在 AI 代码生成的赛道上,结构化输出似乎是 “标准答案”—— 工具调用、JSON 格式,这些关键词总与 “精准”“可靠” 绑定。但最新实验却抛出了一个反常识结论:LLMs(大语言模型)在 JSON 中返回代码时,质量会显著下降。哪怕是支持 JSON 专项优化的顶尖模型,也逃不过语法错误激增、解题能力滑坡的困境。这究竟是技术瓶颈,还是我们对 “结构化” 的迷信?今天就来拆解这份来自 aider.chat 的实测报告,看看大模型在 JSON 和代码的 “磨合” 中,到底遇到了什么坎。一、争议焦点:为什么不用 JSON?大模型工具化的核心疑问
用过 AI 写代码的人可能都有过这样的困惑:为什么 aider 这类工具坚持用纯文本格式让模型返回代码修改,而不是用更 “规范” 的 JSON 工具调用?纯文本格式
greeting.py<<<<<<< SEARCHdef greeting():print("Hello")=======def greeting():print("Goodbye")>>>>>>> REPLACE
JSON 格式(工具调用常用)
{ "filename": "greeting.py", "search": "def greeting():\n print(\"Hello\")\n" "replace": "def greeting():\n print(\"Goodbye\")\n"}
从逻辑上看,JSON 格式的优势很明显:结构固定、机器易解析,还能通过 Schema 强制规范输出。尤其是 OpenAI 等厂商近期推出 “严格 JSON 模式”,承诺确保输出语法正确、符合 schema,更让不少人觉得 “JSON 替代纯文本” 是大势所趋。但 aider 团队的核心顾虑是:JSON 的 “壳” 没问题,但里面的 “代码肉” 会不会变质?毕竟代码生成的终极目标不是 “输出合法 JSON”,而是 “输出能解决问题、无 bug 的高质量代码”。这个疑问,催生了这场横跨 4 个顶尖模型、133 个编程任务的实测。二、实验设计:公平对比,直击核心差异
为了精准量化 JSON 对代码质量的影响,实验采用了 “控制变量法”,把复杂变量降到最低:1. 测试对象
4 个当前主流的代码生成模型,覆盖不同厂商和版本:claude-3-5-sonnet-20240620
deepseek-coder(V2 0724)
gpt-4o-2024-05-13
gpt-4o-2024-08-06(支持 OpenAI 最新严格 JSON 模式)
2. 测试任务
133 个来自 Exercism Python 仓库的编程练习,覆盖基础语法、逻辑处理等常见场景,确保测试的通用性。3. 三种输出策略
Markdown 模式:模型用三重反引号包裹完整源代码文件,类似日常 “贴代码” 的习惯;
JSON 模式:模型通过write_file函数调用,在 JSON 中返回完整源代码,包含说明和内容字段;
