导语
你是否经历过这样的 AI 编程场景:最开始,几个 Prompt 下去代码跑得飞快,你感觉自己像个"神"。但三天后,随着功能叠加,AI 开始"失忆",生成的代码前后矛盾,修复一个 Bug 却引入两个新 Bug。你不得不花费大量时间向 AI 解释上下文,或者干脆重写。
这就是典型的"氛围编码"(Vibe Coding)后遗症——速度有了,但工程死掉了。
业内甚至有个说法叫"Vibe Coding 宿醉":你用 AI 快速搭建了原型,第二天醒来发现仓库里堆满了意大利面代码、不一致的架构模式,以及滚雪球般膨胀的技术债务。随着 AI 模型的上下文窗口在长会话中逐渐退化,没有持久规范锚定的 Agent 就会开始"失去主线",做出偏离原始意图的推测。
在 AI 辅助编程日益普及的今天,如何让 AI 输出可控、可维护、可协作的代码?答案就是 规范驱动开发(SDD)。它不再把 AI 当作一个随机的聊天伴侣,而是通过严谨的契约,将其转化为高效的执行工兵。
一、什么是 SDD
一句话定义
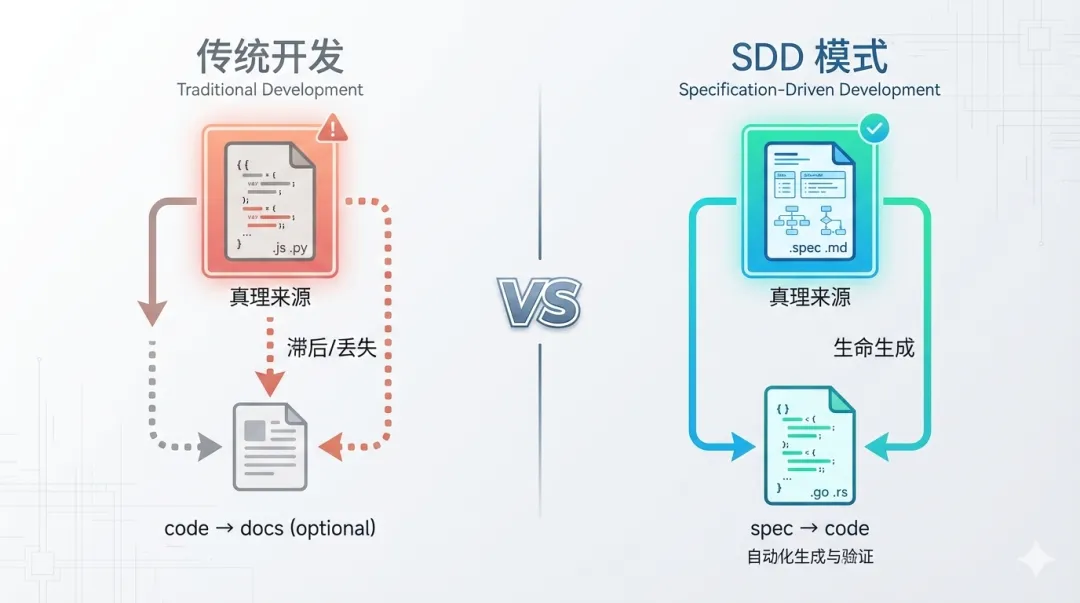
SDD(Specification-Driven Development) 是一种将"结构化规范"(Spec)作为系统单一事实来源(Single Source of Truth, SSOT) 的开发范式,代码仅仅是规范的一种"可执行产物"。
用一个比喻:如果传统开发是"边画边想"的自由创作,SDD 就是"先画设计图,再按图施工"的工程化方法。
核心区别
规范 ≠ 传统文档
在 SDD 语境下,"Spec" 不是指传统的 Word 文档,而是 机器可读、结构化的 Markdown 或 YAML 文件(如 spec.md、plan.md、openapi.yaml)。
与传统文档的本质区别:
- Spec 更像"半代码化的契约":字段、接口、约束、用例、场景都可以被工具解析和执行
二、为什么 SDD 现在火了?
