如果你需要收集和分析微信公众号的文章数据,可能会遇到这些烦恼:手动复制粘贴效率低下、需要频繁登录获取token、无法批量处理多个公众号……今天介绍的这个开源Python工具,能帮你一键解决所有这些问题!
这款名为“微信爬虫工具”的项目,通过智能的自动登录功能和简洁的GUI界面,让公众号数据爬取变得像点外卖一样简单。无论是市场研究人员、内容分析师还是自媒体运营者,都能从中受益。
🔥 项目亮点
- 🔐 智能自动登录不再需要手动复制token和cookie,工具能自动打开Chrome浏览器并完成微信公众平台登录,认证信息还能本地缓存4天
- 📚 批量高效爬取支持同时处理多个公众号,可设置时间范围和关键词筛选,还能控制爬取频率防止被封
- 💻 简洁图形界面基于PyQt5开发的直观GUI,操作简单明了,实时显示爬取进度和状态
- 🔍 本地智能查询内置自然语言解析引擎,可以用中文查询文章,如“查找量子位最近一周关于AI的文章”
- 📦 一键打包分发提供快速打包脚本,可将项目打包为独立的可执行文件,方便分享给没有Python环境的用户
😫 解决什么痛点?
想象一下,你是一名市场研究员,需要跟踪10个竞争对手公众号最近三个月的动态。传统方式需要:1) 逐个访问公众号;2) 一页页翻看历史文章;3) 手工复制感兴趣的内容;4) 整理到表格中。这个过程不仅耗时,还容易出错。
