SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents
报告原文地址:https://arxiv.org/pdf/2601.16746
概述
这篇报告由上海交通大学和字节跳动团队联合发布,主题是SWE-Pruner——一种专为AI编码代理设计的自适应上下文剪枝框架。核心结论是:SWE-Pruner能显著减少编码代理在处理长代码上下文时的token消耗和交互轮次,同时保持任务性能基本不变。例如,在SWE-Bench Verified基准测试中,token使用量减少23%-38%,交互轮次降低18%-26%,而任务成功率仅下降不到1%。
关键洞察:
任务感知剪枝:SWE-Pruner模仿人类程序员的“选择性浏览”行为,根据当前任务目标(如“聚焦错误处理逻辑”)动态筛选相关代码行,避免传统压缩方法对代码结构的破坏。
轻量高效设计:仅需0.6B参数的轻量级模型,推理延迟低于100毫秒,成本远低于完整LLM的API调用。
多场景通用性:不仅在多轮交互的代理任务中有效,在单轮代码补全和问答任务中也实现了最高14.84倍的压缩比。
一、引言:AI编码代理的“上下文墙”困境
大型语言模型(LLM)在软件工程任务中表现卓越,但从代码理解到交互式代理的演进过程中,一个关键瓶颈凸显:长上下文窗口的限制。尽管已有支持长上下文的模型,但盲目摄入大量代码会导致高昂的推理成本、延迟增加,并引入噪声干扰。现有压缩技术(如LLMLingua)多针对自然语言设计,直接应用于代码时常破坏语法结构或丢失关键细节。
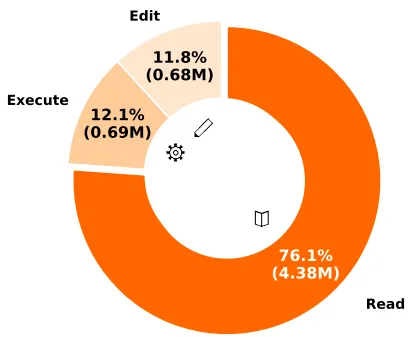
报告指出,编码代理在真实代码库中导航时,76.1%的token消耗用于文件读取操作(如cat、grep),而多轮交互中历史上下文不断累积,进一步加剧资源浪费。
二、动机:为什么需要智能剪枝?
通过对Mini-SWE代理的轨迹分析,研究发现:
这些现象揭示了上下文优化的关键机会:需要一种既能识别任务相关代码、又轻量低延迟的剪枝机制。
三、方法揭秘:SWE-Pruner如何工作?
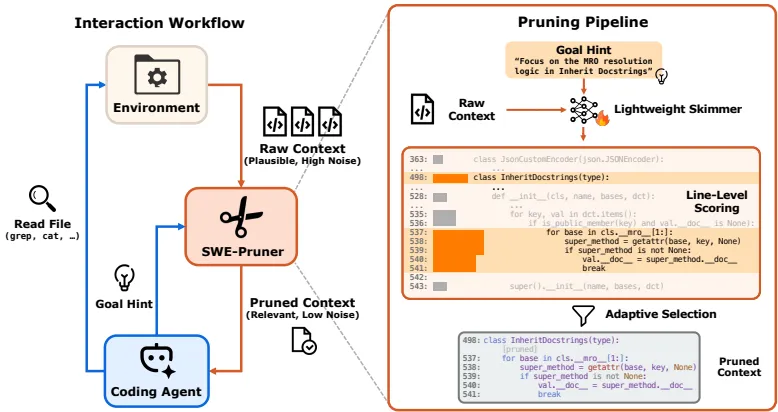
SWE-Pruner的核心设计灵感来自人类程序员的“目标驱动选择性关注”。其工作流程分为三步:
1. 目标提示生成
代理在每次文件读取操作时,生成一个自然语言描述的目标提示(如“认证逻辑如何实现?”),通过新增的context_focus_question参数传递给剪枝器。若未提供提示,则返回完整内容,确保向后兼容。
2. 轻量神经剪枝器
采用仅0.6B参数的Qwen3-Reranker模型,对代码行进行评分和筛选:
3. 无缝集成代理工作流
SWE-Pruner作为中间件嵌入代理与环境之间,拦截原始上下文并返回剪枝后的内容。支持单轮任务(直接使用任务描述作为提示)和多轮任务(动态生成提示)。
四、实验验证:多基准测试中的表现
评估覆盖4类基准任务,对比6种基线方法:
多轮任务结果
表1显示,SWE-Pruner在减少token消耗的同时,成功率与基线几乎持平:
代理配置 | 交互轮次 | 成功率(%) | Token消耗(M) | 成本($) |
|---|
Mini-SWE Agent (Claude) | 51.0 | 70.6 | 0.911 | 0.504 |
+ SWE-Pruner | 41.7 | 70.2 | 0.701 (↓23.1%) | 0.369 (↓26.8%) |
在SWE-QA中,token减少幅度达29%-54%(表2)。值得注意的是,剪枝后代理决策更果断,减少了探索性操作。
单轮任务结果
表4显示,在8倍压缩约束下,SWE-Pruner在代码补全任务中保持57.58的编辑相似度(基线仅48.67),在代码问答中准确率达58.71%,压缩比高达14.84倍,显著优于检索或摘要类方法。
五、效率与实用性分析
延迟与成本优势
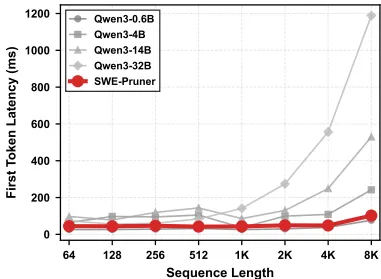
SWE-Pruner的轻量设计使其在8192 token输入下延迟仅102毫秒(图3),而Qwen3-32B模型延迟超1200毫秒。剪枝开销仅占API调用成本的10%,但token减少带来的节省可覆盖此成本。
案例研究
六、结论总结
SWE-Pruner通过任务感知的行级剪枝,解决了编码代理的上下文管理痛点。其优势在于:
动态适应性:根据代理目标动态过滤代码,而非静态压缩。
结构保持:行级粒度维护代码语法完整性,AST正确率达87.3%(token级方法仅0.29%)。
广泛适用性:从多轮交互到单轮理解任务,均实现显著效率提升。
未来工作可扩展至多语言代码库,并进一步优化延迟。对于AI开发者而言,SWE-Pruner提供了一种低成本、高效益的上下文优化思路,尤其适合资源受限的实时应用场景。