AI 时代的结构性困境
在 AI 编程时代(特别是 2025-2026 年),代码生成的边际成本趋近于零,但 上下文维护成本 急剧上升。
问题的根源在于:
- 如果缺乏明确的"锚点",LLM 容易产生幻觉或漂移
- 多人+多 Agent 并行时,代码冲突无法通过 Merge 解决
SDD 的解决方案:通过提供持久化的、结构化的上下文(Context),强迫 AI 在编码前先"思考"和"确认",从而解决"氛围编码"带来的不可维护性问题。
从理论到主流
SDD 的思想渊源可追溯到形式化方法的早期探索:
- 2004年:微软研究院推出 Spec# 系统,试图通过增强的编程语言和静态验证器编写"无缺陷程序"
- 2024-2025年:生成式 AI 爆发,SDD 从理论探索进入工程实践
- 2025年9月:GitHub 发布 Spec Kit,SDD 发展史上的重要里程碑,短短几个月内获得超过 50,000 星标
到 2025 年底,SDD 已巩固其地位,成为将 AI 集成到敏捷工程中的事实标准,尤其在可靠性和可维护性不可妥协的企业环境中。
三、为什么要用 SDD:四大核心收益
1. 质量:消灭"幻觉"与过度设计
收益:通过"宪法"(Constitution)文件设定不可协商的原则(如"必须先写测试"),强制 AI 遵守工程底线。
数据支撑:
最小动作:在项目根目录创建一个 constitution.md,写下 3 条铁律(例如:禁止引入新库、所有 API 需有错误处理),并在 Prompt 中引用它。
2. 效率:减少无效返工
收益:数据显示,SDD 能将需求变更响应速度提升 58%,因为在写代码前,AI 已经通过 Spec 与人类对齐了意图。
最小动作:使用 /plan 指令让 AI 先输出技术方案,人工确认无误后再执行 /implement。
3. 协作:打破"单人单机"孤岛
收益:
- Spec 成为人类与 AI、人类与人类协作的通用语言
- 新成员(或新的 AI Agent)阅读 Spec 即可理解架构,无需扒代码
最小动作:将 Spec 文件提交到 Git 仓库,作为 Code Review 的一部分。
4. 风险:可追溯与合规
收益:每一行代码都能追溯到具体的 Spec 条目,满足审计要求。
企业案例:摩根大通技术团队使用 SDD 改造了 200 万行代码的遗留系统,比传统重构模式节省了 40% 的时间,且实现了零业务中断。
最小动作:要求 AI 在生成代码的注释中引用 Spec 的章节 ID。
四、什么情况下"必须"用 SDD?
如果你的团队符合以下 任一 条件,建议强制引入 SDD:
触发条件与起步动作
| | |
|---|
| 多人+多Agent并行开发 | 多个开发者同时使用 AI 修改代码,没有 Spec 作为锚点,代码冲突将无法通过 Merge 解决 | 使用 CCPM 或 Git worktrees 隔离开发环境 |
| 核心业务逻辑复杂 | 口头 Prompt 无法覆盖所有边缘情况(Edge Cases) | 用 Gherkin 语法(Given/When/Then)描述核心逻辑 |
| 遗留系统重构 | 没人敢改的老代码,需要 AI 先生成 Spec 进行"考古",确认逻辑后再重构 | 使用 oh-my-opencode 的 Librarian 角色先分析代码库 |
| 合规性要求高 | | 在 constitution.md 中写入安全红线 |
| 交付节奏快且变更多 | 需要快速验证多个技术方案(例如对比 Rust vs Go 实现) | 基于同一份 Spec,让 AI 生成两个版本的 plan.md 进行对比 |