JSON(严格模式):仅 gpt-4o-2024-08-06 支持,开启 OpenAI 的strict=True参数,强制 JSON 语法合规。
4. 评分标准
每个模型 + 策略组合重复测试 5 次,统计 “代码通过所有测试用例” 的通过率,同时记录语法错误、缩进错误的总数。三、实验结果:JSON 全方位拉胯,没有例外
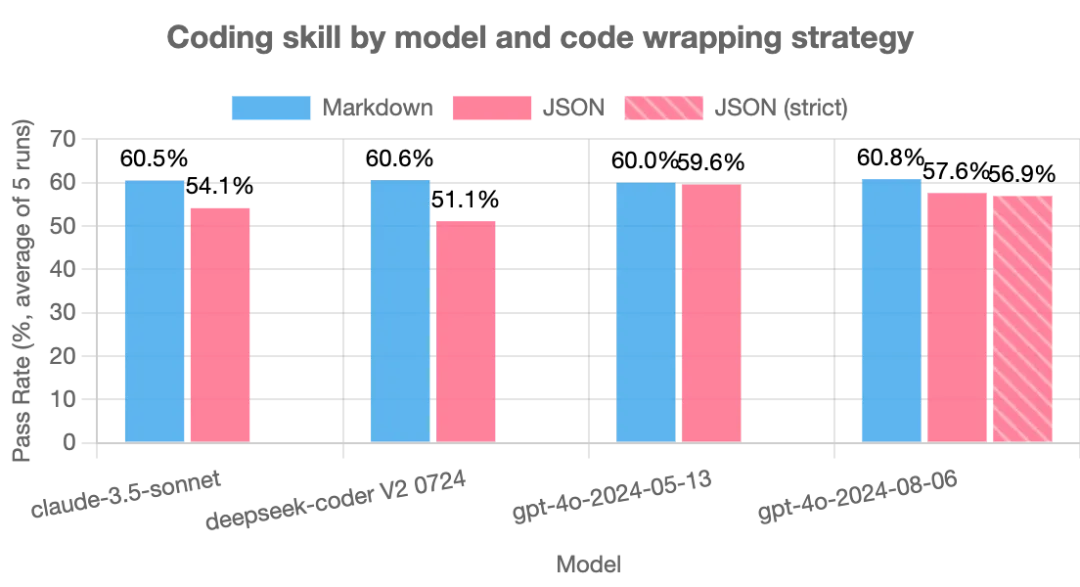
测试结果颠覆了很多人的预期 ——所有模型在 JSON 格式下的表现,都不如纯文本 Markdown,部分模型的差距堪称 “断崖式”。1. 通过率:JSON 模式集体翻车
gpt-4o-2024-05-13 是唯一 “抗造” 的模型,JSON 模式仅比 Markdown 低 0.4%,差距在误差范围内;
其余 3 个模型均出现显著下滑:claude-3-5-sonnet 和 deepseek-coder 的通过率暴跌,JSON 模式远低于 Markdown;
就连支持 “严格 JSON 模式” 的 gpt-4o-2024-08-06,也没逃过颓势 —— 严格模式和普通 JSON 模式的通过率几乎持平,都远低于 Markdown。
简单说:严格 JSON 只能保证 “JSON 本身没语法错”,却救不了里面的代码质量。2. 语法错误:JSON 让模型 “犯低级错”
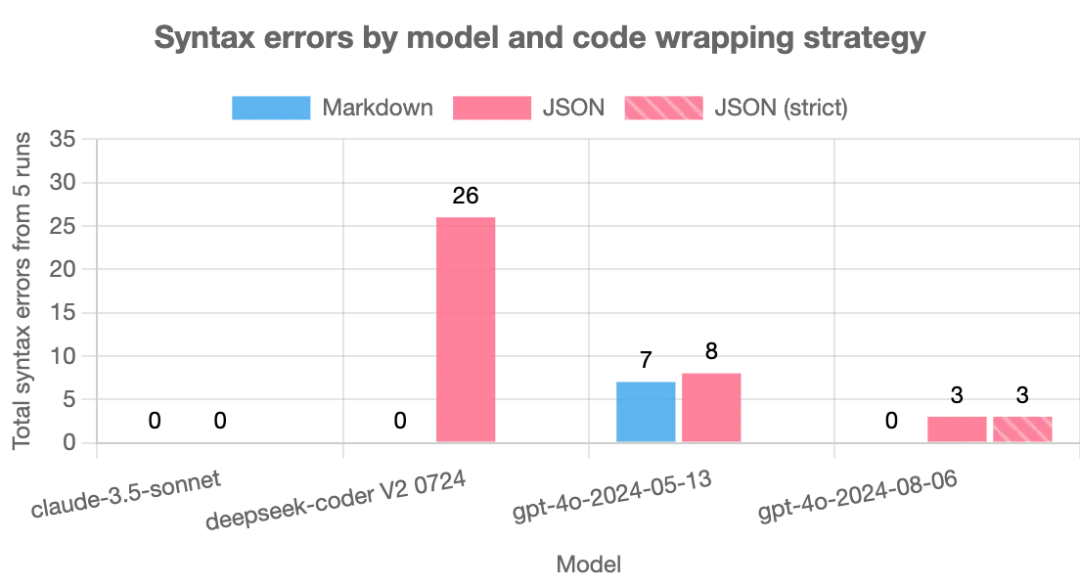
更扎心的是,JSON 格式会让模型出现大量本可避免的语法错误。实验统计了 5 次测试中所有SyntaxError(语法错误)和IndentationError(缩进错误)的总数:所有模型在 JSON 模式下的错误数,都比 Markdown 模式多;
典型错误集中在 “字符串转义” 上 —— 比如模型会混淆 JSON 的转义规则和代码的转义规则,导致代码中的引号无法正确解析。
举个真实案例,gpt-4o-2024-05-13 在 JSON 模式下生成的代码:Traceback (most recent call last): ... File "bottle-song/bottle_song.py", line 9 lyrics.append(f'There'll be {i - 1} green bottles hanging on the wall.') ^SyntaxError: unterminated string literal (detected at line 9)
这行代码直接触发 SyntaxError:字符串里的单引号没有转义,导致解释器认为字符串提前终止。正确的写法需要双重转义:JSON 中要先转义反斜杠(\\),才能让代码最终得到There\'ll:...lyrics.append(f'There\\'ll be {i - 1} green bottles hanging on the wall.')\n...
