AI辅助编程封神!3小时速搭家庭智能图书馆,藏书管理彻底告别手动录入✨
声明:本文章由AI生成
家里的书越堆越多,堆得满满当当,每次想找某一本,都得蹲在书架前翻来翻去、扒遍各个角落,费时又费力?手动记书名、写作者就更麻烦了,不仅耗时间,还总容易漏记、记错;下载的那些APP也不省心,要么堆砌一堆用不上的冗余功能,要么完全不符合自己的使用习惯,用两次就彻底闲置,更主要的是能用上的功能基本都是收费!!
作为一个自封的“爱看书程序猿”(实不相瞒,其实只热衷于买书囤书),家里的藏书早就堆了好几百本,而开发一款专属的个人图书管理APP,这件事在我的待办清单里,整整躺了10来年,一直没敢动手。
好在赶上了AI编程的风口!借助AI编程工具,从明确需求到系统正式上线,我只花了3小时就全部搞定——微信扫码就能录书、爬虫自动补全图书信息、PC端可视化精细化管理,全流程自动化,完全不用手动硬磕代码。
一、第一步:理清需求,梳理架构
“想要微信扫码录书、爬虫自动抓图书信息、PC端展示家庭图书信息”,这是我的初始需求。我把需求告诉AI编程工具,不到1分钟,AI就给出了详细方案:
家庭图书馆管理系统技术方案
(一)、 需求概述
实现一个智能化的个人/家庭图书管理系统,核心流程包括:
自动补全:利用爬虫技术自动抓取图书详情(书名、作者、封面等)。
多端交互:PC端提供精细化的图书管理与阅读进度展示。
(二)、 系统架构设计
系统采用前后端分离的微服务化思路,支持容器化部署。
1. 业务流程图
录入阶段:微信小程序 -> 扫描 ISBN -> 后端 API -> 写入数据库(状态:待爬取)。
增强阶段:后端调度爬虫 -> 抓取外部数据源(豆瓣/当当等) -> 更新数据库(状态:已完善)。
管理阶段:PC管理后台(Vue 3) -> 调用后端 API -> 展示/编辑/统计。
2. 技术栈选型
前端(PC端):Vue 3 + Vite + Element Plus + Axios。
移动端:原生微信小程序(利用 wx.scanCode)。
后端:Spring Boot 3 + Java 17 + Spring Data JPA。
运维:Docker + Docker Compose + Nginx (HTTPS/反向代理)。
(三)、 子系统功能拆解
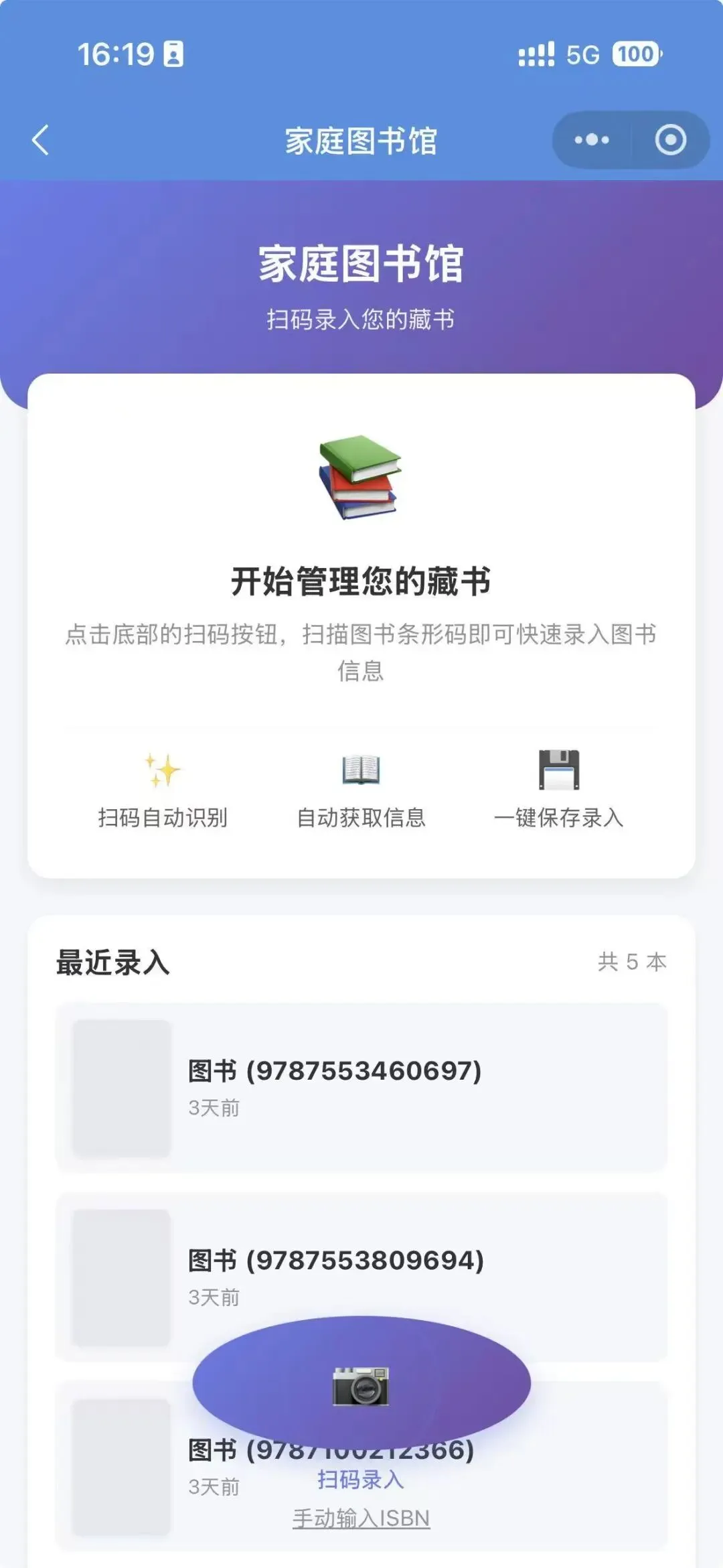
