NVIDIA GPU CUDA编程模型基础概念
- 2026-07-06 07:57:48

为了深入理解NVIDIA GPU MIG(多实例GPU) 功能的原理与应用,掌握其底层的硬件架构与CUDA编程模型是必不可少的先决条件。无论是研究MIG(多实例GPU,Multi-Instance GPU),还是与之相关的 MPS(多进程服务,Multi-Process Service) 技术,都共同建立在GPU硬件组成与CUDA编程基础之上。
因此,本文将从初学者的视角出发,系统梳理这两大基础知识体系,旨在帮助刚接触CUDA编程的读者夯实基础,为后续探索虚拟化、多任务调度等高级主题铺平道路。
1、GPU硬件组成
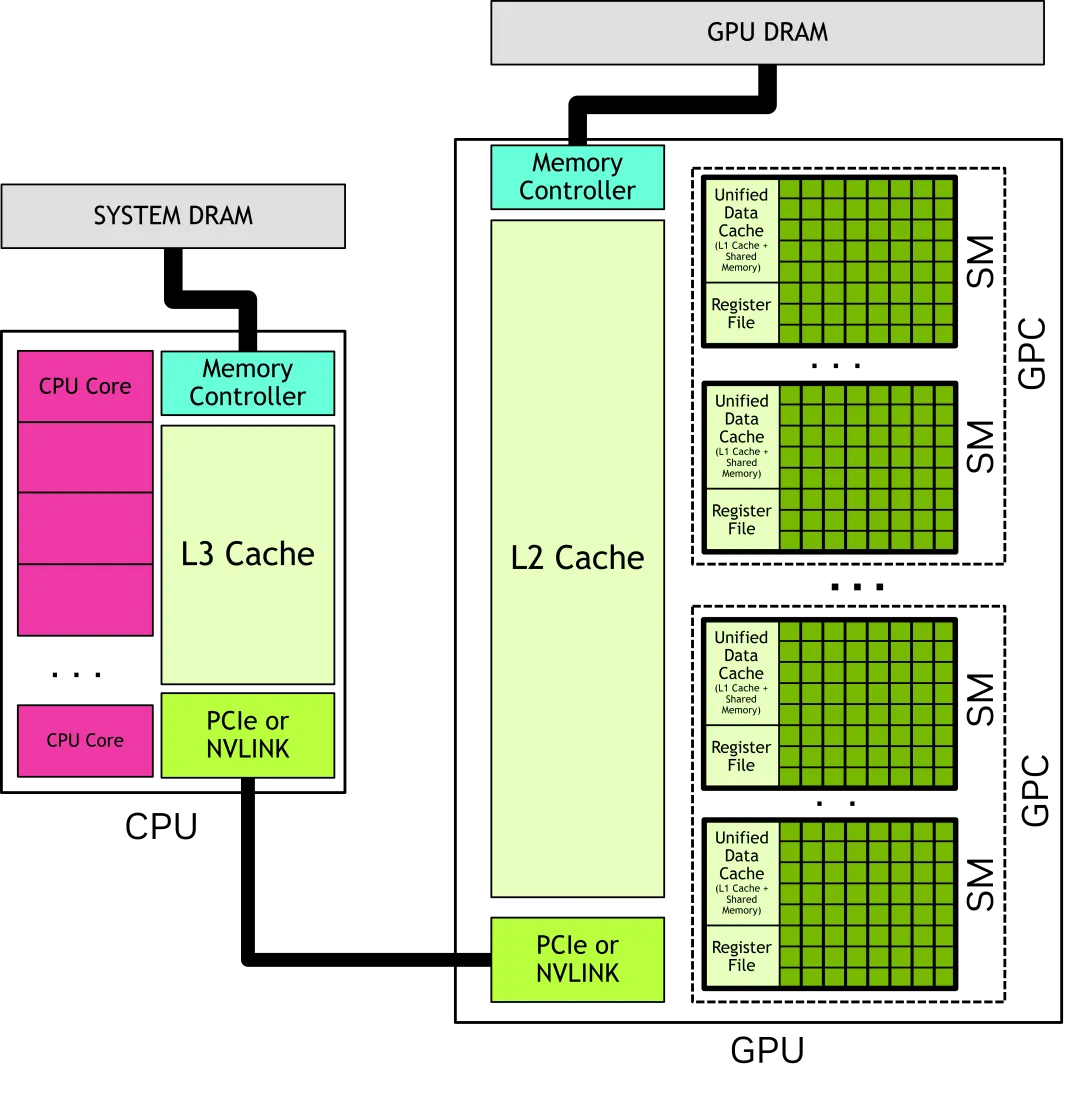
一个GPU有许多SM(Streaming Multiprocessors),每个SM包含许多功能单元,GPCs(Graphics processing clusters)是SM的集合,GPU物理上就是连接在GPU显存上的一组GPC。一个CPU通常是几个核心和一个连接到内存的内存控制器,CPU和GPU之间通过PCIe或者NVLINK连接,如下图示:
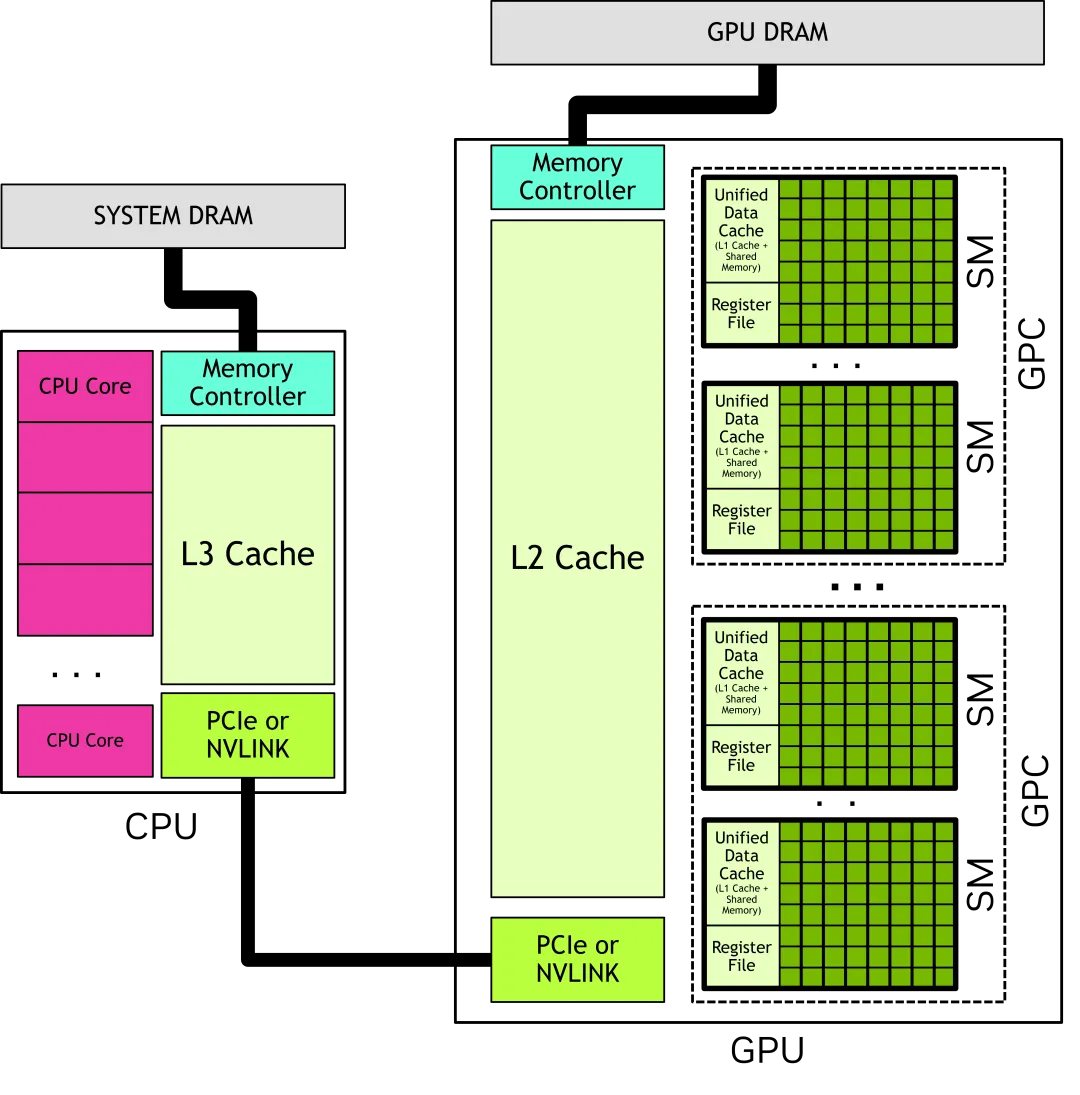
图片来源:nvidia.com
GPU由GPC组成,GPCs连接到显存,每个GPC由多个SM组成,每个SM里有一个本地寄存器文件(Register File)、一个统一的数据缓存(Unified Data Cache)和一些执行计算任务的功能单元(CUDA core、Tensor Core、RT Core)
CUDA Core:CUDA Core 是 NVIDIA GPU上的计算核心单元,用于执行通用的并行计算任务,是最常看到的核心类型。
Tensor Core:Tensor Core 是 NVIDIA Volta 架构及其后续架构(如Ampere架构)中引入的一种特殊计算单元。它们专门用于深度学习任务中的张量计算,如矩阵乘法和卷积运算。
RT Core:RT Core 是 NVIDIA 的专用硬件单元,主要用于加速光线追踪计算。主要是消费级显卡才为光线追踪运算添加了 RTCores。
2、CUDA编程模型
2.1 Thread Blocks和Grids

图片来源:nvidia.com
kernel:GPU上运行的计算逻辑函数,使用__global__关键字声明,由主机调用,在GPU上执行。functions which execute on the GPU which can be invoked from the host are called kernels.