这种 “JSON 转义 + 代码转义” 的双重负担,让模型频繁 “脑短路”,犯了人类程序员都很少踩的低级错误。3. 超出语法:JSON 让模型 “分心”,影响解题推理
更值得注意的是 claude-3-5-sonnet 的表现:它在 JSON 模式下几乎没犯语法错误,但通过率依然大幅下滑。这说明 JSON 的负面影响不止于 “转义麻烦”——格式化 JSON 的认知负担,会分散模型的注意力,削弱它解决编程问题的推理能力。就像让一个数学家一边解题,一边还要严格遵守复杂的书写格式,思路自然会被打断。四、为什么 JSON 会拖垮代码质量?核心原因有两个
实验结果背后,其实是大模型的 “能力特性” 与 JSON 的 “格式要求” 之间的冲突:1. 转义复杂性:双重规则让模型混淆
代码本身就包含引号、换行等特殊字符,而 JSON 对这些字符有自己的转义规则(比如用\"表示双引号,\n表示换行)。这意味着模型要同时处理两套规则:第一套:代码层面的转义(比如 Python 中用\'转义单引号);
第二套:JSON 层面的转义(比如把代码中的\'再转义为\\')。
这种 “套娃式转义” 远超人类的常规书写习惯,也超出了大模型对 “上下文规则” 的处理极限,自然容易出错。2. 认知负担:格式化消耗推理资源
大模型的 “思考能力” 是有限的 —— 当它需要花精力确保 JSON 结构合规(比如逗号不遗漏、括号成对、转义正确)时,分配给 “理解编程任务、设计解题逻辑、优化代码结构” 的资源就会减少。就像我们用手机打字时,如果同时要注意格式、错别字、标点,就很难流畅表达想法。大模型在 JSON 的 “格式枷锁” 下,也会陷入类似的 “注意力分散”。五、结论与启示:现在还不是 JSON 替代纯文本的时候
这份实验报告(与 2023 年 7 月的类似测试结论一致)给我们一个明确答案:至少目前,纯文本(Markdown)依然是大模型返回代码的最优解。1. 对开发者的启示
不要盲目追求 “结构化输出”:如果核心需求是 “高质量代码”,优先选择 Markdown 等纯文本格式,避免 JSON 的额外负担;
若必须用 JSON:做好双重转义校验,尤其是字符串、换行等特殊字符,必要时通过代码预处理减少模型的转义压力;
理性看待 “严格 JSON 模式”:它能解决 JSON 本身的语法问题,但无法提升代码质量,不能指望靠它 “翻盘”。
2. 对大模型厂商的挑战
OpenAI 等厂商在 JSON 工具化上的进步值得肯定,但实验也说明:让模型兼顾 “结构化格式” 和 “高质量代码”,还需要更深入的优化。未来可能需要专门针对 “代码 + JSON” 的场景训练模型,或者设计更友好的转义机制,降低模型的认知负担。3. 长期展望
结构化输出依然是 AI 工具化的大趋势,但这次实验提醒我们:技术进步需要 “循序渐进”。当大模型的推理能力足够强大,能够轻松应对多重规则约束时,JSON 或许会成为代码输出的主流格式。但在那之前,我们需要尊重模型的 “能力边界”,选择最适合的输出方式。最后:你在使用 AI 写代码时,遇到过 JSON 相关的坑吗?
是转义错误让代码运行失败,还是结构化格式反而降低了效率?欢迎在评论区分享你的经历和解决方案~ 技术的进步,正是在不断发现问题、解决问题中实现的。如果觉得这份实测报告有价值,别忘了点赞、在看,分享给身边的开发者朋友~ 关注我,后续带来更多 AI 技术的深度实测与解读!