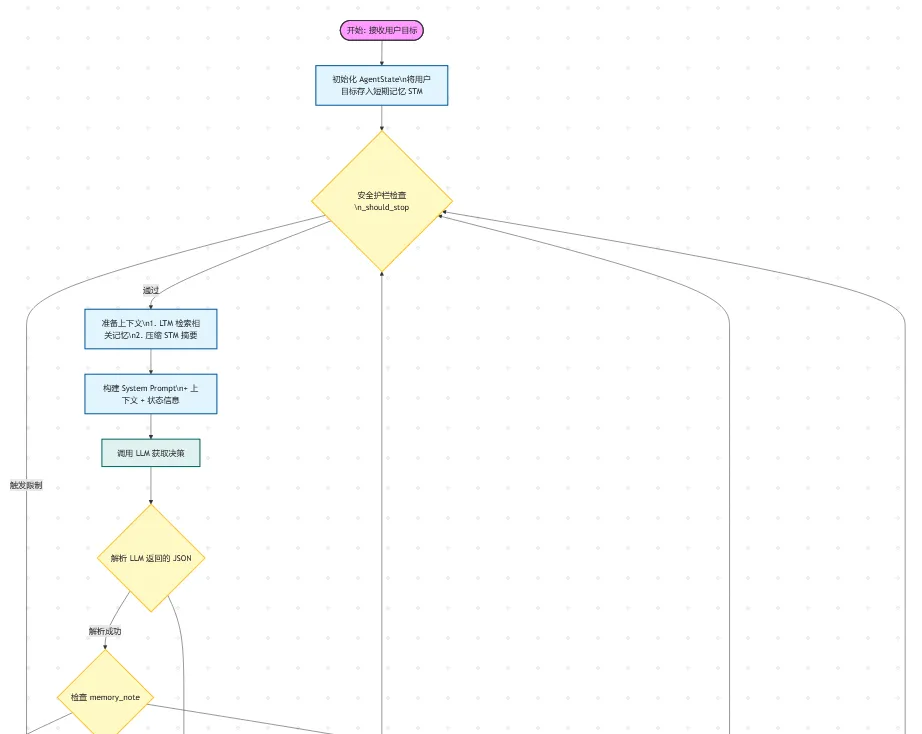
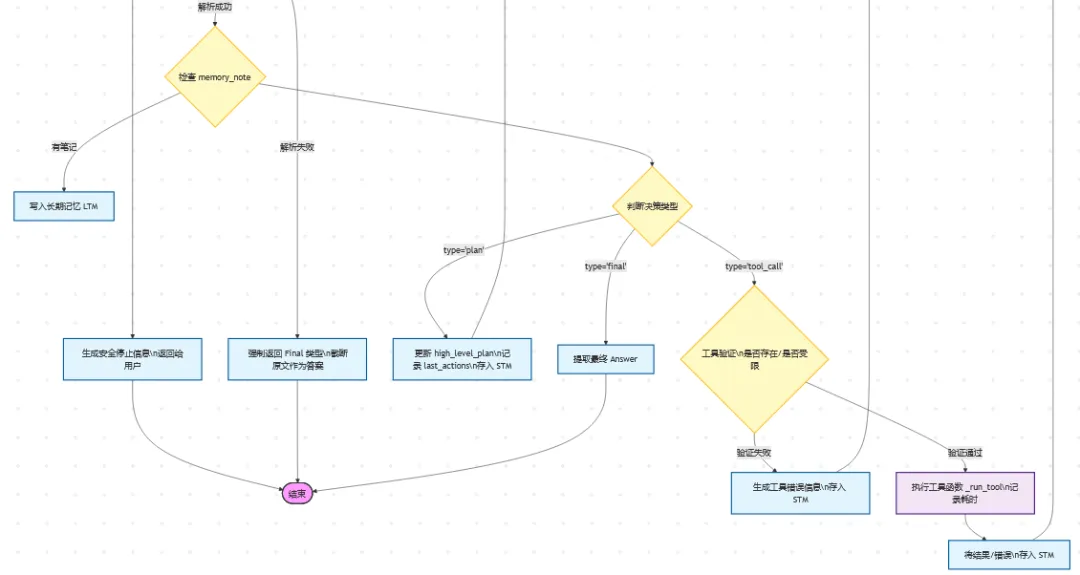
"""------------------------------------------------------------基于原生 Python 实现的最小化 AI Agent 循环 (无 LangChain)。- 工具系统:注册中心 + 安全执行- 记忆系统:短期上下文 + 基于文件的长期笔记- 规划系统:简易计划表 + 下一步行动- 安全护栏:最大步数、工具调用限制、循环检测- 调试支持:每一步的详细追踪日志"""from __future__ import annotationsimport jsonimport osimport timeimport refrom dataclasses import dataclass, fieldfrom typing import Any, Callable, Dict, List, Optional, Tupleimport requests# -----------------------------# 工具函数# -----------------------------from dotenv import load_dotenvdef now_ms() -> int: """获取当前时间戳(毫秒)""" return int(time.time() * 1000)def clamp_text(text: str, max_chars: int = 1800) -> str: """截断过长的文本,防止 Token 溢出""" text = text.strip() if len(text) <= max_chars: return text return text[:max_chars] + " ...[已截断]"def safe_json_extract(text: str) -> Optional[Dict[str, Any]]: """ 安全地从模型回复中提取 JSON 对象。 模型必须输出单个 JSON 对象,此函数尝试提取第一个 {...} 块。 """ text = text.strip() # 快速路径:纯 JSON if text.startswith("{") and text.endswith("}"): try: return json.loads(text) except Exception: pass # 正则提取第一个 {...} 代码块 match = re.search(r"\{.*\}", text, flags=re.DOTALL) if not match: return None blob = match.group(0) try: return json.loads(blob) except Exception: return Nonedef simple_similarity(a: str, b: str) -> float: """ 微小的循环检测启发式算法:基于 token 重叠率。 足以检测“反复执行相同动作”的死循环情况。 """ sa = set(a.lower().split()) sb = set(b.lower().split()) if not sa or not sb: return 0.0 return len(sa & sb) / max(1, len(sa | sb))# -----------------------------# 工具系统# -----------------------------@dataclassclass Tool: name: str description: str schema: Dict[str, Any] fn: Callable[[Dict[str, Any]], Any] safe: bool = True # 标记是否为危险工具(如写文件)class ToolRegistry: def __init__(self) -> None: self._tools: Dict[str, Tool] = {} def register(self, tool: Tool) -> None: if tool.name in self._tools: raise ValueError(f"工具已注册: {tool.name}") self._tools[tool.name] = tool def get(self, name: str) -> Optional[Tool]: return self._tools.get(name) def as_prompt_block(self) -> str: """ 将工具列表转换为紧凑、易读的 Prompt 文本块。 """ lines = ["可用工具列表:"] for t in self._tools.values(): safe_tag = "安全" if t.safe else "受限" lines.append(f"- {t.name} ({safe_tag}): {t.description}") lines.append(f" 参数定义: {json.dumps(t.schema, ensure_ascii=False)}") return "\n".join(lines)# -----------------------------# 记忆系统# -----------------------------@dataclassclass MemoryNote: ts_ms: int text: str tags: List[str] = field(default_factory=list)class LongTermMemory: """ 简单的长期记忆: - 将紧凑的笔记存储在 JSONL 文件中 - 基于关键词重叠进行检索(简单、快速、无需向量库) """ def __init__(self, path: str = "agent_memory.jsonl") -> None: self.path = path if not os.path.exists(self.path): with open(self.path, "w", encoding="utf-8") as f: f.write("") def add(self, text: str, tags: Optional[List[str]] = None) -> None: note = MemoryNote(ts_ms=now_ms(), text=text.strip(), tags=tags or []) with open(self.path, "a", encoding="utf-8") as f: f.write(json.dumps(note.__dict__, ensure_ascii=False) + "\n") def search(self, query: str, k: int = 5) -> List[MemoryNote]: query_tokens = set(query.lower().split()) scored: List[Tuple[float, MemoryNote]] = [] with open(self.path, "r", encoding="utf-8") as f: for line in f: line = line.strip() if not line: continue try: obj = json.loads(line) note = MemoryNote(**obj) tokens = set(note.text.lower().split()) score = len(tokens & query_tokens) if score > 0: scored.append((float(score), note)) except Exception: continue scored.sort(key=lambda x: x[0], reverse=True) return [n for _, n in scored[:k]]class ShortTermMemory: """ 保存最近的 N 条消息(已压缩)。 """ def __init__(self, max_items: int = 18) -> None: self.max_items = max_items self.items: List[Dict[str, str]] = [] def add(self, role: str, content: str) -> None: self.items.append({"role": role, "content": content}) if len(self.items) > self.max_items: self.items = self.items[-self.max_items:]# -----------------------------# LLM 客户端 (DeepSeek)# -----------------------------load_dotenv()class LLMClient: def __init__(self) -> None: # 适配国内环境,优先读取 DeepSeek 配置 self.api_key = os.environ['DEEPSEEK_API'].strip() if not self.api_key: raise RuntimeError("缺少 API Key,请设置环境变量 DEEPSEEK_API_KEY") # DeepSeek 兼容 OpenAI 接口格式 self.base_url = os.environ['DEEPSEEK_URL'].strip() if not self.base_url.endswith("/v1"): # 兼容用户可能输入不带 v1 的情况 self.base_url = self.base_url.rstrip("/") + "/v1" self.model = os.environ['DEEPSEEK_MODEL'].strip() def chat(self, messages: List[Dict[str, str]], temperature: float = 0.2) -> str: url = f"{self.base_url}/chat/completions" headers = {"Authorization": f"Bearer {self.api_key}"} payload = { "model": self.model, "temperature": temperature, "messages": messages, } try: r = requests.post(url, headers=headers, json=payload, timeout=60) r.raise_for_status() data = r.json() return data["choices"][0]["message"]["content"] except Exception as e: return f"LLM 调用错误: {str(e)}"# -----------------------------# Agent 核心逻辑# -----------------------------@dataclassclass AgentConfig: max_steps: int = 10 # 最大思考步数 max_tool_calls: int = 6 # 最大工具调用次数 max_seconds: int = 35 # 