thread:最小的执行单元,当一个kernel运行时,它会启动数百万个thread。
thread block:多个thread称为thread block,一个thread block的所有thread都由一个SM执行(这允许thread block内的thread有效地相互通信和同步),且直到运行完成都在这个SM,所以thread block之间不能有依赖关系,一个SM内可以运行多个thread block。
grid:grid由thread block组成,一个grid中的thread block可以在多个SM中运行。
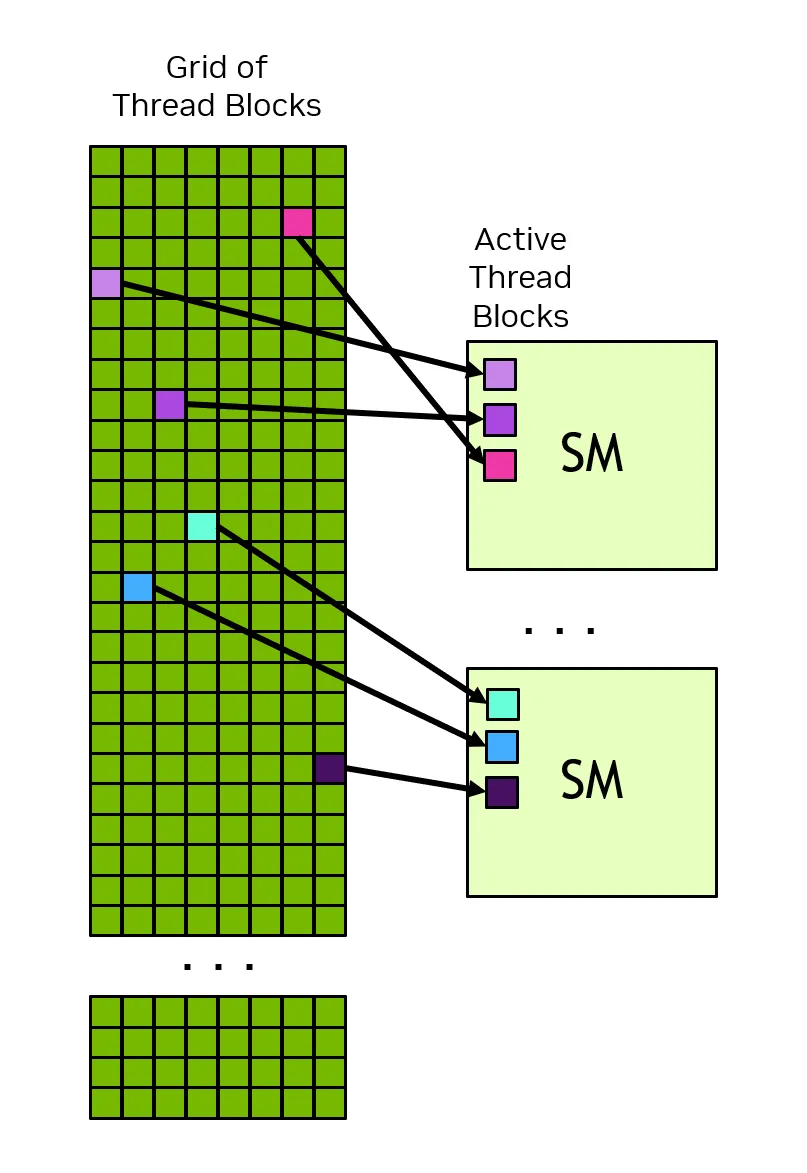
图片来源:nvidia.com
CUDA编程模型允许任意大小的grid在任意大小的GPU上运行,无论这个GPU只有一个SM还是数千个SM,所以这里就有个限制:CUDA编程模型要求不同thread block中的thread之间没有数据依赖关系,即thread不能依赖于同一grid的不同thread的结果,一个thread block的所有thread同时在一个SM上运行。Grid中的不同thread block在可用的SM之间调度,简单来说就是CUDA编程模型可以以任何顺序(并行或者串行)执行thread block。
除了thread blocks之外,在GPU CC 9.0及其以上的GPU还有一个称之为Cluster。多个thread block组成一个thread block cluster,多个thread block cluster组成一个Grid。
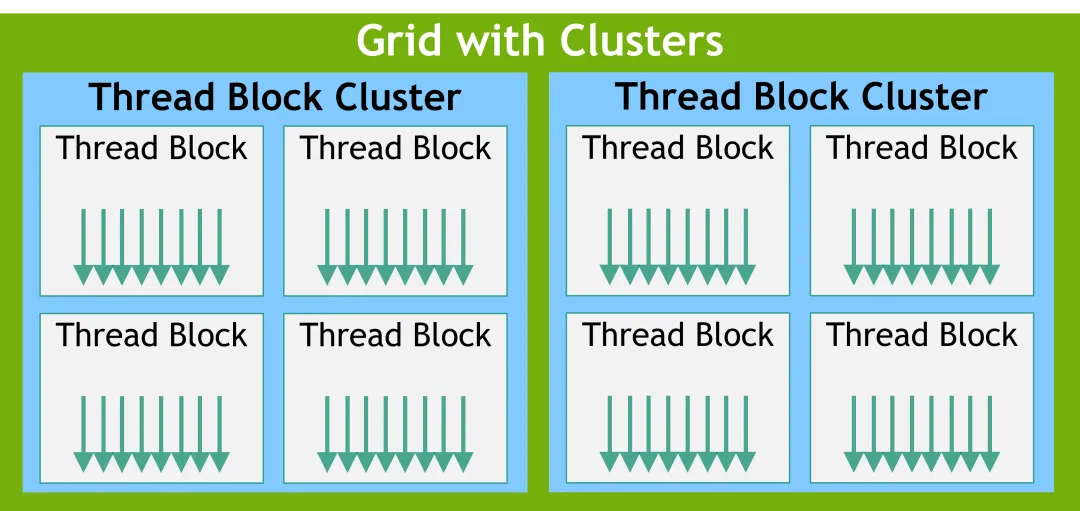
图片来源:nvidia.com
将相邻的thread block划分为一个cluster,并在cluster级别提供了更多的thread同步和通信机会。一个cluster中的所有thread block都在单个GPC中执行,由于thread block是同时在单个GPC中进行调度,因此同一cluster中的不同thread block中的thread可以使用由Cooperative Group提供的软件接口来进行通信和同步。Cluster中的thread可以访问Cluster中所有thread block的共享内存,称之为分布式共享内存。Cluster的最大大小取决于硬件,并且在不同的设备中有所不同。
