了解 Codon 如何通过 AOT compilation 实现 100x 的 Python 提速。原生 multithreading、GPU kernels、零开销。
作为一个花了无数小时等待 ML 训练作业结束、看着 NumPy 在庞大的医学影像数据集上像蜗牛一样爬、折腾怎么也跑不快的 Python 代码的人,我经历过太多“Python 太慢了”的时刻。大家都懂,对吧?你写了优雅漂亮的 Python 代码,结果现实给你一记重拳:一个本该秒出的结果,脚本却要跑 18 秒。
这时登场的是 Codon。别误会,它不是又一个“Python 替代品”,不需要你再学一门新语言。它还是 Python,但为现代场景重塑。把它想象成去健身房练成型的 Python 运动健将表亲。
我们共同面对的 Python 悖论
说到 Python:爱它、恨它、离不开它。它支撑了大部分 AI/ML 开发、数据科学,甚至越来越多的整个技术生态。语法简洁、库丰富、社区庞大。
但说实话:Python 很慢。真的很慢。
在我哥本哈根大学做医学 AI 博士研究时,常常跑生存期预测模型,预处理步骤慢到我可以去喝一杯(甚至三杯)咖啡。瓶颈?还是那个熟悉的 Python。
常见变通做法?把性能关键部分下沉到 C/C++,写点 Cython 封装,或者祈祷你的 NumPy 操作足够向量化。这是我们都默认的妥协:享受 Python 的易用性,但要交性能税。
Codon 究竟是什么?
Codon 是一个高性能的 Python compiler,它会把你的 Python 代码翻译为原生 machine code:没有 runtime overhead,没有 interpreter,没有会扼杀 multithreading 梦想的 GIL(Global Interpreter Lock)。
数据相当炸裂:
- 比普通 Python 快 10–100 倍(有时更多)
- 真正的原生 multithreading(没看错)
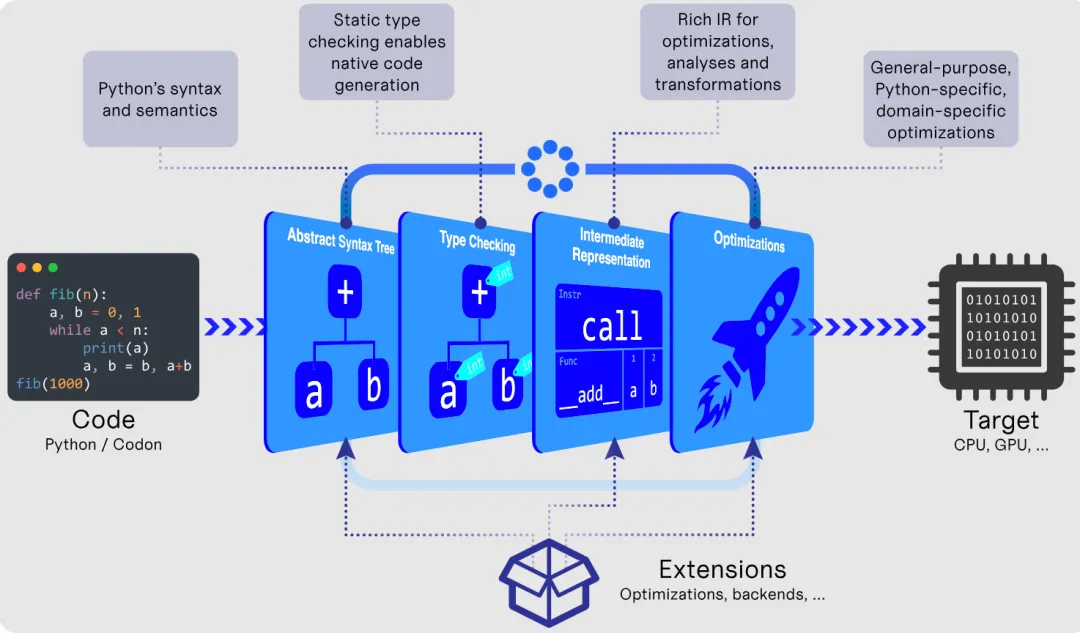 CODON 的工作原理(图片来自 GitHub 页面)
CODON 的工作原理(图片来自 GitHub 页面)下面用实际例子来看看意味着什么。
Fibonacci 现实检验
这是一个最能体现速度差异的简单例子。经典的递归 Fibonacci 函数:性能对比里的“Hello World”:
from time import timedeffib(n):return n if n < 2else fib(n - 1) + fib(n - 2)t0 = time()ans = fib(40)t1 = time()print(f'Computed fib(40) = {ans} in {t1 - t0} seconds.')
