敏感数据不敢传给第三方AI大模型?高峰期模型响应慢还按token氪金?其实,你完全可以把大模型“搬”回自己电脑,数据安全握在手,使用成本低!
近年来,AI大模型给金融行业带来了颠覆性变革,而本地部署AI大模型,更是解决“数据隐私焦虑”“持续付费心疼”的终极方案!它能让金融数据在内部网络里安全流转,杜绝敏感信息泄露;还能量身定制功能,精准对接财报分析、信贷风控、合规检查等金融场景,让业务流程实现“智能开挂”。这篇保姆级指南,从优势介绍→如何部署→调用案例,一步步带你解锁本地AI,爱学习的金融人快码住~
本篇干货满满~咱们马上开始!
一、本地化部署优势
比起依赖云端的在线AI,本地部署大模型简直是金融人的“量身定制款”,其存在如下优势:
对比维度 | 在线AI 大模型 | 本地部署 |
部署方式 | 云端托管,通过Web 或API 访问 | 模型下载至本地设备运行 |
网络依赖 | 必须联网 | 可完全离线运行(首次需联网下载模型) |
访问方式 | 官方App、API等 | ollama等 |
数据隐私 | 用户输入/输出经第三方服务器处理,存在泄露风险 | 所有数据保留在本地设备或内网,无外传风险 |
适用场景 | 通用问答、轻量编程、学习辅助、非敏感业务 | 知识库问答、代码生成、敏感数据处理、私有Copilot |
多模态支持 | 部分支持 | 部分支持(需额外配置,体验不如在线版) |
推理速度 | 受网络延迟影响(高峰期可能较慢) | 受硬件条件影响 |
硬件要求 | 任意设备,仅需网络 | 有一定硬件要求(建议至少 16GB 内存,NVIDIA 显卡(如 RTX 3060 以上)或 Apple M1/M2 芯片) |
模型更新 | 自动更新,用户始终使用最新版本 | 手动更新,使用门槛有一定要求 |
模型定制性 | 无法修改、微调或注入私有知识 | 支持微调、RAG、自定义system prompt等 |
使用成本 | 按token 计费或订阅制 | 一次性硬件投入后,后续边际成本趋近于零 |
入门门槛 | 极低(注册账号即可使用) | 中等(需有一定DIY能力) |
扩展性 | 受限于厂商API 限制(如速率限制、内容过滤) | 高度可扩展:可集群部署、负载均衡、自定义路由逻辑 |
·降低对外部环境依赖。即使在网络不稳定或中断的情况下,也能保证AI大模型的正常运行,因为完全运行在本地
·确保数据安全性和隐私性。所有数据都存储在本地服务器上,无需上传至云端,避免数据泄露风险
·更高的灵活性和可控性。可以根据自身需求定制、微调(Fine-tune)模型,以满足不断变化的需求
·长期成本更低,高频场景更划算。对于高频使用的金融业务场景而言,本地部署虽初期需承担较高的硬件投入成本,但后续使用中无需按使用量持续付费,边际成本会随着使用频率的增加而显著降低,长期来看性价比更高
二、如何部署
本地部署AI大模型听起来或许仍带有“高门槛”的标签,但随着开源生态的成熟,这一过程已大幅简化。以Ollama为代表的轻量级部署框架,正成为快速落地大模型的首选入口之一
什么是Ollama?— 本地大模型的“全能管家”
Ollama是一个专为本地运行开源大模型设计的开源工具,由前Apple工程师团队开发,专为在个人电脑或服务器上轻松运行开源大语言模型(LLM)而设计。它封装了模型下载、依赖管理、GPU加速、API服务等复杂环节,用户只需一条命令,即可在本地运行如Llama3、Qwen系列、Mistral、Phi-3等主流开源大模型,自发布以来,迅速成为开发者和企业用户本地部署LLM的首选工具
官网:https://ollama.com
GitHub:https://github.com/ollama/ollama
Ollama的核心优势:用过都说香
特性 | 说明 |
运行模型便捷 | 无需手动下载权重、配置依赖 |
自动GPU加速 | 支持NVIDIA CUDA、Apple Metal(Mac M系列芯片),自动调用硬件加速 |
OpenAI兼容API | 可快速对接现有RAG(检索增强生成)系统或业务中台 |
海量模型支持 | 内置Model Library,涵盖Llama 3、Qwen、Mistral、Phi-3、Gemma、等主流开源模型 |
支持量化(Quantization) | 默认使用GGUF 格式,提供4-bit/5-bit 量化版本,大幅降低显存占用 |
跨平台支持 | macOS、Windows、Linux 全覆盖 |
完全离线运行 | 首次下载后,无需联网即可推理,保障数据隐私 |
免费& 开源 | MIT许可证,可商用,无隐藏费用 |
如何下载与安装Ollama?——6 步搞定,跟着操作准没错~
步骤1:下载安装Ollama
1.打开https://ollama.com/download,根据操作系统选择对应版本(这里以Windows为例)
2.下载完成之后,会获得一个OllamaSetup.exe,双击安装
3.验证安装是否成功:安装完成后,使用win + R然后输入CMD打开终端,输入:ollama --version,能正确返回对应版本号即为安装成功(如下图的 0.13.5)

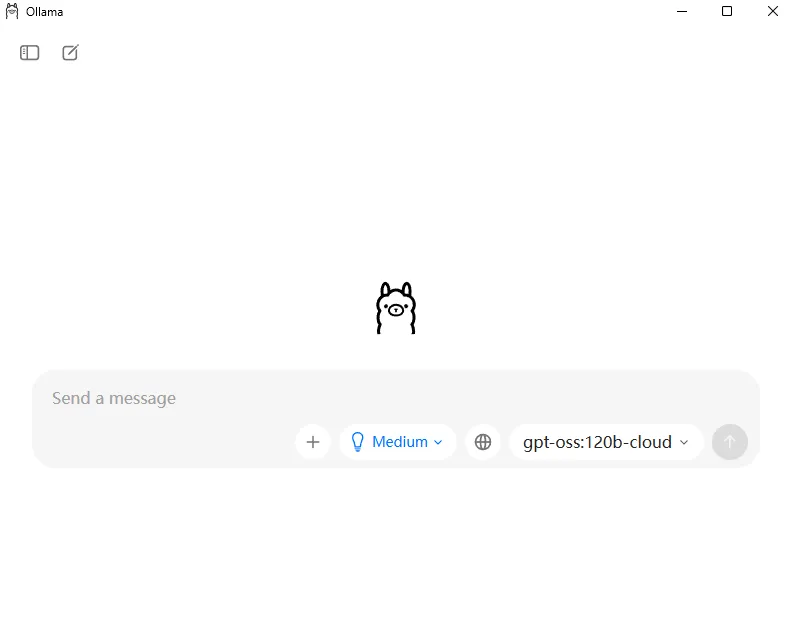
安装完成后,打开ollama,右下角可以选择模型,在默认情况下,系统可能配置了一个云端模型,此时就可以进行聊天交互(如下图),可以在聊天框内进行交互
小知识点补充:使用win + R然后输入CMD打开这东西,终端是个啥?