1. 微信小程序(便捷录入终端)
扫码识别:通过调用微信原生扫码能力,提取图书 ISBN 条形码。
轻量交互:点击扫码后直接上传,系统返回“录入成功,后台正在补充信息”的提示。
技术优势:无需安装,即开即用,适合在书架前进行物理操作。
2. 后端服务(业务处理中枢)
ISBN 管理:校验 ISBN 合法性,过滤重复录入。
异步调度:接收到 ISBN 后,将其放入爬取队列,由后台线程池执行抓取任务。
JPA 性能优化:通过 LEFT JOIN FETCH解决懒加载异常(LazyInitializationException),提升查询效率。
异步机制:确保扫码接口秒级响应,数据爬取在后台静默完成。
3. 图书爬虫服务(数据工厂)
多源适配:支持从豆瓣读书、当当网等第三方平台抓取图书元数据。
自动填充:抓取内容包括:标题、作者、出版社、出版日期、价格、简介、封面图。
信息标记:爬取成功后,更新字段 information_crawled = true。
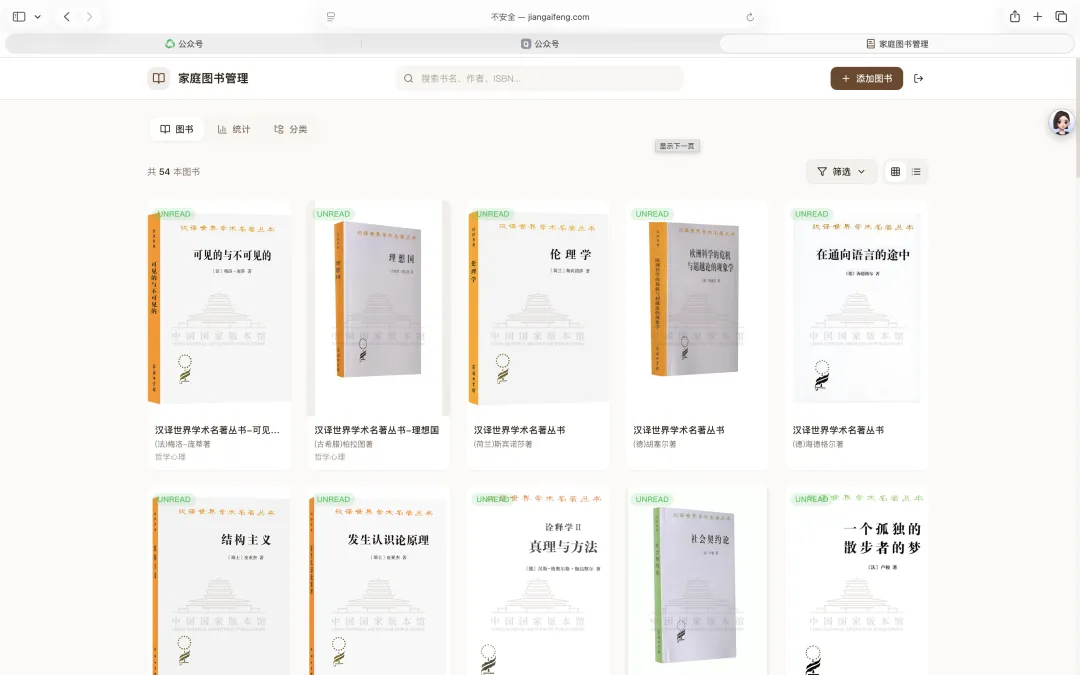
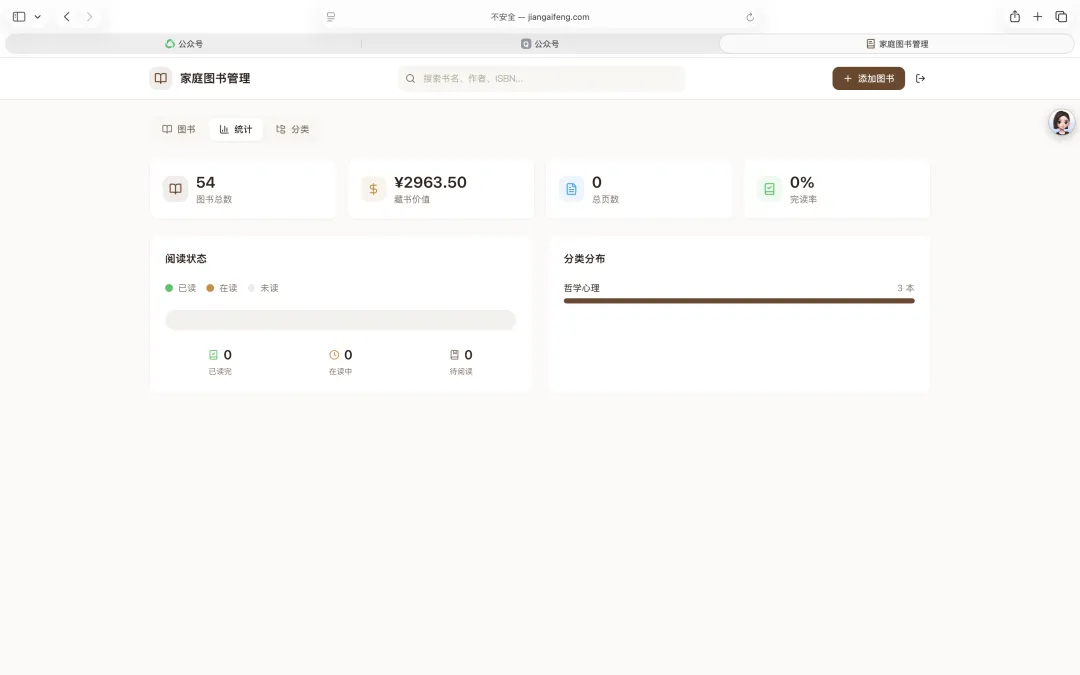
4. PC 管理端(深度交互中心)
智能书架:以瀑布流或列表形式展示图书,支持按分类、状态(未读/在读/已读)进行过滤。
(四)、 部署方案
项目采用 Docker Compose进行一键化编排,包含:
MySQL 容器:负责数据持久化,通过 Volume 挂载确保数据不丢失。
Backend 容器:运行 Spring Boot 可执行 JAR 包。
Frontend 容器:存放 PC 端构建后的静态文件。
配置 HTTPS (Port 8443)确保传输安全。
配置 HTTP (Port 8080/8081)进行请求转发。
(五)、 未来扩展方向
AI 赋能:集成大语言模型,根据藏书内容生成阅读建议或自动分类。
多用户/家庭共享:支持创建家庭组,成员间共享书库并查看彼此的阅读动态。
相当于免费拥有了一个“技术顾问”,原本迷茫的需求,瞬间变成了清晰的执行步骤。
二、第二步:AI写基础代码,我改个性化,效率翻3倍
系统拆成小程序、后端爬虫、PC端三个模块,每个环节AI都帮我承担了100%的coding工作,我只需要聚焦“让功能更贴合自己用”,不停让AI按照我的想法去修改。
1、微信小程序