下图展示了Cluster内的thread block如何在GPC内的SM上同时进行调度,Cluster中的thread block在Grid中总是彼此相邻排列。
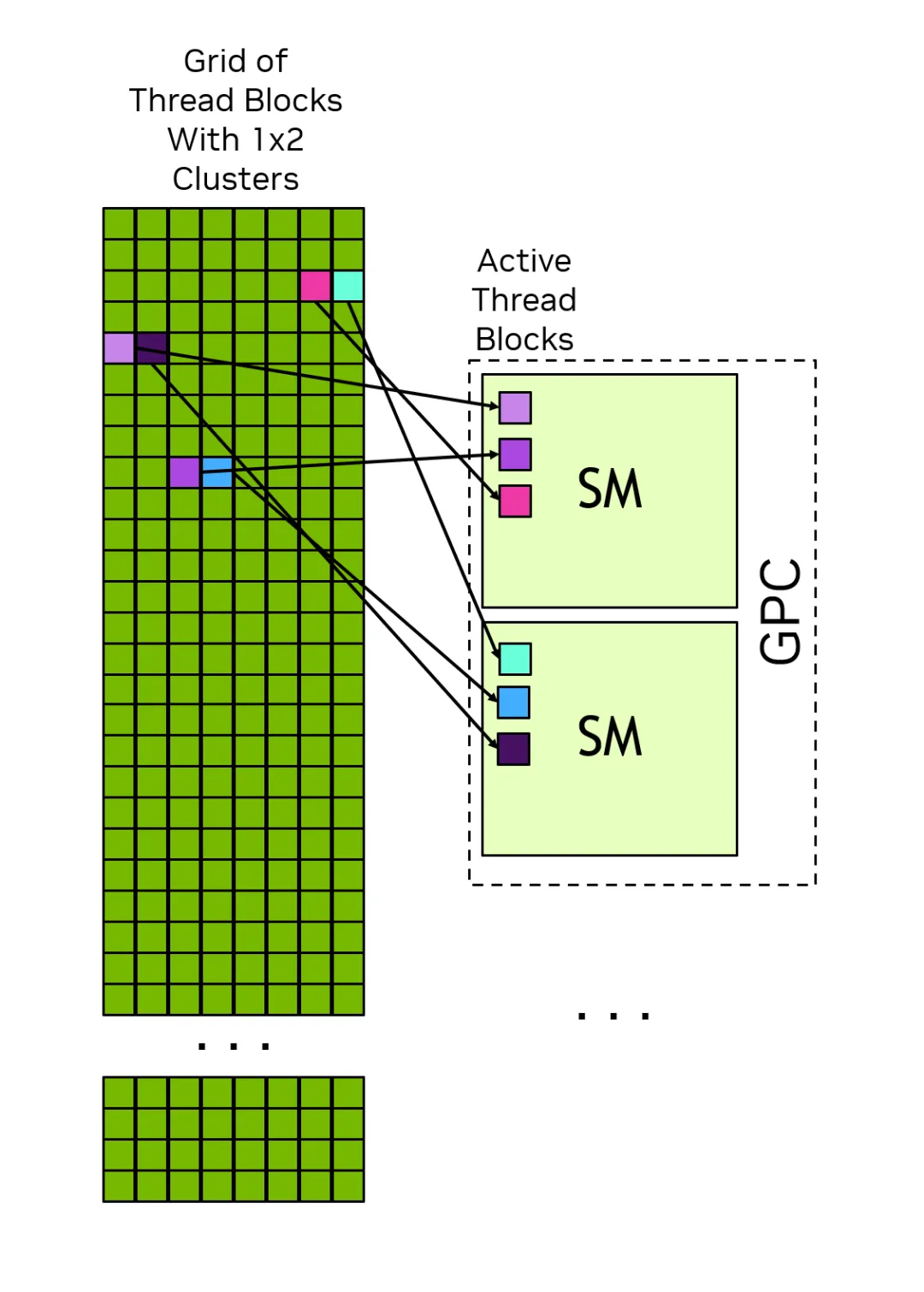
图片来源:nvidia.com
在一个thread block内,thread被组织成由32个thread组成的组,称之为warps。一个warps按照SIMT(Single-Instruction Multiple-Threads,单指令多线程)模式执行kernel函数运算,warps中的所有thread都执行相同的kernel,但是每个thread会根据不同的分支路径来执行代码,也就是说,尽管所有的thread都执行相同的代码,但是这些thread不需要遵循相同的执行路径。

图片来源:nvidia.com
内存的有效利用和计算逻辑单元的同样重要,在CPU+GPU异构环境下,有多个内存概念,下面详细介绍。
图片来源:nvidia.com
1)DRAM Memory
GPU和CPU都有直连的DRAM,即我们通常称之为内存和显存。每个GPU都有自己的内存,直连到GPU的显存我们通常称为全局内存,所有的SM都可以访问。连接到CPU的DRAM称之为系统内存或者主机内存。
与CPU一样,GPU也使用虚拟内存的寻址方式,CPU和GPU使用一个统一的虚拟内存空间,这就意味着系统内每个GPU的虚拟内存地址都是唯一的且与系统中的其他GPU都不相同。对于一个给定的虚拟内存地址,可以确定该地址是位于GPU内存还是系统内存。
2)On-Chip内存
除了每个GPU自己的全局内存,每个SM计算单元还有自己的寄存器文件和共享内存,这些内存属于SM的一部分,可以被SM内执行的thread很快的访问,但是这些内存是无法被其他SM中的thread访问的。
寄存器文件用于存储thread本地变量,这些变量通常由编译器分配。共享内存可供thread block或Cluster内的所有thread访问和数据交换。
3)缓存