通过Win+R输入CMD打开的这个终端,官方叫命令提示符(Command Prompt),是 Windows 系统自带的字符式操作界面,简单说就是用文字命令控制电脑的工具,和我们平时点图标、点菜单的图形界面是两种操作电脑的方式,核心作用是通过输入纯文字指令,让电脑执行各种操作。终端操作和平时我们日常的鼠标操作区别对比如下表所示:
操作方式 | 图形界面(平时用的) | 命令提示符(CMD) |
操作手段 | 鼠标点图标、点菜单、拖曳 | 键盘输文字指令+ 按回车 |
上手难度 | 直观,一看就会 | 需记简单指令,入门稍慢 |
操作效率 | 简单操作快,复杂操作步骤多 | 复杂操作(批量处理)更高效 |
适用人群 | 普通用户 | 想简单折腾电脑、排查问题、入门电脑知识的人 |
举个栗子:
网络有问题的小伙伴经常会把IT部门的小伙伴叫来解决问题,IT部门的小伙伴来了以后一般都会有如下操作:
打开终端后,输入ipconfig:回车,查看自己电脑的网络 IP、网关等信息(排查网络问题常用)
CMD 的注意点:
1.不会轻易搞坏电脑:普通的查看、打开、清屏类指令完全无害,除非输入格式化硬盘、删除系统文件这类高危指令(新手不刻意搜、不瞎输,根本碰不到);
2.不用刻意学:新手日常用电脑,点图标就够了,CMD 只是备用工具,比如图形界面卡了、网络出问题了,用它排查会更方便;
简单总结:CMD 就是 Windows 给我们留的一个 “文字操作入口”,不用强求会用,知道它是啥、偶尔需要时能打开输个简单指令就行,是新手入门电脑基础的一个小工具~
知识点补充完毕,咱们回到正题
步骤2:修改模型储存路径