| 团队存在"Prompt 依赖" | 代码质量完全取决于提问者的 Prompt 水平,质量参差不齐 | 使用固定的 SDD 模板(Spec Template)统一输入格式 |
五、SDD 的三个实现层次
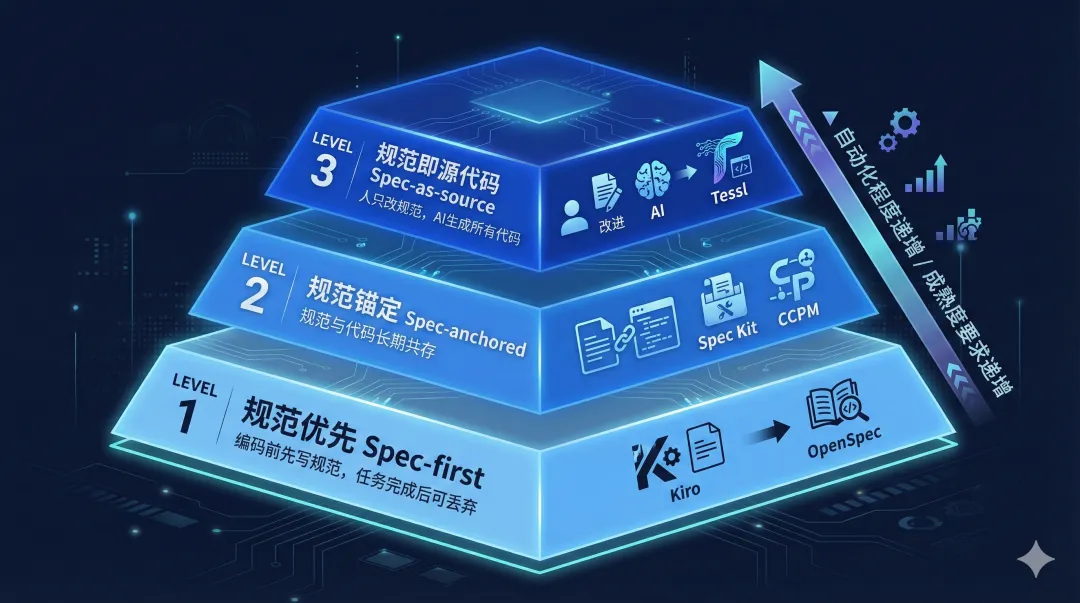
SDD 包含三个递进的实现层次,你可以根据项目成熟度逐步升级:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line┌─────────────────────────────────────────────────────────────┐│ Level 3: 规范即源代码 ││ (Spec-as-source) ││ 规范是唯一真理源,人只改规范,AI生成所有代码 ││ 代表工具:Tessl Framework │├─────────────────────────────────────────────────────────────┤│ Level 2: 规范锚定 ││ (Spec-anchored) ││ 规范与代码长期共存,重构时可反复使用 ││ 代表工具:Spec Kit, CCPM │├─────────────────────────────────────────────────────────────┤│ Level 1: 规范优先 ││ (Spec-first) ││ 编码前先写规范,任务完成后可丢弃 ││ 代表工具:Kiro, OpenSpec │└─────────────────────────────────────────────────────────────┘ ▲ 自动化程度递增 / 成熟度要求递增 ▲
推荐路径:从 Level 1 起步,验证收益后逐步向 Level 2 演进。Level 3 目前仍属前沿探索。
六、主流项目生态地图
我们将当前的 SDD 生态分为五个层次:
| | |
|---|
| A. 规范/Spec 工作流框架 | | |
| B. 项目管理与可追溯 | | |
| C. 多代理执行与调度 | | |
| D. 工程纪律与质量门禁 | | |
| E. 能力插件/工具封装 | | |
1. GitHub Spec Kit:企业级规范治理首选
基本信息
定位:技术中立的 SDD 工具包,覆盖 Constitution → Specify → Plan → Tasks → Implement → PR 全流程。
核心机制:宪法(Constitution)
Spec Kit 最独特的设计是"宪法机制"——定义项目不可变更的高层原则,强制所有后续开发遵循统一标准。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(line# 项目宪法示例/speckit.constitutionThis project follows a "Library-First" approach.All features must be implemented as standalone libraries first.We use TDD strictly.We prefer functional programming patterns.
五大核心命令