用常规 Python 运行:
Computed fib(40)= 102334155 in 17.98 seconds.
用完全相同的代码,通过 Codon 运行:
Computed fib(40)= 102334155 in 0.28 seconds.
不改一行代码,速度提升 65 倍。细品。
这门“魔法”如何实现?
不同于 Python 的解释执行,Codon 采用 ahead-of-time(AOT)编译。它会分析你的整个程序,进行激进优化,并通过 LLVM(Rust、Swift 等语言也用的编译基础设施)编译为原生 machine code。
魔法分几步:
- Static type inference:自动推断类型(不需要 type hints,但有更好)
- High-level optimizations:理解 Python 特有模式并相应优化
- LLVM backend:生成高度优化的 machine code
- Zero runtime overhead:没有 interpreter、没有 bytecode,只有纯原生执行
结果?你写的是 Python,跑起来像 C++。
多线程的解放
还记得 GIL 吗?Python 的 Global Interpreter Lock 臭名昭著,它阻止了真正的并行执行。你可以创建很多线程,但它们轮流执行,而不是并行跑。
Codon 没有 GIL。
看这个——真正 multithreading 的并行素数计数:
from sys import argvdefis_prime(n): factors = 0for i inrange(2, n):if n % i == 0: factors += 1return factors == 0limit = int(argv[1])total = 0@par(schedule='dynamic', chunk_size=100, num_threads=16)for i inrange(2, limit):if is_prime(i): total += 1print(total)
@par 装饰器会用 OpenMP 自动并行化循环。注意,Codon 足够聪明,会把 total += 1 处理为原子化的 reduction,自动避免竞争条件。
对处理大规模医学影像数据的人来说,这是颠覆性的。几千张图像的预处理?并行化。Monte Carlo 模拟?并行化。代码看起来还是 Python,运行起来像一个多线程的 C++ 应用。
无痛的 GPU Programming
更刺激的是,Codon 允许你用 Python 语法写 GPU kernels:
import gpuMAX = 1000N = 4096pixels = [0for _ inrange(N * N)]defscale(x, a, b):return a + (x/N)*(b - a)@gpu.kerneldefmandelbrot(pixels): idx = (gpu.block.x * gpu.block.dim.x) + gpu.thread.x i, j = divmod(idx, N) c = complex(scale(j, -2.00, 0.47), scale(i, -1.12, 1.12)) z = 0j iteration = 0whileabs(z) <= 2and iteration < MAX: z = z**2 + c iteration += 1 pixels[idx] = int(255 * iteration/MAX)mandelbrot(pixels, grid=(N*N)//1024, block=1024)
这就是在 Python 里做 GPU 编程。没有 CUDA 样板、没有内存管理 wrestling、也不需要换语言。只是在 Python 里加点 GPU 特定的 decorators。
更快的 NumPy
Codon 的一大亮点是它的原生 NumPy 实现。这不是简单包一层 C 库:而是用 Codon 重新实现了 NumPy,从而打开了大规模优化空间。
下面是用 Monte Carlo 估计 π:
import timeimport numpy as nprng = np.random.default_rng(seed=0)x = rng.random(500_000_000)y = rng.random(500_000_000)t0 = time.time()pi = ((x-1)**2 + (y-1)**2 < 1).sum() * (4 / len(x))t1 = time.time()print(f'Computed pi~={pi:.4f} in {t1 - t0:.2f} sec')
Python + NumPy:2.25 秒 Codon + NumPy:0.43 秒
这意味着在已高度优化的 NumPy 上又快了 5 倍。编译器可以内联操作、融合数组运算、消除不必要的内存分配——这些在传统 NumPy 里很难做到。
对处理大张量和矩阵运算的 ML 从业者,这能极大缩短实验迭代时间。
Python 生态依旧可用
我一开始的担忧:我们依赖的那些 Python 包怎么办?scikit-learn、pandas、matplotlib、PyTorch?