【重要】设定模型下载储存路径
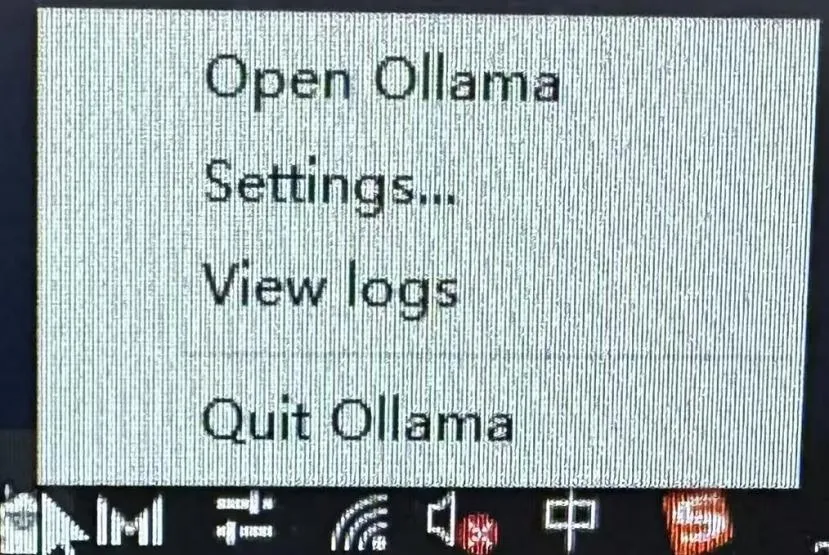
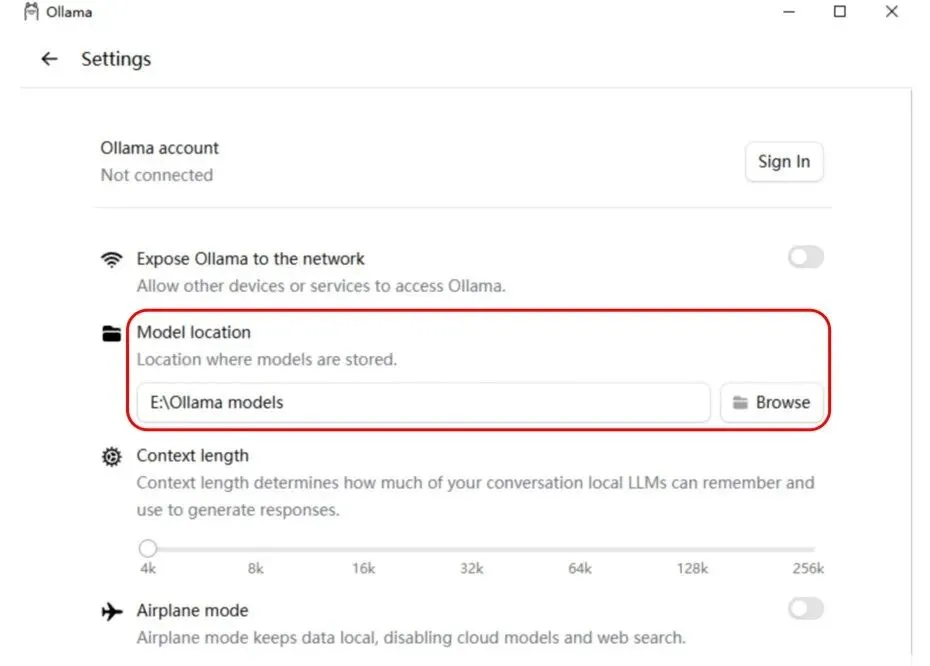
1.电脑桌面右下角点击ollama,选择setting2.在下图“Model location”处修改模型下载储存路径(以后下载的本地大模型则储存在此路径),我就选择在e盘新建一个名为“Ollama models”的文件夹,用于存储(注意这里是需要先手动在e盘新建好名为“Ollama models”的文件夹后,才可以选择)步骤3:模型拉取至本地(下载开源大模型至本地使用)
方法①:官网拉取(速度较慢)
访问官网https://ollama.com/search
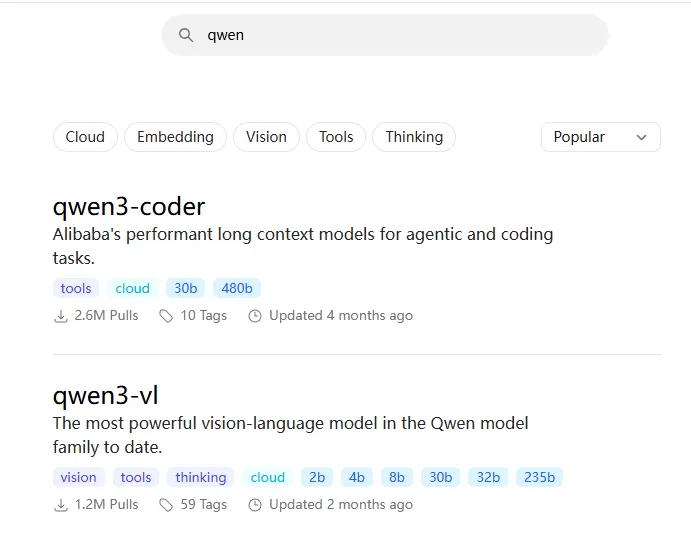
1.在上方search框内输入你想要的开源模型,选择对应参数下载(这里以qwen-coder系列为例,搜索qwen,然后点击第一个“qwen3-coder”),如下图所示:
2.如下图所示,可以看到“qwen3-coder”这个模型有不同参数版本可供下载,模型后缀30b、480b这些就是参数量的大小,越大则模型越牛,但所需硬件条件就越高
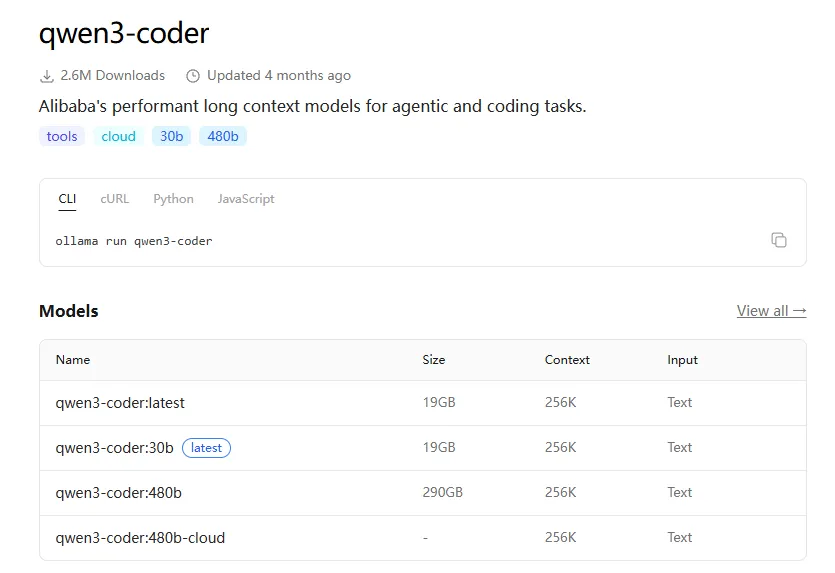
这里小伙伴们根据自己情况下载合适参数的即可,比如我想下载qwen3-coder:latest这个模型,则使用win + R然后输入CMD打开终端,输入如下命令(如下所示,红色字体部分即为下载模型名称):