更让人头疼的是:微信公众平台需要登录才能获取数据,而登录信息(token和cookie)有效时间短,手动获取过程复杂。你需要按F12打开开发者工具,在“网络”标签中刷新页面,找到特定请求,再从“载荷”和“标头”中分别复制token和cookie。这个过程对非技术人员来说简直是噩梦!
这个工具的出现,就像给你的数据收集工作配备了一个智能助手。它解决了三大核心痛点:
自动化替代手工操作:从登录认证到文章爬取,全程自动化处理,释放你的双手。你只需要输入公众号名称、设置时间范围和关键词,点击开始按钮,剩下的就交给工具了。
批量处理代替逐个收集:可以一次性添加多个公众号,设置统一的时间范围,工具会按顺序自动爬取,并在界面上实时显示每个公众号的处理进度。
智能查询优化数据利用:爬取到的文章可以存储到本地数据库,通过智能查询功能快速找到你需要的内容。比如想找“最近一个月包含‘人工智能’关键词的文章,按发布时间排序”,只需输入这句自然语言,工具就会转换成SQL查询并返回结果。
🛠️ 手把手教程
环境安装与启动
首先确保你的电脑上安装了Python 3.7或更高版本,然后跟着下面的步骤操作:
# 克隆或下载项目代码到本地git clone https://github.com/zizhanovo/py-spider-for-wechat.gitcd py-spider-for-wechat# 安装项目依赖pip install -r requirements.txt# 启动程序(推荐使用启动脚本,它会自动检查依赖)python 启动爬虫.py
启动脚本会自动检查并安装缺失的依赖包,包括PyQt5(图形界面库)、requests(HTTP请求库)和selenium(自动登录功能)。一切就绪后,简洁的GUI界面就会呈现在你面前。
第一步:轻松登录获取权限
程序启动后,你会看到清晰的界面。要开始爬取,首先需要获取访问权限:
自动登录(推荐):
- 等待Chrome浏览器自动打开并跳转到微信公众平台
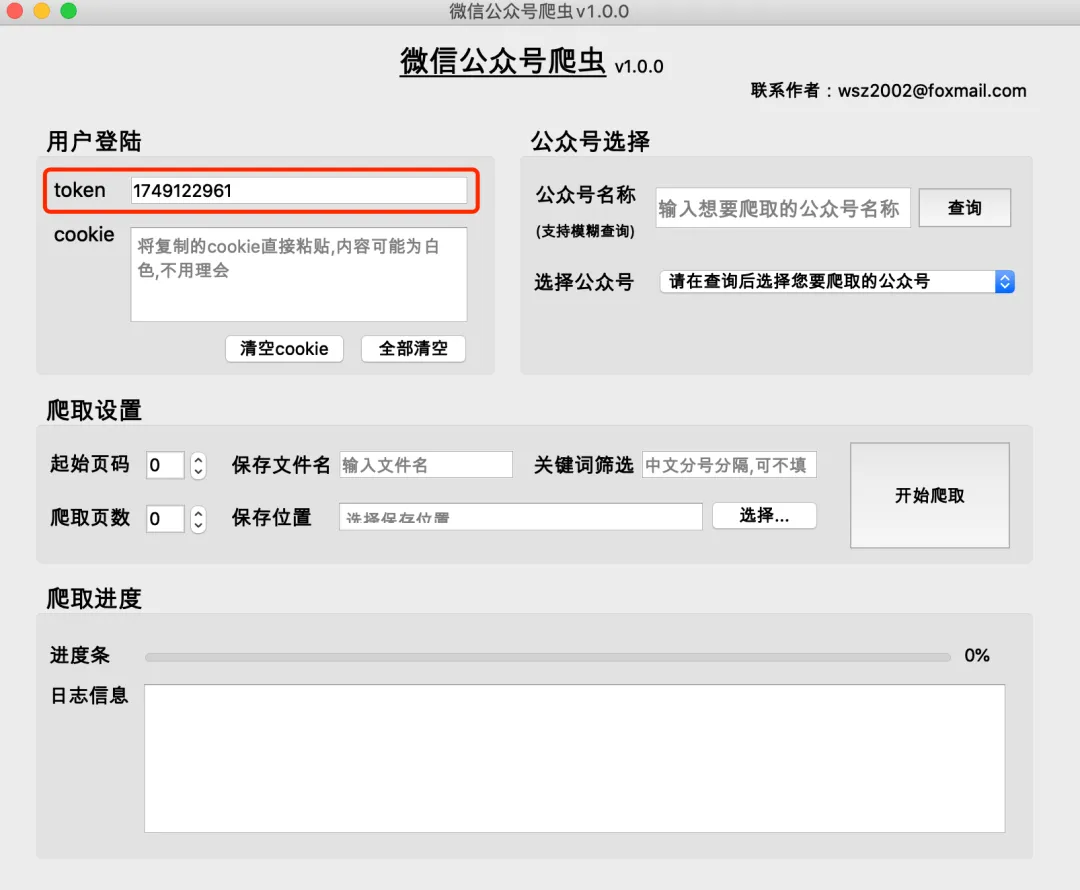
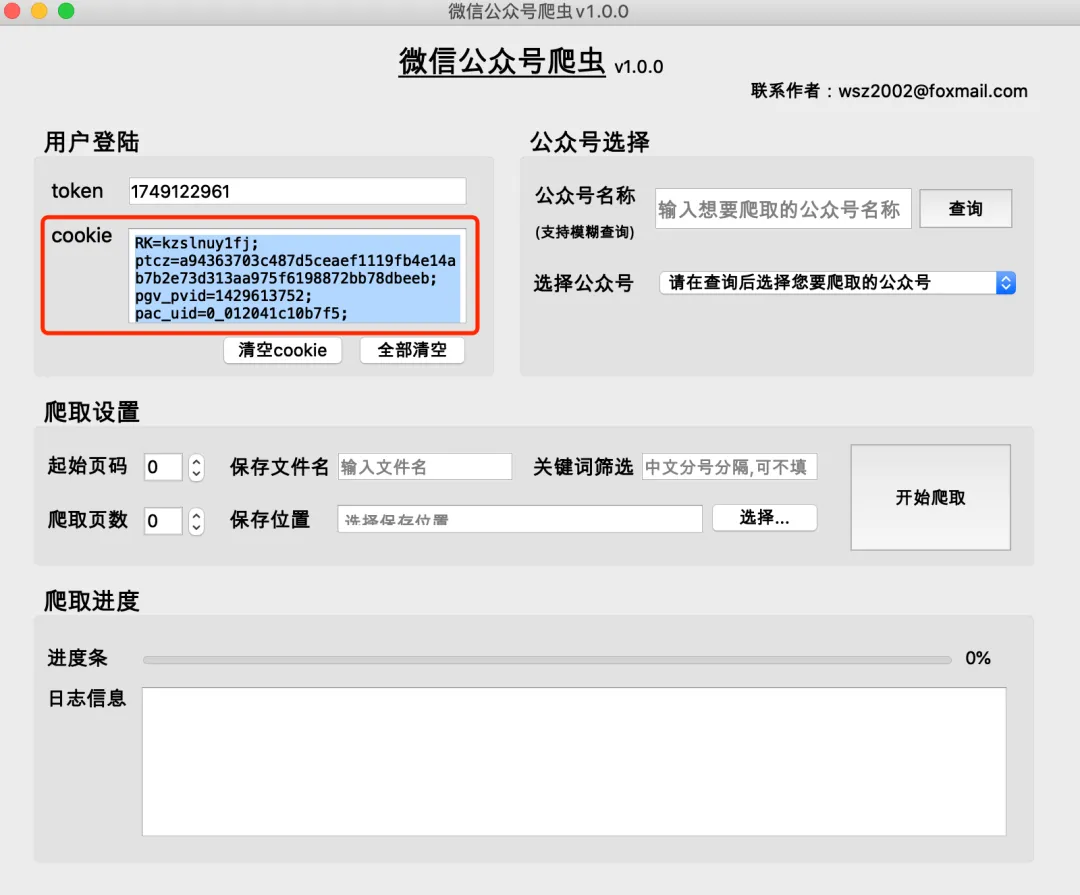
- 登录成功后,浏览器会自动关闭,token和cookie信息会自动填入对应输入框
手动登录(备用方案):如果自动登录遇到问题,可以按照传统方式:
- 找到包含token的请求,从“载荷”中复制token
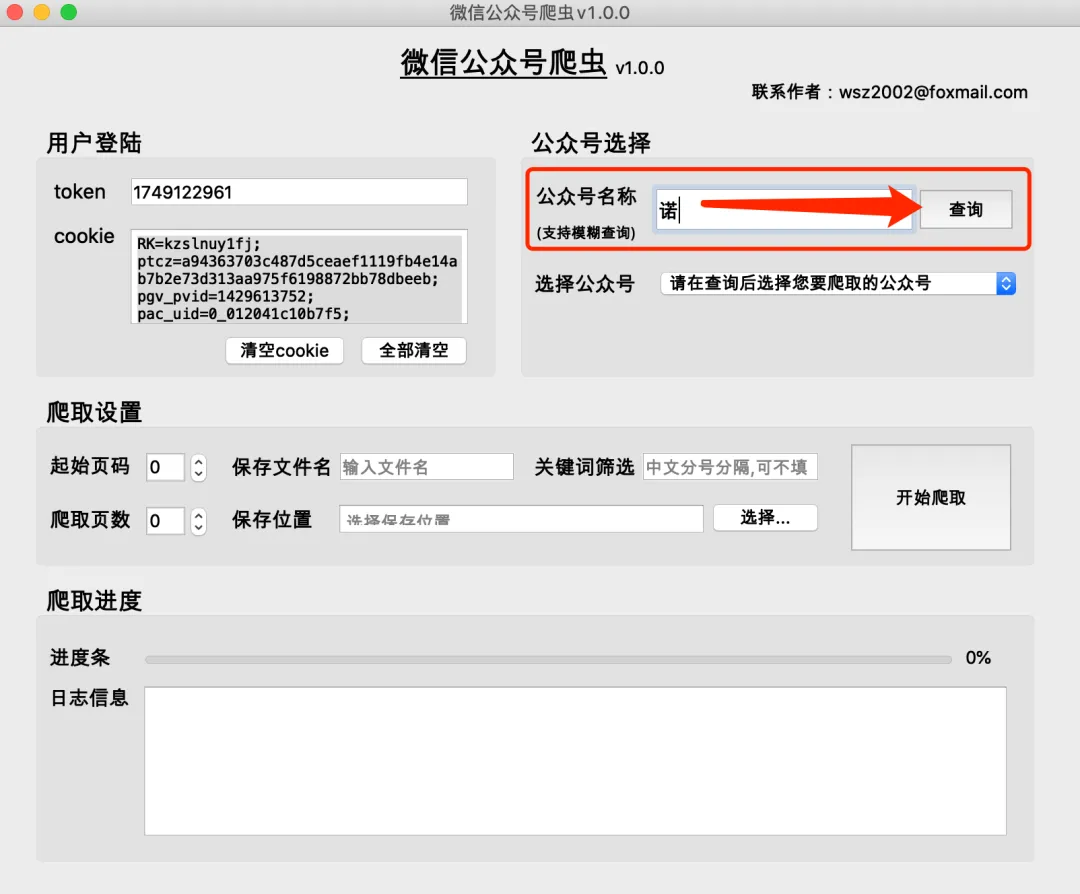
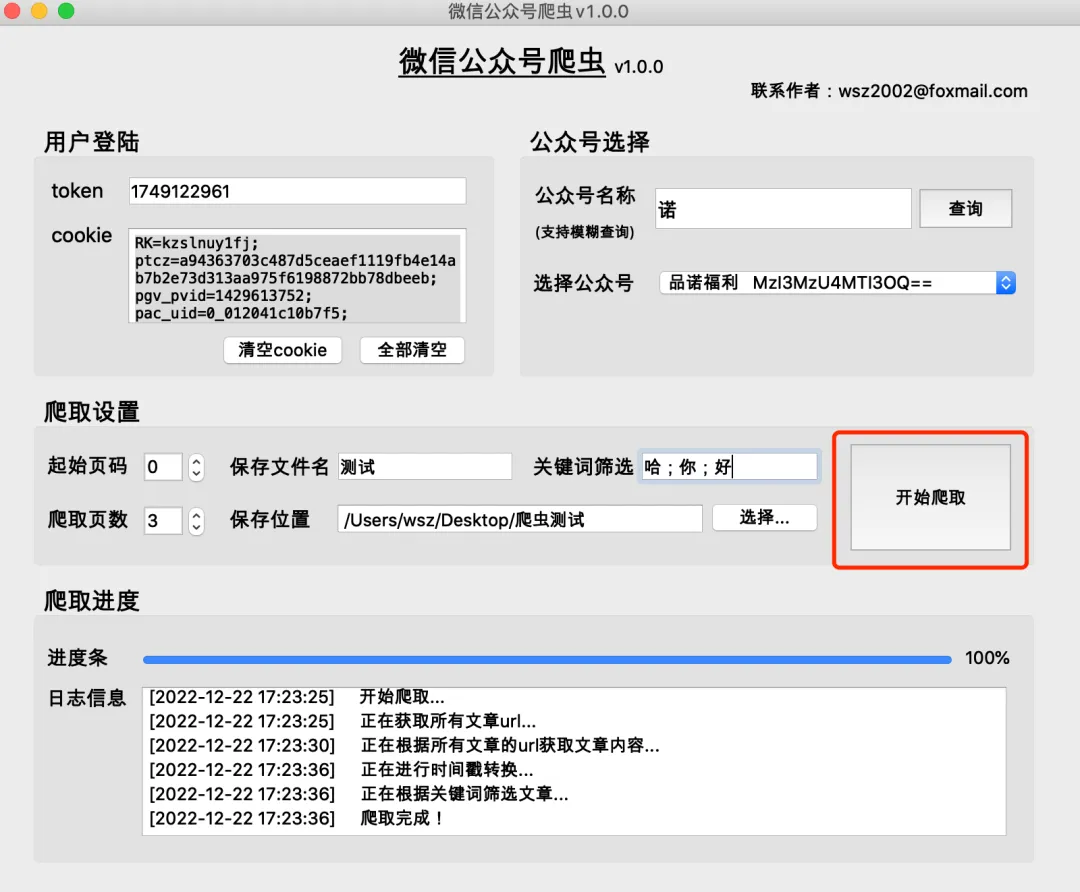
第二步:配置爬取参数
登录成功后,就可以开始配置爬取任务了:
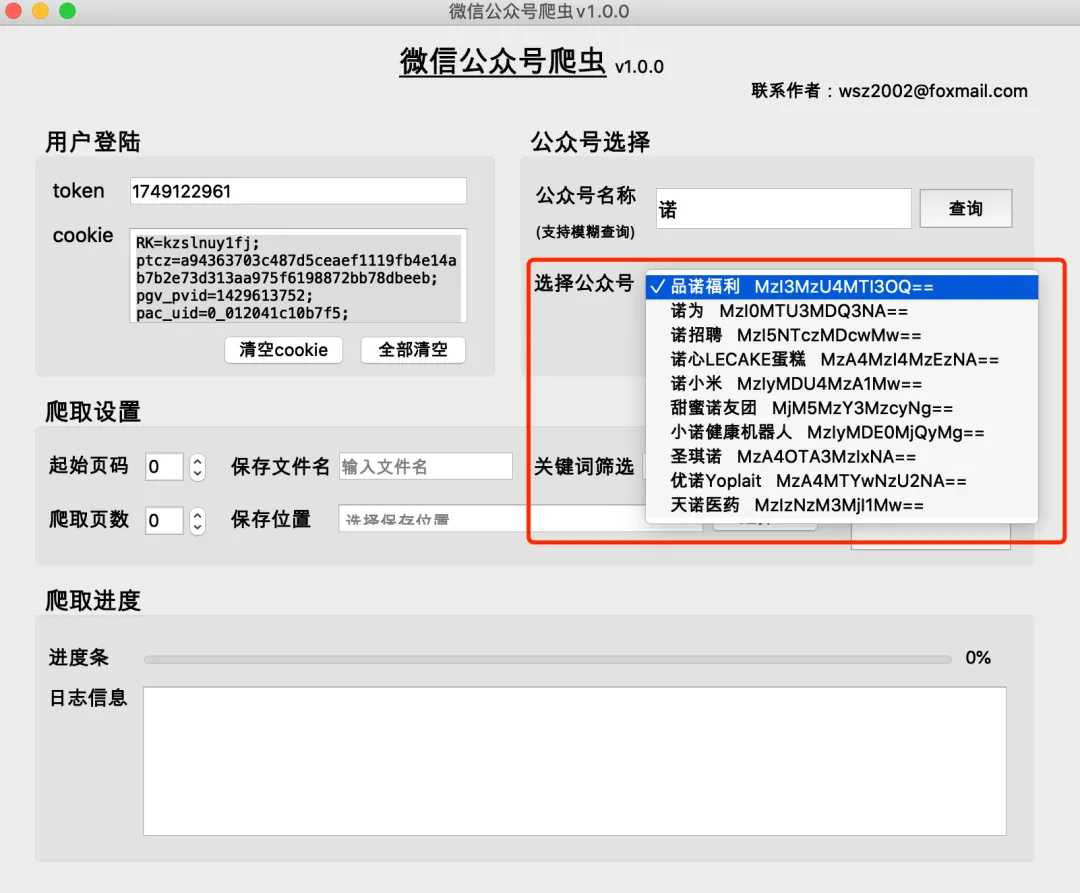
单个公众号爬取:
- 可选:输入关键词进行筛选,用中文分号隔开多个关键词
批量公众号爬取:
- 通过“添加”按钮逐个添加公众号,或点击“从文件导入”批量导入
- 设置时间范围:使用日期选择器或快捷按钮(最近7天、最近30天等)
- 调整请求间隔(建议20-1200秒,防止请求过于频繁)
第三步:查看与管理结果
爬取完成后,工具会在你指定的目录下生成结果文件:
保存目录/├── 文件名_20250123/ # 以日期命名的结果文件夹│ ├── 文件名_爬取结果.csv # 最终整理好的文章数据│ └── raw/ # 中间文件(可删除)│ ├── 文件名_url.csv # 文章URL列表│ ├── 文件名_title.csv # 文章标题│ ├── 文件名_content.csv # 文章内容│ └── 文件名_real-time.csv # 时间戳转换结果
CSV文件中包含文章的标题、发布时间、摘要、阅读量、点赞数等完整信息,可以直接用Excel打开分析。
第四步:智能查询已爬取的文章
如果开启了数据库存储功能,你还可以使用智能查询快速找到特定文章:
- 在查询框中输入自然语言描述,如:“量子位最近一周关于人工智能的文章”