与CPU一样,GPU也有自己的L1、L2级缓存,每个计算单元SM都有一个L1缓存,而L2缓存则由整个GPU内的所有SM共享。每个计算单元SM还有一个单独的常量缓存,用于缓存全局内存中在内核生命周期内被声明为常量的值。编译器也可能将内核参数放入常量内存中。
4)Unified Memory
应用程序在GPU或者CPU上显式分配内存时,该内存只能对运行在该设备上的代码可用,即CPU内存只能由CPU中运行的程序访问,GPU内存只能由运行在GPU上的代码访问,CUDA API可以在CPU和GPU内存之间将数据进行复制。
CUDA中有一个“统一内存”(unified memory)概念,运行应用程序分配GPU和CPU内存,CUDA 运行时或者底层硬件能够实现内存的访问和数据的拷贝(CPU内存和GPU内存之间)。
相关阅读(往期精选)
大模型部署系列
从单机到集群:用vLLM+Ray优雅地部署你的分布式推理集群DeepSeek-R1-0528
如何打造你的专属AI智能助手:vLLM+DeepSeek+OpenWebUI保姆级教程!大模型实战(一)环境准备
如何打造你的专属AI智能助手:vLLM+DeepSeek+OpenWebUI保姆级教程!大模型实战(二)模型部署
如何打造你的专属AI智能助手:vLLM+DeepSeek+OpenWebUI保姆级教程!大模型实战(三)模型压测
vLLM模型压缩工具llm-compressor!轻松搞定Qwen3-32B INT8量化-附详细操作实战和避坑指南(建议收藏)
为什么BF16比FP16更受欢迎?LLM大模型精度(FP32、FP16、BF16、FP8)详解!
手把手教你:如何在Docker容器中指定NVIDIA GPU设备运行CUDA程序和LLM推理模型?
AI Infra高效运维系列:
轻量级NVIDIA GPU监控方案!用开源nvidia_gpu_exporter工具打造炫酷的GPU监控面板
【收藏备用】史上最全NVIDIA主流GPU B300、B200、H200、H100、H800、H20 等参数速查表,1分钟速览
NVIDIA GPU服务器深度解析:开箱即用的DGX、OEM的HGX、超级AI集群DGX SuperPOD技术路径和生态解读