ollama runqwen3-coder:latest
ollama run qwen3-coder:latest

随后则显示pulling(即下载)模型的进度,到100%即下载完成
方法②:国内镜像网站拉取(推荐)
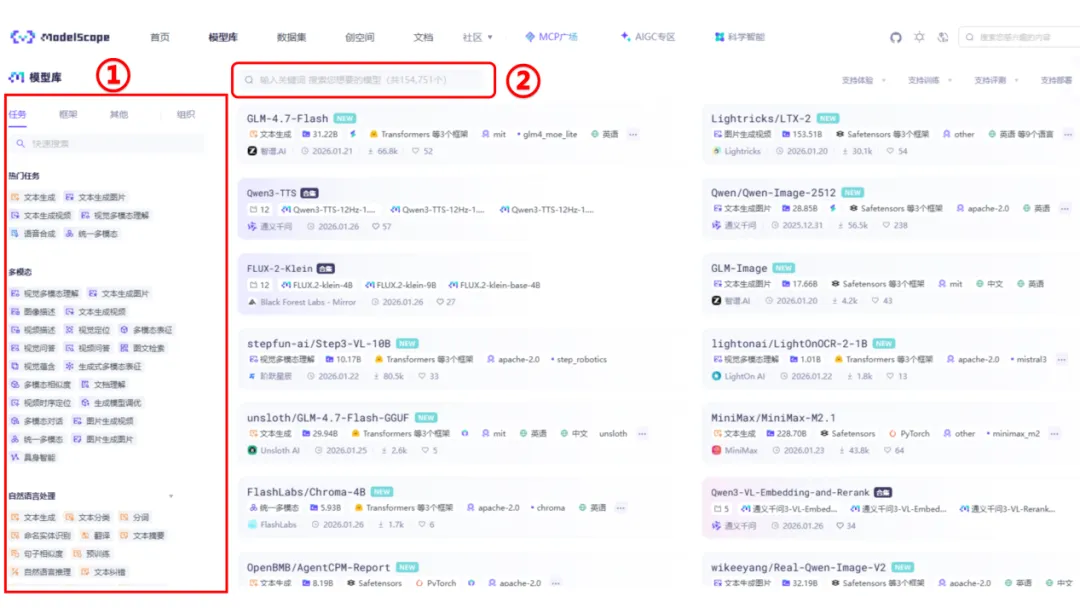
以“魔塔社区”为例
访问官网:https://modelscope.csdn.net/
Step 1:
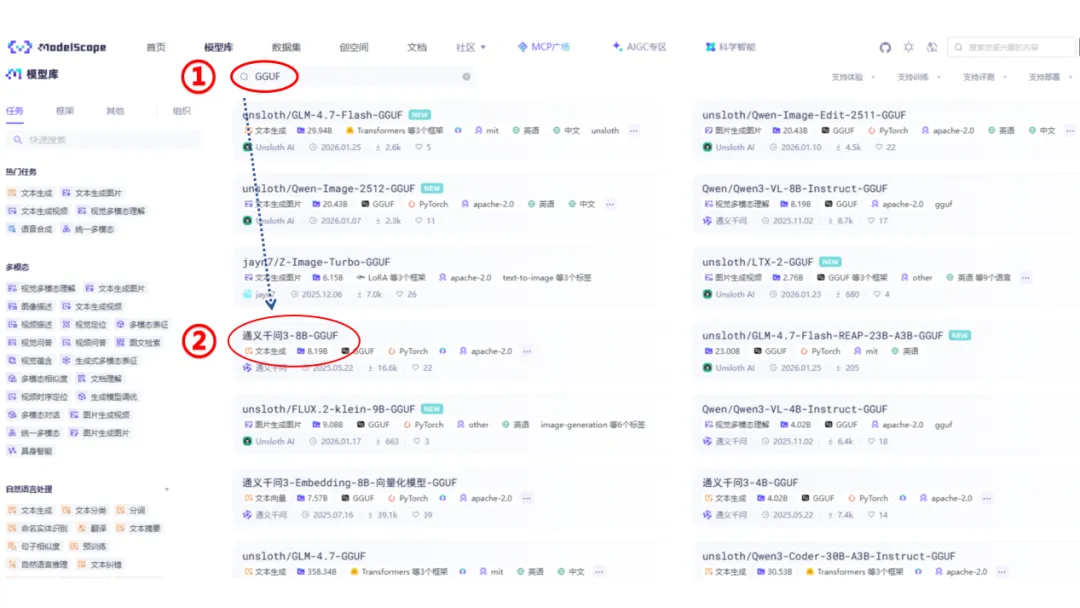
如上图所示,打开官网,搜索想要的模型:①部分为模型功能分类,②部分搜索框可以输入想要的开源模型系列,如“deepseek”“Qwen”等
注:可以在搜索框内选择带有GGUF 标签的模型仓库(Ollama 原生支持GGUF 格式),如下图所示:
Step2:
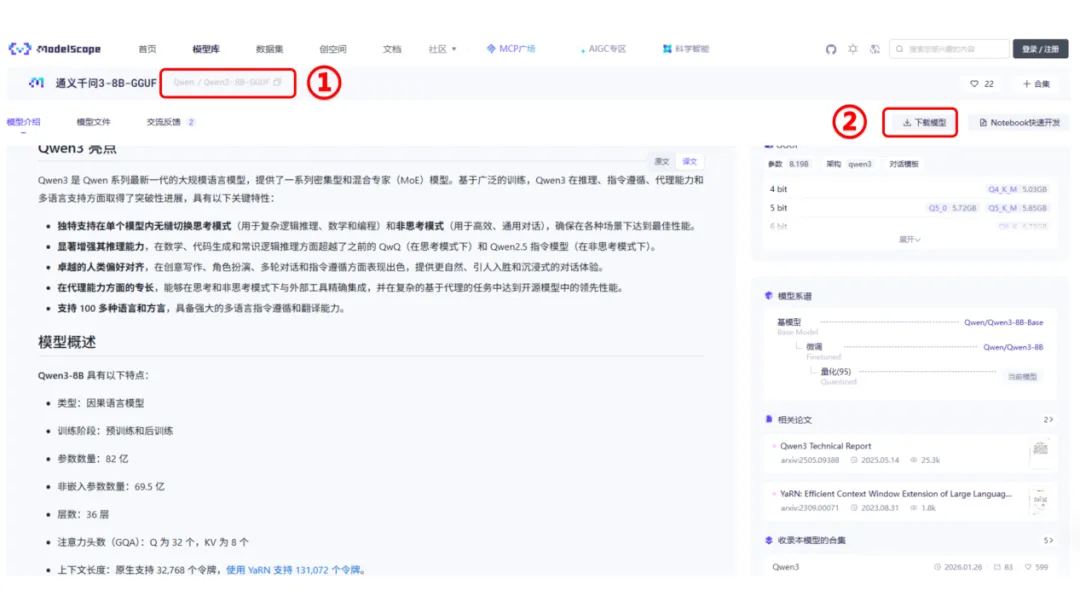
我们以图中“通义千问3-8B-GGUF”模型为例,点开对应模型链接,
复制上图①部分文字“Qwen/Qwen3-8B-GGUF”,后续使用,②部分支持其它多种方式下载,在此不详细展开
使用win + R然后输入CMD打开终端,输入如下命令(如下图所示,红色字体部分即为上方模型名称):
ollama pull ollama.modelscope.cn/Qwen/Qwen3-8B-GGUF
ollama pull ollama.modelscope.cn/Qwen/Qwen3-8B-GGUF
同理,随后则显示pulling模型的进度,到100%即下载完成
小知识点补充:为啥要选GGUF格式模型?