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line/speckit.constitution → 定义项目"宪法"(不可变原则) ↓/speckit.specify → 创建功能规范(做什么、为什么) ↓/speckit.clarify → 澄清需求歧义 ↓/speckit.plan → 制定技术方案 ↓/speckit.tasks → 生成可执行任务列表
适用场景
注意事项:流程较为严格,可能给人一种"重回瀑布流"的感觉,但对质量保障极佳。
2. OpenSpec:存量项目迭代神器
定位:轻量级、迭代式的 SDD 框架,强调"变更即 Spec"。
核心理念:
- 用统一的 Schema(JSON/YAML)描述任务目标、可用工具、输入输出结构、成功条件
- 不需要 API Key(使用你现有的 AI 助手)
工作流程
ounter(line起草变更提案 → 审核对齐 → 实现任务 → 归档更新规范
适用场景
- 存量项目(Brownfield)的增量功能开发(1 → N)
上手方式
ounter(lineounter(linenpm install -g @fission-ai/openspecopenspec init
3. BMAD-METHOD:多角色协作的敏捷框架
定位:通用的 AI 代理框架与方法论,引入 21 个专门的 Agent 角色。
核心理念:Agentic Agile Driven Development
- 将敏捷开发中的需求拆分、迭代、回顾等环节,交给一组协同工作的 AI 代理执行
与 SDD 的关系
- BMAD 侧重"如何让一群 Agent 协同完成复杂项目"
- SDD 侧重"这群 Agent 围绕什么契约工作"
- 结合时:Spec 成为多 Agent 协作的共同语言,BMAD 提供具体协作模式
适用场景
- 需要多角色协作(产品经理、架构师、Scrum Master)的复杂项目
上手方式
ounter(linenpx bmad-method install
4. Oh My OpenCode:死磕到底的执行力
定位:OpenCode 的增强插件,主打"西西弗斯"(Sisyphus)代理——死磕到底的执行力。
核心机制:Sisyphus 主代理
角色分工
| |
|---|
| Sisyphus | |
| Oracle | |
| Librarian | |
| Explore | |
| Frontend UI/UX Engineer | |
核心特性:Ultrawork(ulw)模式
- 可以并行启动后台 Agent 进行代码库扫描和文档阅读
适用场景
- 需要 AI 长时间、自主完成复杂任务(如大规模重构、Lint 修复)
5. CCPM:基于 GitHub 的并行开发管理
定位:基于 GitHub Issues 和 Git worktrees 的并行开发管理系统。
核心理念
把「PRD → Epic → Issues → Code」这一整条链路自动化,并让 Spec 在其中形成闭环。
架构设计
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(linePRD(产品需求文档) ↓Epic(技术方案/设计说明) ↓Issues(任务拆分)——利用 Git worktrees 让多个 Agent 在不同分支并行工作 ↓Code(生产代码与测试) ↓PR Review → Merge
核心原则:强调"No Vibe Coding",每一行代码必须可追溯到 Spec。
适用场景
上手方式
ounter(lineounter(linegit clone [仓库] .claude/pm:init
6. Superpowers:强制执行工程纪律