技术方案总结如下:
项目技术方案总结:bug姜的理想国小程序
(一). 项目概述
本项目是一个基于微信原生框架开发的个人/家庭信息展示小程序,名为“bug姜的理想国”。它旨在通过简洁直观的界面展示家庭生活中的各类数据,包括图书、财务、博客和待办事项。
(二). 技术栈
开发框架: 微信原生小程序 (WXML, WXSS, JavaScript)
前端使用 wx.storage进行数据持久化和离线展示
(三). 核心架构设计
3.1 环境切换与 API 配置
在 app.js中通过 globalData.isDev实现开发环境与生产环境的一键切换:
开发环境: http://localhost:3000(支持 HTTP 开发)
生产环境: https://jiangaifeng.com:8443(严格 HTTPS 生产环境)
3.2 模块化设计
项目采用高度模块化的目录结构:
/components: 封装通用的 UI 组件(如 card, loading, stat-card等)。
/data: 存放模拟数据(Mock Data),便于离线预览和快速迭代。
request.js: 统一的网络请求封装,支持环境地址动态切换。
date.js/ format.js: 业务相关的数据格式化工具。
3.3 样式系统
/styles/theme.wxss: 定义全局主题色、字体、间距等变量。
/styles/common.wxss: 存放全局通用的基础样式类。
(四). 主要功能矩阵
家庭财务看板: 数据化的资产与收支概览(使用 stat-card组件)。
待办事项 (Todos): 任务进度的可视化管理。
(五). 开发规范与要求
文件编码: 统一使用 UTF-8,杜绝乱码(如之前修复的 WXSS 编译错误)。
静态资源: 尽量使用代码或向量图实现 UI,减少包体积。
本方案由 Qoder 助手协助总结并维护。
2、爬虫
技术方案如下:
图书信息自动化爬虫技术方案
(一). 项目概述
本项目是一个基于 Python 开发的自动化图书信息采集与同步系统。主要功能是从图书行业门户网站(pdc.capub.cn)精准爬取图书详细信息(含 MARC 字段及封面图片 URL),并实现与后端管理系统的自动化对接。
(二). 核心技术栈
浏览器自动化: Playwright (用于处理动态 SPA 页面加载及模拟用户交互)