(给耐心看到这里的爱学习的你点赞~)
项目 | GGUF格式 | 非GGUF格式 (如 PyTorch、TensorFlow 格式) |
格式设计目标 | 是由llama.cpp项目推出的统一模型格式,专为高效本地部署设计,核心目标是:简化模型加载流程,支持跨平台(CPU/GPU、Windows/Linux/Mac)优化内存占用,适合在消费级硬件(如普通 PC、笔记本)上运行支持,在牺牲少量精度的情况下大幅减小文件体积 | 是深度学习框架原生格式,主要用于: 模型训练和微调(保留完整精度参数,便于修改网络结构)大规模分布式部署(依赖框架的优化库,如 PyTorch 的torch.distributed) |
文件体积硬件要求 | 支持量化压缩(将 32 位浮点数参数转为 4/8/16 位整数),文件体积可缩小 50%-80%。如未量化的8B模型约 16GB(FP16)量化为Q4后仅需4-5GB,普通电脑内存即可运行对硬件要求低,无需高端GPU,甚至可在CPU上流畅运行 | 通常保留高精度参数(FP32/FP16),文件体积大(8B 模型约 16-32GB)依赖 GPU 加速(如 NVIDIA CUDA),否则在 CPU 上运行极慢 |
适用工具场景 | 适配轻量级推理框架:llama.cpp、Ollama、 llama-cpp-python等 适合场景:本地部署、嵌入式设备、低资源环境下的快速推理(如聊天机器人、嵌入模型) | 依赖重型深度学习框架:PyTorch、TensorFlow、Hugging Face Transformers 适合场景:模型训练 / 微调、学术研究、需要调用复杂框架功能(如梯度计算、自定义层)的场景 |
兼容性与转换 | GGUF 是后验格式,通常由非 GGUF 模型转换而来(如用convert.py工具将 PyTorch 模型转为 GGUF) | 非 GGUF 格式(如 PyTorch)是源头格式,几乎所有模型库(Hugging Face 等)都会优先提供该格式 |
总结 | 如果需求是本地快速部署、节省硬件资源(如用 Ollama 运行模型),优先选择 GGUF 格式 | 如果需要训练 / 微调模型或依赖特定框架功能,使用 PyTorch 等原生格式。两者可以通过工具互相转换,但 GGUF 的轻量化优势使其成为本地推理的首选 |
知识点补充完毕,咱们回到正题
步骤4:验证大模型成功下载
下载完成后,使用win + R然后输入CMD打开终端,输入如下命令:
ollama list
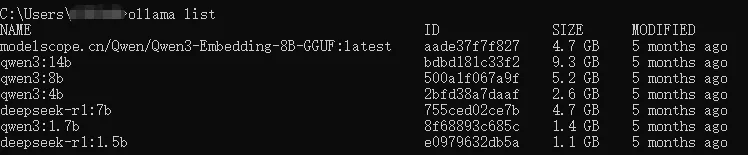
可以看到下载到本地的大模型(如上图所示),显示对应下载模型的名字即为成功(这里我没下载前面所举例的“Qwen/Qwen3-8B-GGUF”模型,所以没有显示)
注:上图中可以看到,从魔塔社区下载的模型名称都比较长,而其余命名较为简洁的模型则是我从Ollama官网拉取的,所以我们下一步介绍如何修改模型的名称,方便管理
步骤5:修改大模型名称
1.从魔塔社区下载的大模型名称比较冗长,比如上图中的“modelscope.cn/Qwen/Qwen3-Embedding-8B-GGUF:latest”,我们把它进行修改为“qwen3-emb:8b”,方便后续调用
注:Ollama 的默认标签机制即模型名称的统一格式为“模型名:标签”,Ollama 不支持「无标签」的模型名,比如想只保留 qwen3-emb-8b 是做不到的 —— 这是 Ollama 的底层设计规则,所有模型必须有“模型名:标签”结构
2.重命名——重命名(ollama cp)本质是“新增标签”
使用win + R然后输入CMD打开终端,输入如下命令进行修改名称(红色字体部分为原模型名称,绿色字体为修改后的名称):
ollama cp modelscope.cn/Qwen/Qwen3-Embedding-8B-GGUF:latestqwen3-emb:8b
ollama cp modelscope.cn/Qwen/Qwen3-Embedding-8B-GGUF:latest qwen3-emb:8b
再次输入ollama list查看,如下图所示:
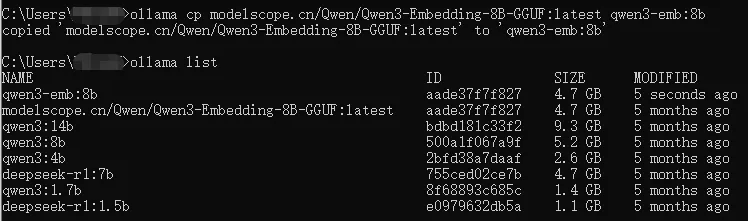