工具内置的本地自然语言解析引擎会识别公众号名称、关键词、时间范围和排序要求,转换成SQL查询语句,无需连接外部AI服务。
打包为可执行文件
如果你想将工具分享给没有Python环境的同事或朋友,可以使用内置的打包功能:
# 运行快速打包脚本python 快速打包.py
脚本会自动检测你的操作系统,并生成对应平台的可执行文件。Windows系统会生成.exe文件,macOS会生成.app应用程序,Linux会生成可执行文件。打包后的文件大小约41MB,包含了所有依赖,可以直接运行。
📊 同类项目对比
与其他公众号爬虫工具相比,这个项目在易用性和功能完整性方面表现出色:
特别值得一提的是,本项目的自动登录功能大大降低了使用门槛。传统的公众号爬虫工具需要用户手动获取并粘贴token和cookie,这个过程不仅复杂,而且登录信息有效期短,需要频繁更新。本项目的自动登录就像给你的爬虫装上了“自动驾驶”系统,让整个过程流畅自然。
💡 使用技巧与注意事项
- 首次使用建议先尝试爬取1-2页内容,确保一切正常后再进行大规模爬取
- 合理控制频率设置适当的请求间隔(建议至少30秒),避免被微信平台限制访问
- 关键词筛选技巧使用具体、明确的关键词,多个关键词用中文分号隔开,如“人工智能;机器学习;深度学习”
- 时间范围选择如果需要大量历史数据,建议分批爬取,比如每次爬取一个月的数据