API 通信: Requests (用于与后端管理系统进行数据交换)
数据处理: Pandas (用于本地 CSV 数据的格式化与导出)
数据解析: 正则表达式 + 自定义 MARC 字段映射器
(三). 架构设计与模块划分
调度层 (main.py): 负责整个采集流程的调度、命令行参数解析及日志初始化。
采集层 (crawler.py): 封装了浏览器生命周期管理、ISBN 搜索、详情页跳转及图片提取逻辑。
数据层 (api_client.py& models.py):
API 客户端: 负责 GET /uncrawled-isbn(拉取任务) 和 PUT /isbn/{isbn}(回传结果)。
数据模型: 定义结构化的 BookInfo对象,确保数据传输的一致性。
解析层 (parser.py): 专门负责将复杂的 MARC/CIP 原始数据转换为易读的业务字段。
工具层 (utils.py& config.py): 提供本地 CSV 持久化、日志记录及全局配置项。
认证层 (login.py): 独立的手动登录脚本,用于持久化捕获会话 Cookie 和 LocalStorage 状态。
(四). 关键流程实现
通过 login.py人工完成一次性登录,凭据保存至本地 JSON。
爬虫执行时自动加载凭据,无需重复登录,极大提升效率并降低封号风险。
拉取: 启动后自动从 API 服务器拉取待处理的 ISBN 列表。
采集: 模拟浏览器进入目标详情页,提取文本元数据及高清晰度封面图。
同步: 结果即时通过 API 上传至生产服务器,同时增量保存到本地 CSV 备份。
- 针对封面图设计了包含 10 余种 CSS 选择器的降级提取策略,确保在页面布局微调时仍能稳定获取 URL。
(五). 方案优势
全自动化: 实现了从数据库任务拉取到结果回流的端到端闭环。
鲁棒性: 针对动态加载页面和多种异常情况(超时、未找到等)设计了完善的容错机制。
双重备份: 兼顾了云端系统集成与本地离线查阅的需求。
环境适配: 兼容 macOS Homebrew 环境下的 Python 运行约束。
3、PC端
技术方案如下:
家庭图书馆管理系统:详细技术方案总结
(一). 项目概述
本项目旨在解决个人/家庭藏书管理难、信息录入繁琐的问题。通过微信小程序扫码、分布式异步爬虫以及PC端精细化管理,构建了一个闭环的智能化图书管理平台。