最大运行时间(秒) allow_restricted_tools: bool = False # 是否允许使用危险工具@dataclassclass AgentState: step: int = 0 tool_calls: int = 0 started_ms: int = field(default_factory=now_ms) high_level_plan: List[str] = field(default_factory=list) last_actions: List[str] = field(default_factory=list) # 用于检测循环 trace: List[Dict[str, Any]] = field(default_factory=list) # 调试追踪class ScratchAgent: """ 最小化 Agent 实现: - 请求模型生成计划 + 下一步行动 - 按需执行工具 - 存储记忆笔记 - 安全停止 """ def __init__(self, llm: LLMClient, tools: ToolRegistry, ltm: LongTermMemory, cfg: AgentConfig) -> None: self.llm = llm self.tools = tools self.ltm = ltm self.cfg = cfg self.stm = ShortTermMemory(max_items=18) def _time_left(self, state: AgentState) -> int: elapsed = now_ms() - state.started_ms return max(0, self.cfg.max_seconds * 1000 - elapsed) def _should_stop(self, state: AgentState) -> Optional[str]: """检查是否满足停止条件""" if state.step >= self.cfg.max_steps: return "已达到最大步数限制" if state.tool_calls >= self.cfg.max_tool_calls: return "已达到最大工具调用次数" if self._time_left(state) <= 0: return "已达到最大运行时长" # 循环检测:如果连续执行非常相似的动作 if len(state.last_actions) >= 3: a, b, c = state.last_actions[-3:] if simple_similarity(a, b) > 0.85 and simple_similarity(b, c) > 0.85: return "检测到重复动作循环" return None def _compact_memory_summary(self) -> str: """ 将短期记忆压缩为 Agent 可以携带的紧凑摘要。 """ # 仅保留最后 8 条,并压缩换行符 tail = self.stm.items[-8:] lines = [] for it in tail: role = it["role"] content = clamp_text(it["content"], 260).replace("\n", " ") lines.append(f"{role}: {content}") return "\n".join(lines) def _build_system_prompt(self, user_goal: str) -> str: """ 最核心的部分:严格的输出格式 + 清晰的行为规范。 """ return f"""你是一个严谨的 AI Agent。你的任务是安全、高效地完成用户的目标。用户目标:{user_goal}规则:- 你必须且只能回复一个 JSON 对象,不要包含任何其他废话。- 每一步只能选择一个动作。- 如果信息充足,直接给出最终答案。- 保持计划简短扼要。- 避免死循环。如果卡住了,说明缺失了什么信息,然后尝试结束任务。输出 JSON 格式定义:{{ "type": "plan" | "tool_call" | "final", "plan": ["..."] (当 type="plan" 时必填, 高层计划列表), "next": "...一句话描述下一步..." (当 type="plan" 时必填), "tool": "工具名称" (当 type="tool_call" 时必填), "args": {{...}} (当 type="tool_call" 时必填, 工具参数), "answer": "...最终答案..." (当 type="final" 时必填), "memory_note": "...需要长期存储的简短笔记..." (可选)}}{self.tools.as_prompt_block()}""".strip() def _model_step(self, user_goal: str, state: AgentState) -> Dict[str, Any]: # 检索长期记忆 ltm_hits = self.ltm.search(user_goal, k=4) ltm_block = "\n".join([f"- {clamp_text(n.text, 240)}" for n in ltm_hits]) or "- (无历史记忆)" system = self._build_system_prompt(user_goal) context = f"""短期记忆 (摘要):{self._compact_memory_summary()}长期记忆 (相关历史):{ltm_block}当前计划:{state.high_level_plan if state.high_level_plan