- 数据管理定期清理raw文件夹中的中间文件,只保留最终的爬取结果.csv文件
- 遵守使用规范仅将工具用于合法的数据收集和研究用途,尊重内容创作者的劳动成果
遇到问题怎么办?
- 自动登录失败:检查Chrome浏览器是否安装,网络是否畅通,或使用手动登录方式
- 爬取无结果:确认公众号名称正确,token/cookie未过期,网络连接正常
- 程序启动错误:确保已安装所有依赖,可尝试重新运行“pip install -r requirements.txt”
这个工具就像是为公众号数据收集量身定做的瑞士军刀,将原本复杂的技术操作封装成了简单的点击操作。无论你是需要做竞品分析、内容研究还是数据挖掘,它都能帮你节省大量时间和精力。
项目完全开源,你还可以根据自己的需求进行二次开发。比如添加更多的导出格式、集成到自己的数据分析流程中,或者优化爬取策略。
数据收集不应该成为研究的障碍,而是推动洞察的助力。有了这个工具,你可以更专注于数据背后的故事,而不是陷入技术细节的泥潭。不妨现在就试试看,开启你的高效数据收集之旅吧!
项目地址:可在GitHub搜索“py-spider-for-wechat”获取最新版本。如果你觉得这个工具有用,别忘了给作者一个Star哦!
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