可以看到多了一个名为“qwen3-emb:8b”,它相当于创建了一个新的“模型标签”(tag),让它指向和原模型完全相同的底层数据。类似给一个人办了两张身份证(名字不同,但人是同一个),此步骤不会额外占用磁盘空间(不是复制粘贴了一个大模型然后改名字,无须担心)
3.【或有】删除原长名称模型
继续在终端内输入如下命令(红色字体部分即为想删除的模型标签,rm 是 remove 的缩写):
ollama rm modelscope.cn/Qwen/Qwen3-Embedding-8B-GGUF:latest
ollama rm modelscope.cn/Qwen/Qwen3-Embedding-8B-GGUF:latest
注:执行 ollama rm,当一个模型存在多个“身份证”时,如果删掉了 “旧身份证”,但 “新身份证(新名称)” 还在,模型底层数据依然存在,你还能通过新名称使用这个模型,不会丢失;但如果某个模型只有一个名称(标签),执行ollama rm,就相当于把这个人的所有身份证都销毁了,模型底层数据会被彻底删除,磁盘空间被释放,无法恢复
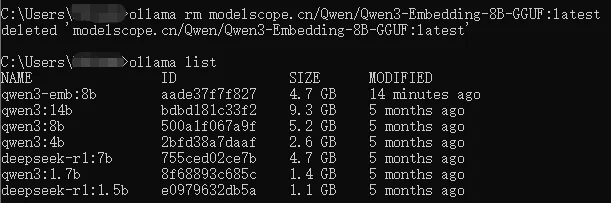
再次输入ollama list查看,可以看到原来名称为“modelscope.cn/Qwen/Qwen3-Embedding-8B-GGUF:latest”的模型已被删除,如下图所示:
至此大模型下载+改名步骤已全部搞定
步骤6:模型管理,想删想留自己定
1.如果想删除已下载的大模型,则就可以在终端输入如下命令:
ollama rm 模型名称:标签
例如:ollama rm qwen3-emb:8b
2.如果想删除多个模型,依次执行ollama rm命令即可,比如:
ollama rm qwen3:8b
ollama rm qwen3:4b
ollama rm deepseek-r1:7b
……
ollama rm qwen3:8bollama rm qwen3:4b ollama rm deepseek-r1:7b
3.删除完成后再执行ollama list验证,确保模型已被移除
【总结】:
①删除不可逆:模型删除后会释放磁盘空间,但无法恢复,需确认确实不需要该模型再执行
②删除前确保模型未运行:如果模型正在被调用(比如通过 API、WebUI 使用),先关闭相关程序,再执行删除命令,避免报错
③【重要】:和前面“【或有】删除原长名称模型”相比的区别:
如果ollama中的模型你执行“ollama cp”改了名字,它相当于创建了一个新的“模型标签”(tag),让它指向和原模型完全相同的底层数据。类似给一个人办了两张身份证(名字不同,但人是同一个),再删除原有的模型名字,则模型还是会保留,相当于去掉了一个多余的身份证,但还保留一个身份证,还可以找到人(大模型)
但如果本来就一个模型,删除后就真的删除了。即:删除唯一名称的模型 = 彻底删除模型:如果某个模型只有一个名称(标签),执行ollama rm,就相当于把这个人的所有身份证都销毁了,模型底层数据会被彻底删除,磁盘空间被释放,无法恢复
三、如何调用/使用
模型下载好后,怎么用起来?两种方法,不管是想快速聊天,还是想对接业务场景,都能满足!
经过前面的步骤,我们已经下载好了大模型到本地,现在开始调用(所有可本地调用的模型就用前面说过的“使用win + R然后输入CMD打开终端,再输入ollama list”查看,如下图所示)
下面开始调用
方法①:直接在ollama软件内调用
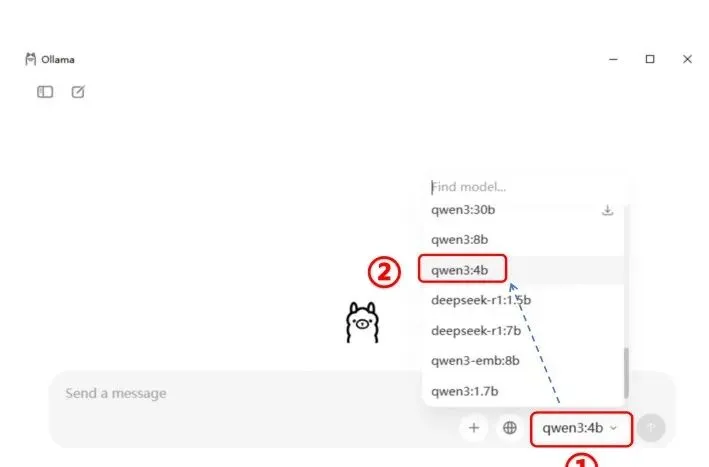
右下角找到ollama,右键点击“Open Ollama”,打开后在右下角选择你下载好的模型,即可使用,这里以我提前下载好的“qwen3:4b”模型为例
随后在对话框内即可开始对话,如下图所示:
可以看到,4b模型的效果一般(让我有种想找帽子叔叔的冲动...),如果硬件条件好可以用更大的模型,效果会更好
方法②:代码脚本内调用(使用场景丰富、定制化程度高)
我们使用Jupyter Notebook为例,语言为Python,注意在脚本调用过程中须全程保持ollama正常运行(相信卷卷的你早就知道了什么是 Jupyter Notebook 和 Python ~)
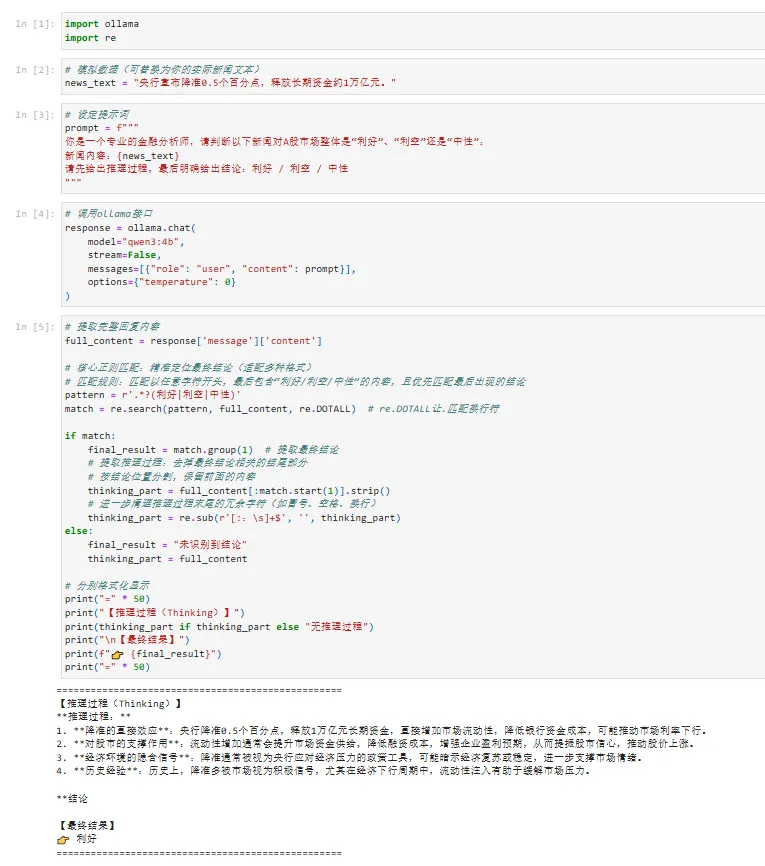
