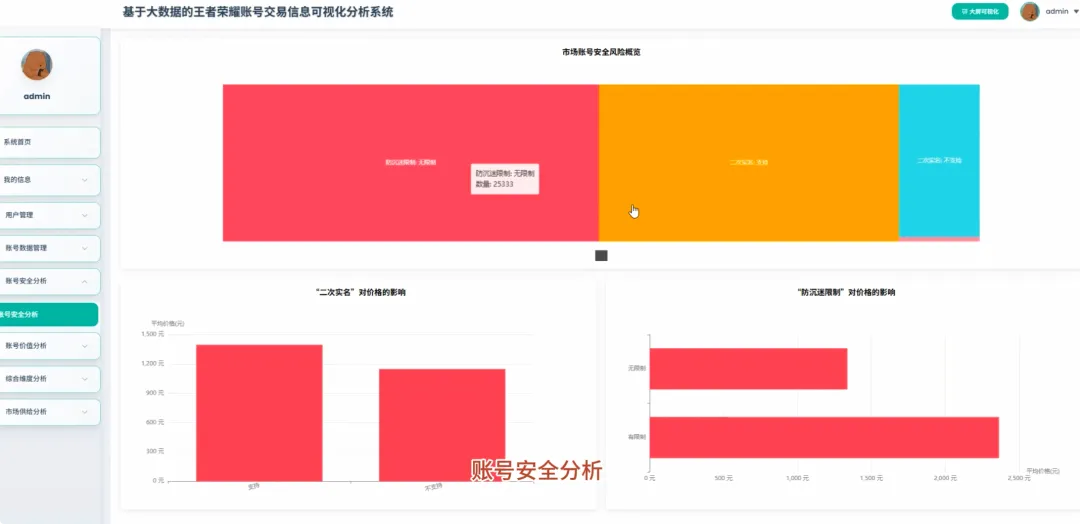
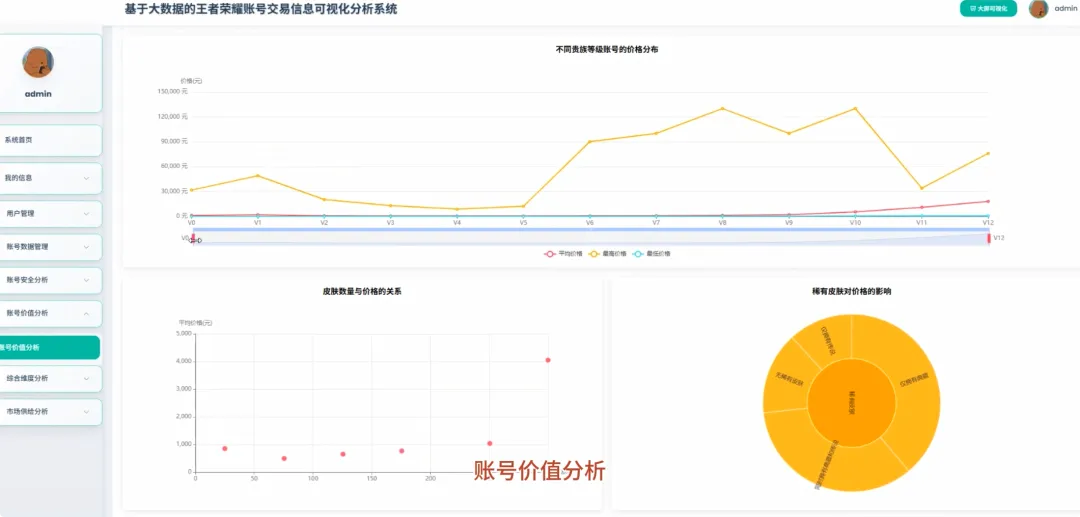
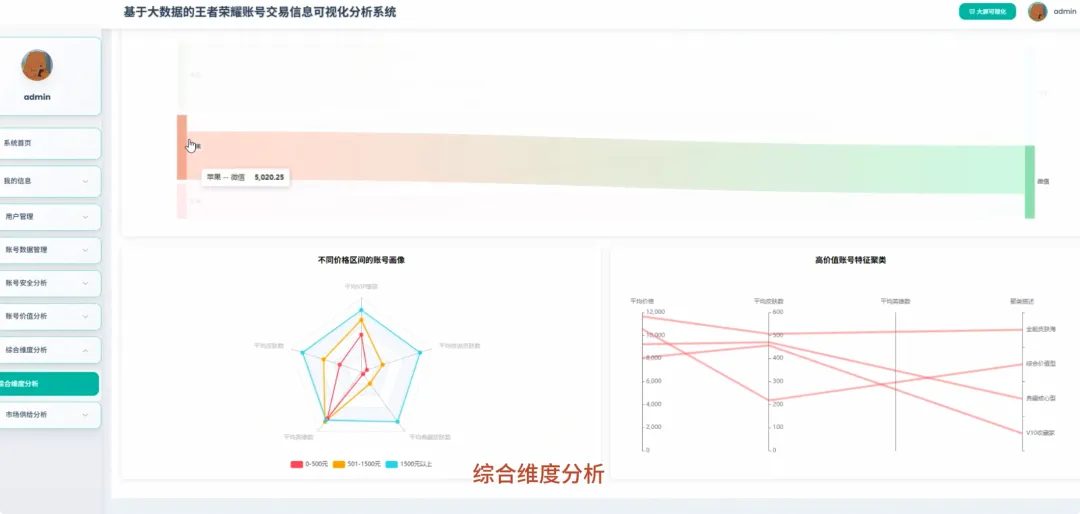
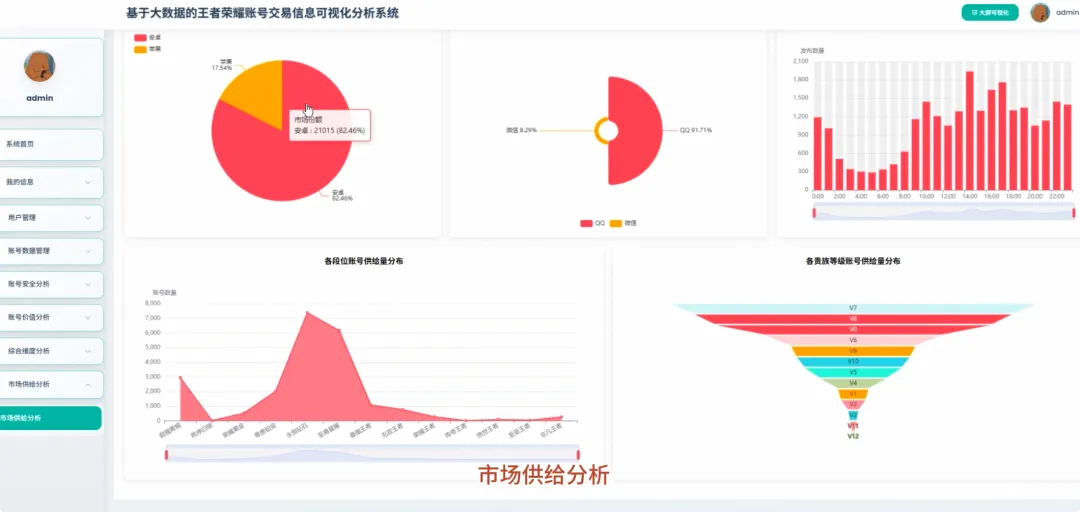
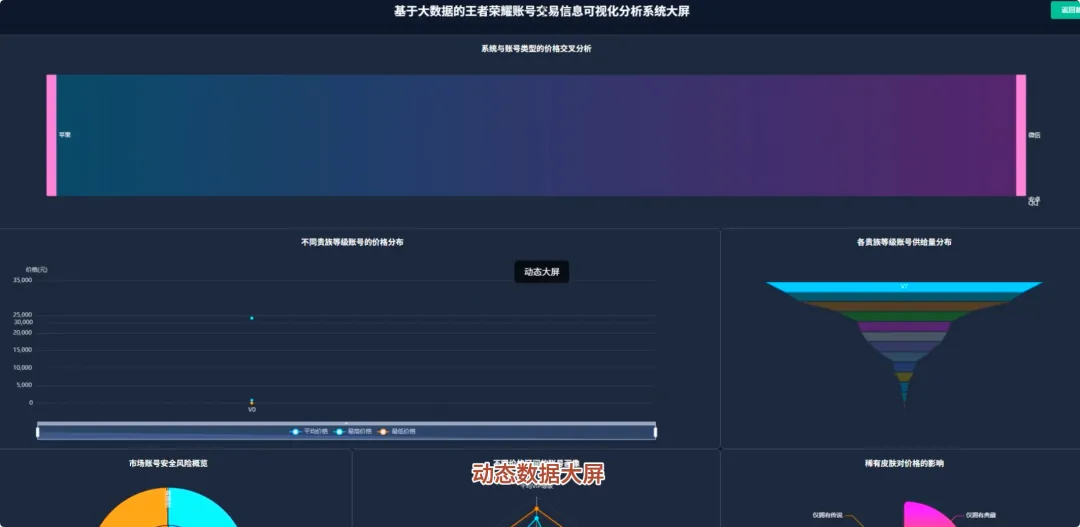
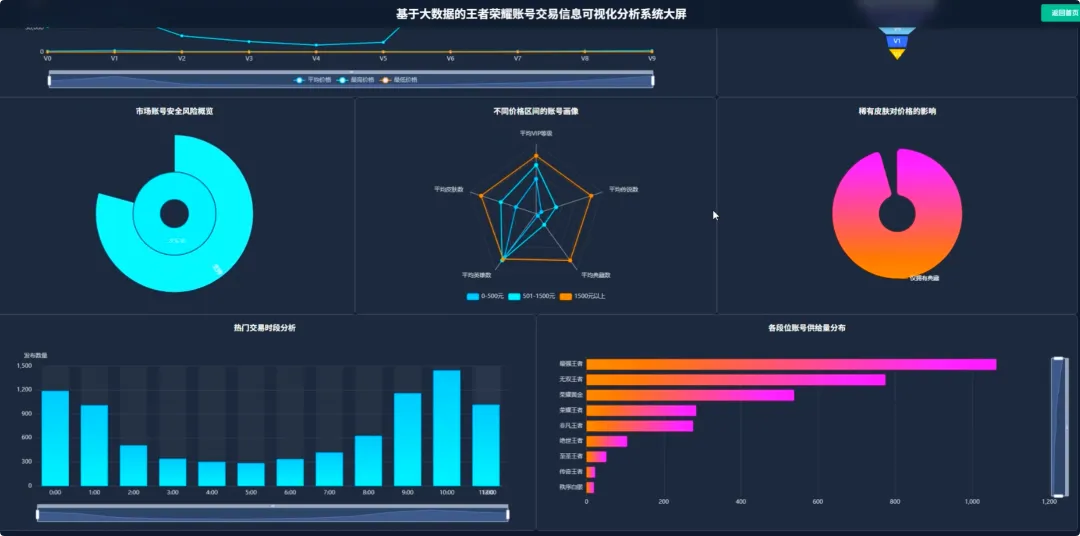
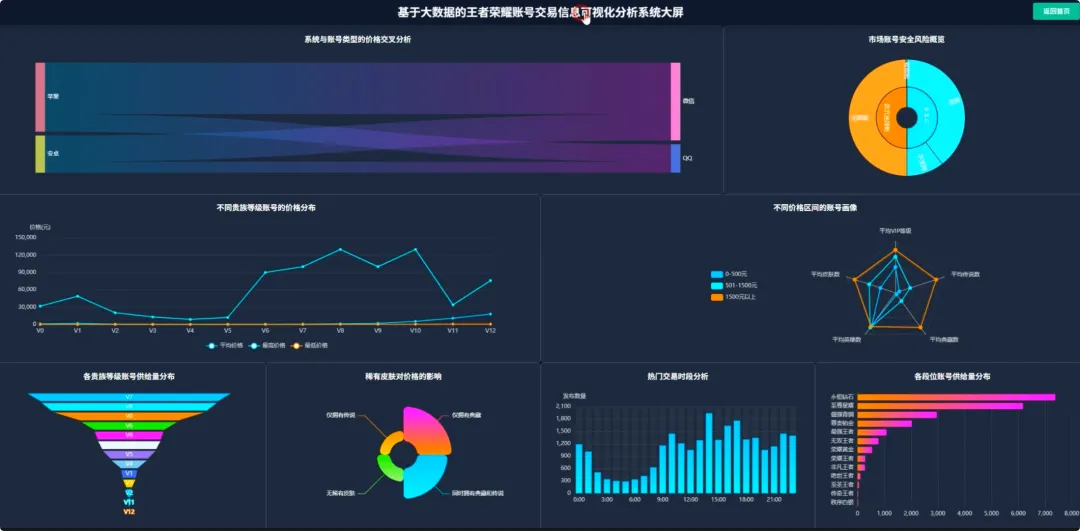
spark = SparkSession.builder.appName("HonorOfKingsAnalysis").getOrCreate()def analyze_vip_price(df): avg_price_df = df.groupBy("vip_level").agg(F.avg("price").alias("avg_price"), F.max("price").alias("max_price"), F.min("price").alias("min_price"), F.count("price").alias("count")) avg_price_df = avg_price_df.withColumn("vip_level", F.col("vip_level").cast("int")) avg_price_df = avg_price_df.orderBy("vip_level") window_spec = Window.orderBy(F.col("avg_price").desc()) avg_price_df = avg_price_df.withColumn("rank", F.rank().over(window_spec)) final_df = avg_price_df.select("vip_level", "avg_price", "max_price", "min_price", "count", "rank") return final_dfdef cluster_high_value_accounts(df): quantile_price = df.approxQuantile("price", [0.95], 0.01)[0] high_value_df = df.filter(F.col("price") > quantile_price) feature_cols = ["skin_count", "vip_level", "glory_collection_skin_count", "legendary_skin_count"] assembler = VectorAssembler(inputCols=feature_cols, outputCol="features") feature_data = assembler.transform(high_value_df) scaler = StandardScaler(inputCol="features", outputCol="scaled_features", withStd=True, withMean=True) scaler_model = scaler.fit(feature_data) scaled_data = scaler_model.transform(feature_data) kmeans = KMeans(featuresCol="scaled_features", predictionCol="cluster", k=3, seed=42) model = kmeans.fit(scaled_data) clustered_df = model.transform(scaled_data) result_df = clustered_df.select("price", "skin_count", "vip_level", "cluster") return result_dfdef analyze_rank_distribution(df): rank_distribution_df = df.groupBy("rank").agg(F.count("rank").alias("account_count")) rank_distribution_df = rank_distribution_df.orderBy(F.col("account_count").desc()) total_count = df.count() rank_distribution_df = rank_distribution_df.withColumn("percentage", (F.col("account_count") / total_count) * 100) rank_mapping = {"青铜": 1, "白银": 2, "黄金": 3, "铂金": 4, "钻石": 5, "星耀": 6, "王者": 7} mapping_expr = F.create_map([F.lit(x) for x insum(rank_mapping.items(), ())]) rank_distribution_df = rank_distribution_df.withColumn("rank_order", mapping_expr.getItem(F.col("rank"))) rank_distribution_df = rank_distribution_df.na.fill(0, subset=["rank_order"]) final_rank_df = rank_distribution_df.orderBy(F.col("rank_order").asc()) return final_rank_df