Codon 通过与 Python 的 interoperability 优雅解决:
from python import matplotlib.pyplot as pltdata = [x**2for x in range(10)]plt.plot(data)plt.show()
你可以导入并使用任意 Python 包。性能关键的部分交给 Codon 的 compiler,其余与常规 Python 生态对接。两全其美。
诚实的取舍
不得不说:Codon 不是 CPython 的完全替代。有些 Python 特性与静态编译天性不合:
- 某些最动态的 metaprogramming 特性
但基于我的体验:对大多数数据科学、ML 和计算型工作负载,这些限制并不关键。你不会在 NumPy pipeline 或模型训练循环里用 Python 的动态特性去改变量类型。你写的是相对静态、性能关键、被 Python 解释器掣肘的代码。
这正是 Codon 发光的地方。
真实世界的影响:我的场景
举个我自己的例子。博士期间,我做的是医学影像数据的生存期预测模型。一个典型的预处理流程包括:
纯 Python + NumPy,在大数据集上可能要跑几个小时。即便做了 vectorization,I/O 与计算瓶颈依旧存在。
用 Codon,我可以:
潜在的时间节省非常可观。原来要 3 小时的流程,可能 10–20 分钟就搞定。这不仅是省事,更是从根本上提升科研迭代速度。
入门非常简单
安装很轻松:
/bin/bash -c "$(curl -fsSL https://exaloop.io/install.sh)"
然后你可以:
- 开启优化运行:
codon run -release file.py - 构建可执行文件:
codon build -release file.py - 生成 LLVM IR:
codon build -release -llvm file.py
学习曲线很低,因为它基本还是 Python。你照常写代码,Codon 帮你把它跑快。
更大的图景
Codon 代表着一个重要趋势:拒绝“易写”和“高性能”之间的伪二元对立。几十年来,我们默认高级语言要用性能换生产力。Python 给了我们极高的生产力,我们也忍受了性能损耗。
但如果不必妥协呢?
像 Codon、Mojo 这样的项目正在突破边界。它们在问:为什么不能两者兼得?为什么不能用高级、表达力强的语言,同时获得原生性能?
对 AI/ML 从业者、数据科学家和计算研究者,这种转变可能是革命性的。想象一下:
你该现在就用 Codon 吗?
我的诚恳建议:
适合尝试 Codon 的情况:
- 你的 Python 代码对性能敏感(数值计算、模拟、数据处理)
- 你需要真正的 multithreading 或 GPU 能力
继续用 CPython 的情况:
就我的场景:ML 研究和医疗 AI,Codon 非常有吸引力。计算核心上的性能增益很难忽视,而且无需与 GIL 斗争就能并行化,这点太重要了。
未来是编译的
写下这些时,Codon 在 GitHub 上已有 16.3k stars,社区活跃。项目采用 Apache-2.0 许可,并得到(NSF、NIH、MIT 等)严肃机构的支持,持续改进中。
它完美吗?不是。会完全取代 CPython 吗?大概率不会。但它是否代表了高性能 Python 的一个令人兴奋的方向?绝对是。
如果你曾希望 Python 更快,却不想把代码重写成 C++,Codon 值得一试。它不仅是另一个 compiler:而是当性能不再是事后之念时,对 Python 可能性的重新想象。
试试看。写点代码。计个时。我想你会被惊到。
也许,我们终于可以不再默默接受那笔一直以来的性能税了。
GitHub :
仓库: https://github.com/exaloop/codon
文档: https://docs.exaloop.io
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