else"(尚未制定)"}当前步骤: {state.step}已用工具调用: {state.tool_calls}剩余时间: {self._time_left(state) / 1000:.1f}s""".strip() messages = [ {"role": "system", "content": system}, {"role": "user", "content": context}, ] raw = self.llm.chat(messages, temperature=0.2) obj = safe_json_extract(raw) if not obj: # 容错:如果解析失败,强制结束以防乱跑 return {"type": "final", "answer": clamp_text(raw, 900)} return obj def _run_tool(self, name: str, args: Dict[str, Any]) -> Dict[str, Any]: tool = self.tools.get(name) if not tool: return {"ok": False, "error": f"未知工具: {name}", "data": None, "latency_ms": 0} if (not tool.safe) and (not self.cfg.allow_restricted_tools): return {"ok": False, "error": f"工具受限: {name}", "data": None, "latency_ms": 0} t0 = now_ms() try: out = tool.fn(args) return {"ok": True, "error": None, "data": out, "latency_ms": now_ms() - t0} except Exception as e: return {"ok": False, "error": str(e), "data": None, "latency_ms": now_ms() - t0} def run(self, user_goal: str) -> str: state = AgentState() self.stm.add("user", user_goal) while True: stop_reason = self._should_stop(state) if stop_reason: final = f"安全停止: {stop_reason}。\n\n建议下一步:澄清缺失信息或缩小任务范围。" self.stm.add("assistant", final) return final state.step += 1 decision = self._model_step(user_goal, state) dtype = decision.get("type", "").strip() trace_item: Dict[str, Any] = { "step": state.step, "decision": decision, "tool_result": None, } # 存储记忆笔记 (如果模型提供了) mem_note = (decision.get("memory_note") or "").strip() if mem_note: self.ltm.add(mem_note, tags=["agent_note"]) if dtype == "plan": plan = decision.get("plan") or [] if isinstance(plan, list) and plan: state.high_level_plan = [str(x)[:140] for x in plan][:6] nxt = str(decision.get("next") or "").strip() state.last_actions.append("plan:" + nxt) self.stm.add("assistant", f"PLAN: {state.high_level_plan}\nNEXT: {nxt}") state.trace.append(trace_item) continue if dtype == "tool_call": tool_name = str(decision.get("tool") or "").strip() args = decision.get("args") or {} if not isinstance(args, dict): args = {} state.tool_calls += 1 action_sig = f"tool:{tool_name} args:{json.dumps(args, sort_keys=True)}" state.last_actions.append(action_sig) result = self._run_tool(tool_name, args) trace_item["tool_result"] = result state.trace.append(trace_item) obs = { "tool": tool_name, "ok": result["ok"], "error": result["error"], "data": clamp_text(json.dumps(result["data"], ensure_ascii=False), 1200) if result["ok"] else None, "latency_ms": result["latency_ms"], } self.stm.add("assistant", f"TOOL_OBSERVATION: {json.dumps(obs, ensure_ascii=False)}") continue # 最终答案 answer = str(decision.get("answer") or "").strip() if not answer: answer = "任务结束。" self.stm.add("assistant", answer) return answer# -----------------------------# 内置工具 (安全且实用)# -----------------------------def tool_calc(args: Dict[str, Any]) -> Any: """安全的计算器""" expr = str(args.get("expression", "")).strip() if not expr: raise ValueError("缺少表达式") # 仅允许数字和基本运算符 if not re.fullmatch(r"[0-9\.\+\-\*\/\(\)\s]+", expr): raise ValueError("表达式包含非法字符") return eval(expr, {"__builtins__": {}}, {})def tool_summarize(args: Dict[str, Any]) -> Any: """简单的文本摘要工具""" text = str(args.get("text", "")).strip() max_lines = int(args.get("max_lines", 6)) text = clamp_text(text, 3000) lines = [ln.strip() for ln in text.splitlines() if ln.strip()] # 启发式摘要:取前几行 + 关键点(这里简单取前N行) out = [] for ln in lines[:max_lines]: out.append(ln[:180]) return outdef tool_read_file(args: Dict[str, Any]) -> Any: """读取本地文本文件""" path = str(args.get("path", "")).strip() if not path: raise ValueError("缺少路径参数") # 禁止父目录遍历 if ".." in path.replace("\\", "/"): raise ValueError("禁止访问父目录") with open(path, "r", encoding="utf-8") as f: return clamp_text(f.read(), 6000)def build_tools() -> ToolRegistry: reg = ToolRegistry() reg.register(Tool( name="calc", description="安全地计算数学表达式 (数字 + - * / 括号)", schema={"type": "object", "properties": {"expression": {"type": "string"}}, "required": ["expression"]}, fn=tool_calc, safe=True, )) reg.register(Tool( name="summarize", description="从长文本中生成简短的要点摘要", schema={"type": "object", "properties": {"text": {"type": "string"}, "max_lines": {"type": "integer"}}, "required": ["text"]}, fn=tool_summarize, safe=True, )) reg.register(Tool( name="read_file", description="读取本地文本文件 (禁止父目录遍历)", schema={"type": "object", "properties": {"path": {"type": "string"}}, "required": ["path"]}, fn=tool_read_file, safe=False, # 文件读取默认视为受限操作 )) return reg# -----------------------------# 演示 / Demo# -----------------------------if __name__ == "__main__": # 初始化 LLM (DeepSeek) llm = LLMClient() # 构建工具集 tools = build_tools() # 初始化记忆 ltm = LongTermMemory(path="agent_memory.jsonl") # Agent 配置 cfg = AgentConfig( max_steps=10, max_tool_calls=6, max_seconds=35, allow_restricted_tools=False, ) # 实例化 Agent agent = ScratchAgent(llm=llm, tools=tools, ltm=ltm, cfg=cfg) # 执行任务 goal = ( "制定一个简短的旅游计划,目的地是北京,计划包括整个费用,路线,酒店,吃饭,风景名胜古迹等。" ) print("-" * 50) print("Agent 开始运行...") print("-" * 50) result = agent.run(goal) print("-" * 50) print("最终结果:") print(result)
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