✅ 示例 1:新闻情感分析(判断利好/利空)
import ollamaimport re# 模拟数据(可替换为你的实际新闻文本)news_text = "央行宣布降准0.5个百分点,释放长期资金约1万亿元。"# 设定提示词prompt = f"""你是一个专业的金融分析师,请判断以下新闻对A股市场整体是“利好”、“利空”还是“中性”:新闻内容:{news_text}请先给出推理过程,最后明确给出结论:利好 / 利空 / 中性"""# 调用ollama接口response = ollama.chat( model="qwen3:4b", stream=False, messages=[{"role": "user", "content": prompt}], options={"temperature": 0})# 提取完整回复内容full_content = response['message']['content']# 核心正则匹配:精准定位最终结论(适配多种格式)# 匹配规则:匹配以任意字符开头,最后包含“利好/利空/中性”的内容,且优先匹配最后出现的结论pattern = r'.*?(利好|利空|中性)'match = re.search(pattern, full_content, re.DOTALL) # re.DOTALL让.匹配换行符if match: final_result = match.group(1) # 提取最终结论 # 提取推理过程:去掉最终结论相关的结尾部分 # 按结论位置分割,保留前面的内容 thinking_part = full_content[:match.start(1)].strip() # 进一步清理推理过程末尾的冗余字符(如冒号、空格、换行) thinking_part = re.sub(r'[::\s]+$', '', thinking_part)else: final_result = "未识别到结论" thinking_part = full_content# 分别格式化显示print("=" * 50)print("【推理过程(Thinking)】")print(thinking_part if thinking_part else "无推理过程")print("\n【最终结果】")print(f"👉 {final_result}")print("=" * 50)
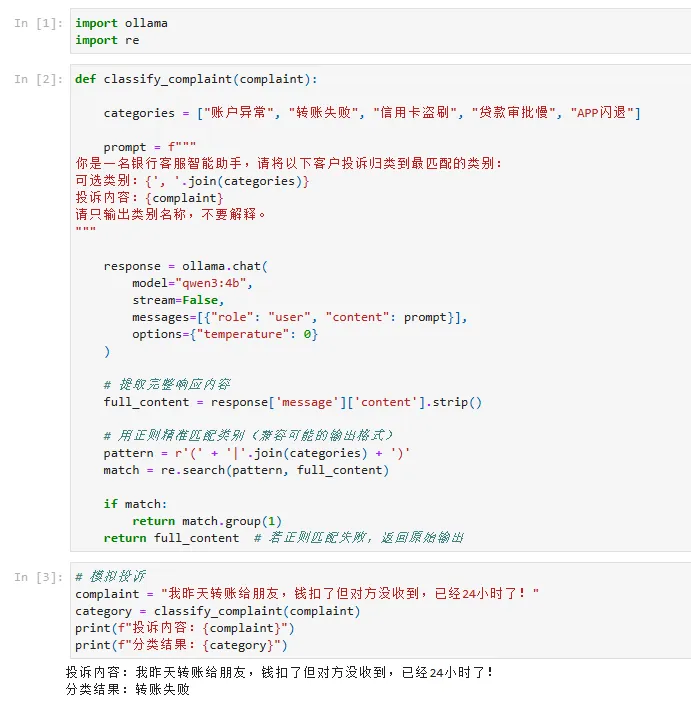
✅ 示例 2:客户投诉自动分类(银行客服场景)
import ollamaimport redef classify_complaint(complaint): categories = ["账户异常", "转账失败", "信用卡盗刷", "贷款审批慢", "APP闪退"] prompt = f"""你是一名银行客服智能助手,请将以下客户投诉归类到最匹配的类别:可选类别:{', '.join(categories)}投诉内容:{complaint}请只输出类别名称,不要解释。""" response = ollama.chat( model="qwen3:4b", stream=False, messages=[{"role": "user", "content": prompt}], options={"temperature": 0} ) # 提取完整响应内容 full_content = response['message']['content'].strip() # 用正则精准匹配类别(兼容可能的输出格式) pattern = r'(' + '|'.join(categories) + ')' match = re.search(pattern, full_content) if match: return match.group(1) return full_content # 若正则匹配失败,返回原始输出# 模拟投诉complaint = "我昨天转账给朋友,钱扣了但对方没收到,已经24小时了!"# 调用函数category = classify_complaint(complaint)print(f"投诉内容:{complaint}")print(f"分类结果:{category}")
效果如下图:
