1
21 GDP 天津 年 亿元 20042663.3
22 GDP 河北 年 亿元 20047683
23 GDP 石家庄 年 万元 200415111521
24 GDP 唐山 年 万元 200414151453
25 GDP 北京 年 亿元 20057327.4
26 GDP 天津 年 亿元 20053203.6
27 GDP 河北 年 亿元 20058886.2
28 GDP 石家庄 年 万元 200516715015
29 GDP 唐山 年 万元 200517413204
30 GDP 北京 年 亿元 20068618.9
31 GDP 天津 年 亿元 20063592.5
32 GDP 河北 年 亿元 200610178.1
33 GDP 石家庄 年 万元 200619025186
34 GDP 唐山 年 万元 200619747534
melted_dfs.append(df_melted)
melted_dfs 是一个 list,用来存每个文件 melt 后的结果
else:
print(f"跳过文件 {file}:未找到标识列 {id_vars}")
如果这个 Excel / DataFrame 里缺少必要的标识列,就不处理它,并打印原因
all_data = pd.concat(melted_dfs, ignore_index=True)
把 melted_dfs 这个列表里的所有 DataFrame,按行“纵向拼接”成一个总的 DataFrame,命名为 all_data
Step5:数据清洗与格式转换
all_data['指标'] = all_data['指标'].astype(str).str.strip()
all_data['地区'] = all_data['地区'].astype(str).str.strip()
all_data['单位'] = all_data['单位'].astype(str).str.strip()
all_data['年份'] = pd.to_numeric(all_data['年份'], errors='coerce')
all_data['数值'] = pd.to_numeric(all_data['数值'], errors='coerce')
all_data = all_data.dropna(subset=['年份', '数值'])
all_data['指标_带单位'] = all_data['指标'] + '(' + all_data['单位'] + ')'
代码解读:
all_data['指标'] = all_data['指标'].astype(str).str.strip()
astype(str):把“指标”这一列强制转成字符串类型
为什么要这么做?
例如:
GDP → "GDP"
NaN → "nan"
123 → "123"
.str.strip():去掉字符串左右两边的空格
例如:
" GDP " → "GDP"
"北京 " → "北京"
" 年" → "年"
all_data['年份'] = pd.to_numeric(all_data['年份'], errors='coerce')
把“年份”这一列强制转换成数值型,凡是转不了的,转成 NaN
errors='coerce':如果转换失败,不报错,直接设为 NaN
比如:
年份 年份
20002000
20012001
年 NaN
频度 NaN
all_data['指标_带单位'] = all_data['指标'] + '(' + all_data['单位'] + ')'