AI Infra - NVIDIA GPU高效运维(一)5分钟搞懂GPU排障利器nvidia-smi命令
AI Infra - NVIDIA GPU高效运维(二)5分钟掌握一款非常炫酷的监控工具nvitop!
AI Infra - NVIDIA GPU高效运维(三)5分钟就能搞定GPU压力测试?实用gpu-burn工具!
AI Infra - NVIDIA GPU高效运维(四)一文掌握CUDA,CUDA-Samples实战教程
AI Infra - NVIDIA GPU高效运维(五)大模型工程师都应掌握的NVIDIA集合通信库NCCL!
AI Infra - NVIDIA GPU高效运维(六)5分钟详解节点内GPU互联和通信原理-NVLink & PCIe P2P
【AI Infra运维技巧】三款命令行工具优雅地监控NVIDIA GPU运行状态!GPU故障和性能分析利器!
藏不住了!NVIDIA GPU高效管理的秘密武器:DCGM深度揭秘
10分钟顶一天!docker容器化部署监控神器、黄金搭档Prometheus+Grafana
AI Infra-如何将GPU千卡集群的运维效率提升300%?一套你必须了解的智算基础设施监控可视化秘籍
IB网络、Nvlink、RDMA、NCCL系列:
AI Infra-智算中心网络破局的关键(一):深入解析RDMA、InfiniBand与RoCEv2
AI Infra-智算中心网络破局的关键(二):基于InfiniBand的RDMA详解和实战
打破多机NVIDIA GPU通信瓶颈:NCCL over IB RDMA深度实战指南,实测突破114GB/s!
实测结果炸裂!单机8卡NVLink,NCCL性能狂飙至480GB/s,太震撼了!- 全网超详细nccl-test实战
【终于搞懂了】GPUDirect RDMA底层原理解析:为什么它能突破瓶颈,打通多机间GPU通信的“任督二脉”
GPU&InfiniBand故障系列:
AI Infra高效运维(一)NVIDIA GPU Xid相关故障分析和处理总结
https://docs.nvidia.com/cuda/cuda-programming-guide/01-introduction/programming-model.html