定位:为 AI 编码助手赋予"工程技能"的框架,强制执行最佳实践。
核心特性
- 包含一套强制的红-绿-重构循环(Red-Green-Refactor)技能
适用场景
上手方式
ounter(line/plugin install superpowers
7. Amazon Kiro:AI 原生 IDE
基本信息
定位:AI 原生集成开发环境,内置 SDD 工作流。
核心理念:"从氛围编程到可行代码"
三阶段工作流
ounter(lineRequirements(需求)→ Design(设计)→ Tasks(任务)
独特功能
| |
|---|
| Agent Hooks | 基于文件事件触发自动化(保存时运行测试、提交前安全扫描) |
| 一键回滚 | |
| MCP 集成 | |
| 多模态输入 | 可上传 UI 截图或架构图,Kiro 能解读并据此指导编码 |
适用场景
七、工具选型速查表
按场景选择
| | |
|---|
| | |
| Oh My OpenCode + OpenSpec | |
| | |
| | |
| | |
综合评估矩阵
八、组合落地建议
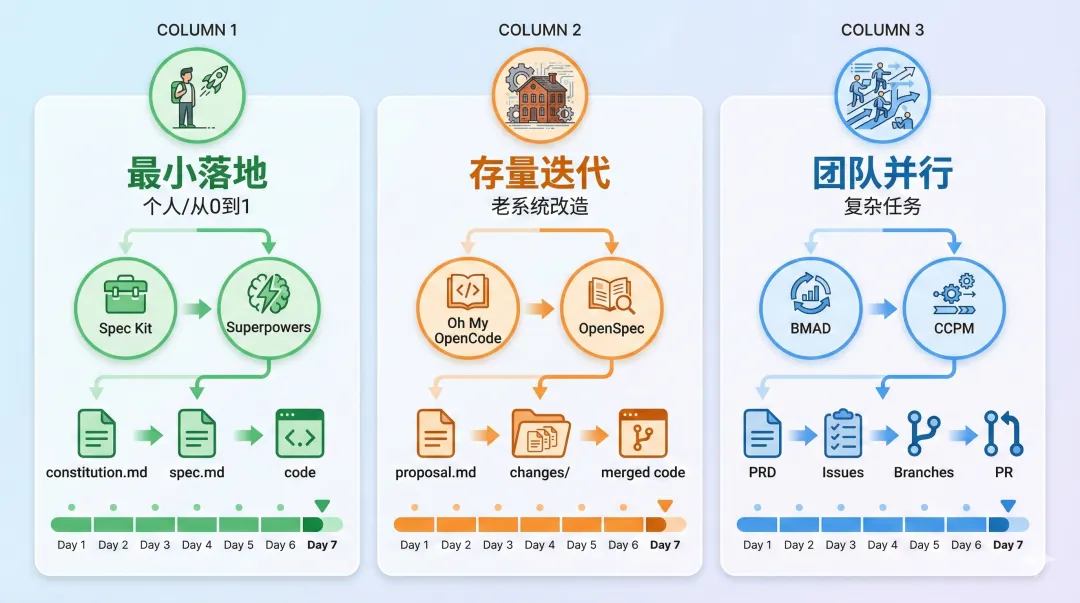
组合 1:最小落地(个人/从 0 到 1)
工具组合:Spec Kit + Superpowers
产出链路:constitution.md → spec.md → 代码
7天起步计划
| |
|---|
| |
| |
| |
| |
| |
| 用 Superpowers 的 TDD 模式执行第一个任务 |
| |
组合 2:存量项目迭代(老系统改造)
工具组合:Oh My OpenCode + OpenSpec
产出链路:proposal.md → changes/ 目录 → 合并后的代码
7天起步计划
| |
|---|
| 安装 OpenCode 和 Oh My OpenCode |
| 使用 "Librarian" Agent 扫描现有代码库,生成上下文地图 |
| 用 OpenSpec 初始化项目,创建 openspec/project.md |
| 针对一个 Bug 或小需求,运行 /opsx:new 创建提案 |
| 使用 "Sisyphus" Agent 执行变更(Ultrawork 模式) |
| 验证修改,运行 /opsx:archive 归档变更 |
| |
组合 3:多代理并行团队化(复杂任务)
工具组合:BMAD + CCPM
产出链路:PRD (BMAD) → GitHub Issues (CCPM) → 并行分支 → PR
7天起步计划
| |
|---|
| |
| 用 BMAD 的 Product Manager Agent 生成详细 PRD |
| 用 BMAD 的 Architect Agent 生成架构设计 |
| 将设计导入 CCPM,运行 /pm:epic-decompose 拆解为 Issues |
| 运行 /pm:epic-sync 同步到 GitHub |
| 启动多个 Agent 并行领取 Issues(API Agent 做后端,UI Agent 做前端) |
| 在 GitHub 上进行 Code Review,合并代码 |
九、挑战与未来展望
当前挑战
1. "Markdown 疲劳"问题
部分 SDD 工作流可能产生大量 Markdown 文件,人工审阅变得繁琐。如果规范不能真正"可执行"或转化为存根代码,可能只是提供了"虚假的控制感"。
2. 可复现性挑战