把“指标”和“单位”两列拼在一起,生成一个新列,比如
Step6:数据透视:转置为各变量分列
final_df = all_data.pivot_table(
index=['地区', '年份'],
columns='指标_带单位',
values='数值',
aggfunc='first',
dropna=False# 强制保留所有城市和年份的组合
).reset_index()
以“地区 + 年份”为唯一观测单位,把不同“指标(单位)”展开成多列,每个格子里放对应的数值
pivot_table 用来:重塑数据结构(reshape)
index=['地区', '年份']:这两列 决定“一行是什么”
columns='指标_带单位':决定“展开成哪些列”
比如:
GDP(亿元)
人口(万人)
财政收入(亿元)
# 转换后
GDP(亿元) | 人口(万人) | 财政收入(亿元)
values='数值':表格里真正要填的数值是哪一列
aggfunc='first':如果同一个 地区-年份-指标 有多条记录,取第一条,比如:
加入aggfunc='first'后:
.reset_index():pivot_table 后:地区、年份 会变成 行索引(index)
示例:
pivot前:
pivot后:
Step7:剔除省份数据
由于中经网在下载数据时包含了省级层面的数据(如下图,也可以在下载的时候不选择省份,但是这样还需要自己一个省份一个省份去查找),也可以直接下载,合并后再删除
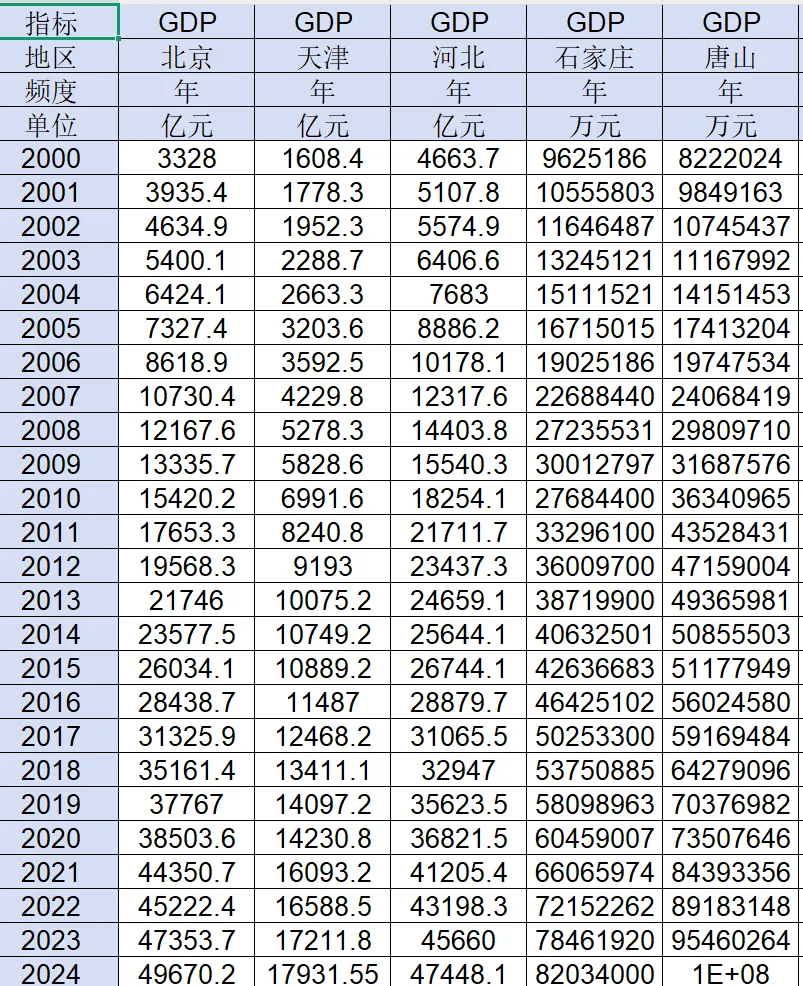
provinces = [
'河北', '山西', '内蒙古', '辽宁', '吉林', '黑龙江',
'江苏', '浙江', '安徽', '福建', '江西', '山东', '河南',
'湖北', '湖南', '广东', '广西', '海南', '四川', '贵州',
'云南', '西藏', '陕西', '甘肃', '青海', '宁夏', '新疆'
]
final_df = final_df[~final_df['地区'].isin(provinces)] # 保留那些“地区”不在 provinces 列表里的行
final_df = final_df.sort_values(by=['地区', '年份']).reset_index(drop=True)
代码解读:
final_df = final_df.sort_values(by=['地区', '年份']).reset_index(drop=True)
先按“地区”排序,同一地区内再按“年份”从小到大排,然后把乱掉的行号重新变成 0,1,2,3……
sort_values(by=['地区', '年份']):先按 地区 排序在同一个地区内部,再按 年份 排序
.reset_index(drop=True):重新生成 index:0,1,2,3……,drop=True 表示:不要把旧 index 作为一列保留下来
dropna=False:可以时每个城市的年份都一样(即平衡面板数据)
Step8:保存结果
output_filename = 'result.csv'
final_df.to_csv(output_filename, index=False, encoding='utf-8-sig')
print(f"合并成功!文件已保存为: {output_filename}")
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