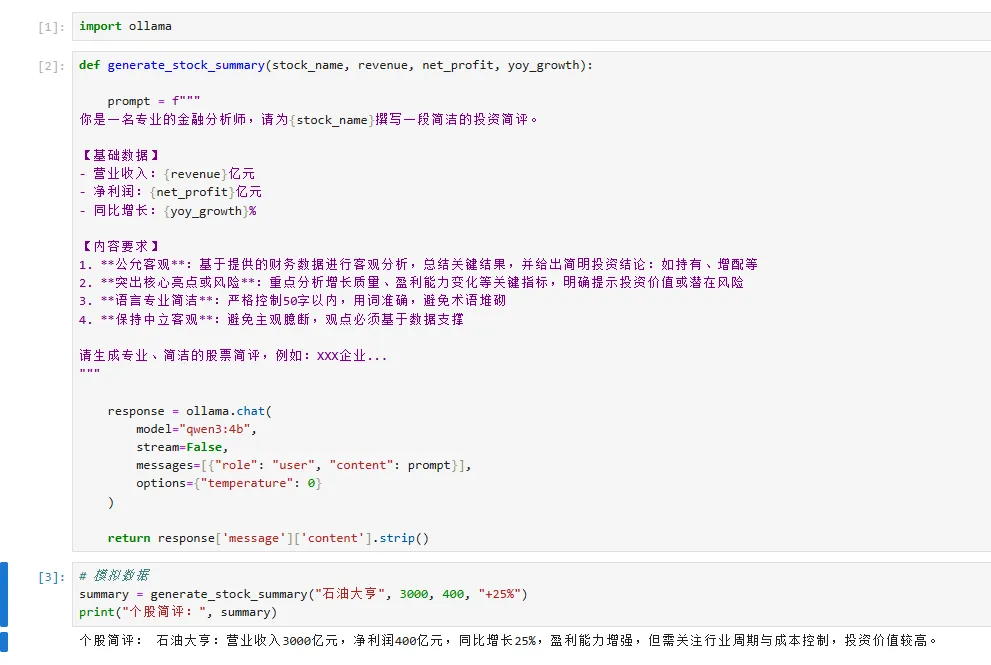
✅ 示例 3:生成个股简评(基于财报数据)
import ollamadef generate_stock_summary(stock_name, revenue, net_profit, yoy_growth): prompt = f"""你是一名专业的金融分析师,请为{stock_name}撰写一段简洁的投资简评。【基础数据】- 营业收入:{revenue}亿元- 净利润:{net_profit}亿元- 同比增长:{yoy_growth}%【内容要求】1. **公允客观**:基于提供的财务数据进行客观分析,总结关键结果,并给出简明投资结论:如持有、增配等2. **突出核心亮点或风险**:重点分析增长质量、盈利能力变化等关键指标,明确提示投资价值或潜在风险3. **语言专业简洁**:严格控制50字以内,用词准确,避免术语堆砌4. **保持中立客观**:避免主观臆断,观点必须基于数据支撑 请生成专业、简洁的股票简评,例如:XXX企业...""" response = ollama.chat( model="qwen3:4b", stream=False, messages=[{"role": "user", "content": prompt}], options={"temperature": 0} ) return response['message']['content'].strip()# 模拟数据summary = generate_stock_summary("石油大亨", 3000, 400, "+25%")print("个股简评:", summary)
效果如下图:
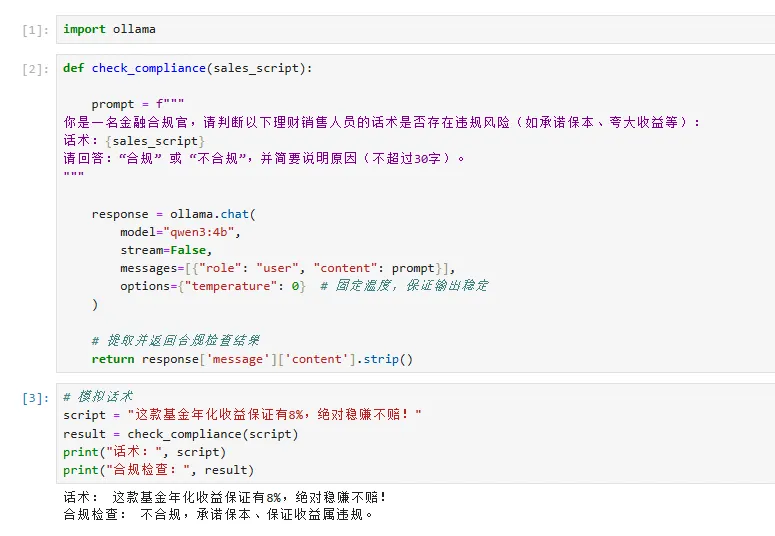
✅ 示例 4:合规话术检查(防止销售误导)
import ollamadef check_compliance(sales_script): prompt = f"""你是一名金融合规官,请判断以下理财销售人员的话术是否存在违规风险(如承诺保本、夸大收益等):话术:{sales_script}请回答:“合规” 或 “不合规”,并简要说明原因(不超过30字)。""" response = ollama.chat( model="qwen3:4b", stream=False, messages=[{"role": "user", "content": prompt}], options={"temperature": 0} # 固定温度,保证输出稳定 ) # 提取并返回合规检查结果 return response['message']['content'].strip()# 模拟话术script = "这款基金年化收益保证有8%,绝对稳赚不赔!"result = check_compliance(script)print("话术:", script)print("合规检查:", result)
效果如下图:
通过几个金融场景的代码示例可以看到,本地化AI部署的价值远不止“数据安全”—— 它能真正融入金融业务的核心环节,成为高效、合规的“私有工具”。无论是快速处理敏感的财报数据、自动化完成客户投诉分类,还是在合规框架内生成投资简评、排查销售话术风险,本地大模型都能以“零数据外泄”“零额外付费”的优势,解决线上AI难以覆盖的痛点
对于金融从业者而言,这不再是复杂的技术尝试,而是触手可及的效率升级:无需依赖技术团队,自己就能通过Ollama快速部署模型,结合业务需求编写简单脚本,就能让AI适配财报分析、信贷风控、客户服务、合规检查等多样化场景。而且随着使用深入,你还可以通过微调模型、接入私有知识库(RAG)等方式,让本地 AI 更懂你的业务逻辑 —— 比如训练它熟悉公司内部的风控标准、产品信息,甚至行业专属术语,成为专属的“金融 AI 助手”
如果你已经跟着前面的步骤完成了部署和调用,不妨试着将实际工作中的数据替换掉示例中的模拟数据,亲身感受本地AI的便捷;如果还未动手,不妨从最简单的Ollama安装和模型拉取开始,一步步解锁本地化AI的更多可能。
最后,恭喜看到这里的卷卷的你,更加厉害啦~ 又get了一项硬核技能!
至此,关于ollama基础的使用及模型下载、调用等入门介绍完毕,Fintech系列后续会持续更新,敬请期待~