由于 LLM 是概率性的,即使是定义良好的规范也可能在不同会话或模型间产生不同的实现。行业正在向更正式的规范语言(如 OpenAPI、Gherkin)发展,以实现程序化验证。
3. 棕地集成困难
虽然 SDD 对"绿地"(从零开始)项目非常有效,但将其改造到现有"棕地"代码库要困难得多。现有的技术债务和未明说的架构规则使得 Agent 难以在没有大量人工干预的情况下为遗留系统生成准确的规范。
未来趋势
人类角色的演变:从"编码者"到"上下文工程师"
随着 AI Agent 接管代码执行,人类角色正在演变为架构师或"上下文工程师"(Context Engineer):
- 代码审查转向关注架构契合度和与宪法的对齐,而非语法和风格
十、今天就能做的 3 件事
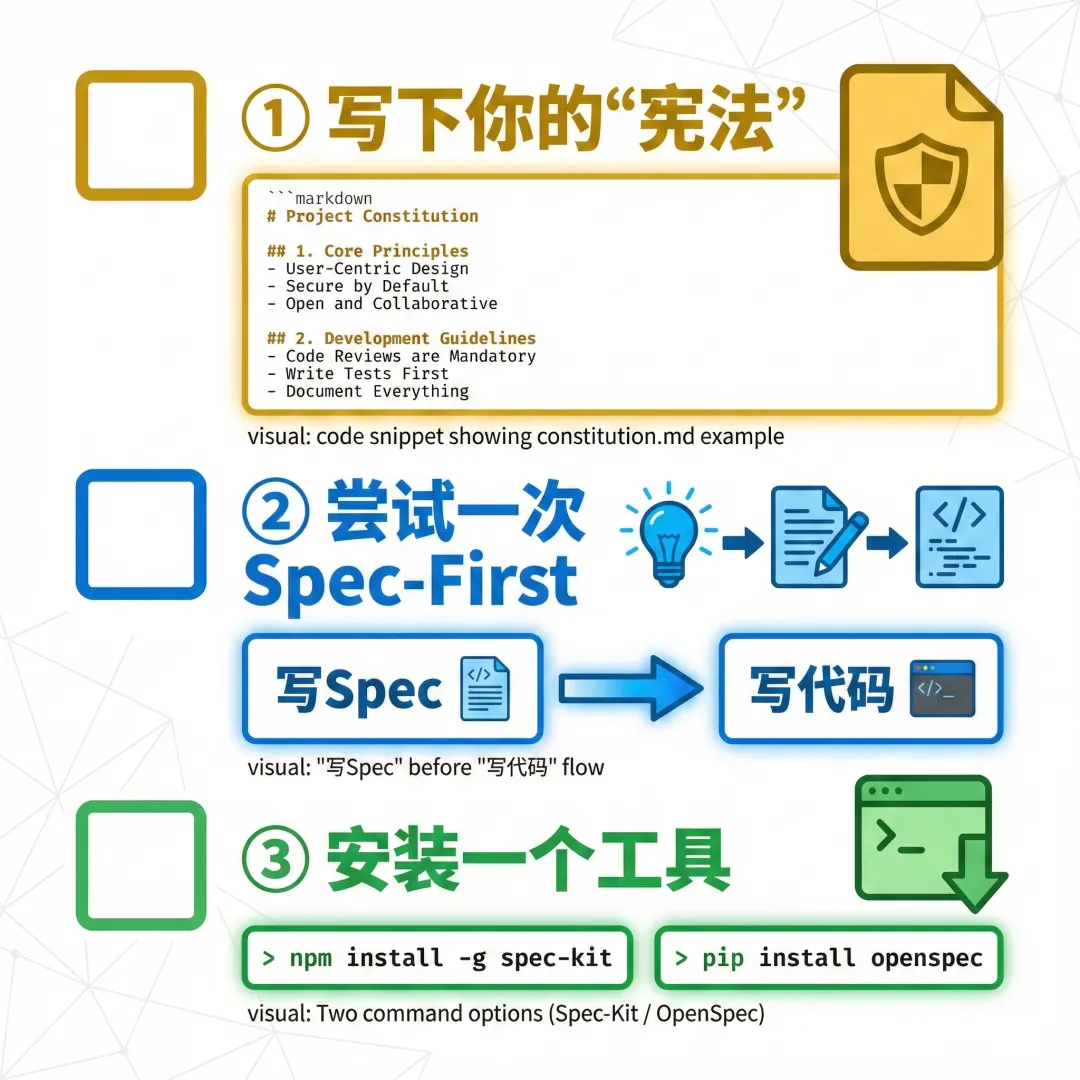
1. 写下你的"宪法"
在项目根目录新建 CLAUDE.md 或 constitution.md,写下 3 条不可动摇的编码原则。
ounter(lineounter(lineounter(lineounter(lineounter(line# 项目宪法1. 所有日期处理必须用 `date-fns`,禁止使用 `moment.js`2. 禁止使用 `any` 类型,必须定义明确的 TypeScript 类型3. 所有 API 接口必须有错误处理和输入验证
2. 尝试一次 Spec-First
下次写代码前,不要直接让 AI "写一个贪吃蛇",而是:
"写一份贪吃蛇的 Spec,包含数据结构和核心逻辑"
确认 Spec 后再让它写代码。
3. 安装一个工具
根据你的场景选择:
- 新项目:
uvx specify init <PROJECT_NAME> (Spec-Kit) - 老项目:
npm install -g @fission-ai/openspec && openspec init (OpenSpec)
附录:术语表
| |
|---|
| SDD | Specification-Driven Development,规范驱动开发 |
| Spec | 结构化的、机器可读的规范文件(如 spec.md) |
| SSOT | Single Source of Truth,单一事实来源 |
| Constitution | |
| Agent | |
| Worktree | |
| Brownfield | |
| Greenfield | |
参考资料
官方仓库
- GitHub Spec Kit: github.com/github/spec-kit
- OpenSpec: github.com/Fission-AI/OpenSpec
- BMAD-METHOD: github.com/bmad-code-org/BMAD-METHOD
- Oh My OpenCode: github.com/code-yeongyu/oh-my-opencode
- CCPM: github.com/automazeio/ccpm
- Superpowers: github.com/obra/superpowers
延伸阅读
- Spec-Kit 中文整理:github.com/888888888881/spec-kit-chinese
- Martin Fowler - Exploring Gen AI: martinfowler.com/articles/exploring-gen-ai
- AWS Kiro 博客:aws.amazon.com/cn/blogs/china
本文基于对 GitHub 主流 SDD 仓库的深度调研整理而成。如有疏漏欢迎指正交流。