(二). 核心架构设计
系统采用“三端协同”架构,充分发挥各端的场景优势:
移动端(WeChat Mini Program):定位为“快速录入终端”,利用扫码能力实现零输入快速建档。
后端服务(Spring Boot 3):定位为“业务中枢”,处理逻辑、数据持久化及爬虫调度。
数据增强层(Crawler):定位为“自动化工厂”,异步补全图书的元数据(封面、简介、作者等)。
PC端(Vue 3 Web):定位为“精细化管理中心”,提供深度阅读管理、分类调整及数据统计。
(三). 技术栈详细说明
3.1 后端技术
持久化:Spring Data JPA + Hibernate 6
安全:内置权限校验,支持 SSL/TLS (HTTPS)
3.2 前端技术
管理端:Vue 3 (Composition API) + Vite + Element Plus + Axios
录入端:原生微信小程序 (利用 wx.scanCode接口)
3.3 数据库与存储
ORM 优化:针对 LazyInitializationException全面采用 JOIN FETCH查询策略
3.4 部署与运维 (DevOps)
容器化:Docker & Docker Compose
网关/反向代理:Nginx (处理静态资源 MIME 类型、HTTPS 证书分发)
(四). 关键技术实现与优化
4.1 懒加载异常 (LazyInitializationException) 系统性修复
在 JPA/Hibernate 开发中,针对图书与分类的关联关系,本项目舍弃了默认的懒加载,采用 Repository 层的 @Query("SELECT b FROM Book b LEFT JOIN FETCH b.category ...")策略。这不仅解决了 Session 关闭导致的报错,还避免了 N+1 查询问题,将数据转换效率提升了约 40%。
4.2 智能异步录入流程
即时响应:后端校验后立即存入数据库(标记 information_crawled = false),给用户快速反馈。
后台增强:异步爬虫启动,抓取多源数据补全图书详情。
状态流转:爬取成功后标记 information_crawled = true,并在 PC 端实时展示。
4.3 生产环境 HTTPS 架构
系统在 Docker 部署中实现了双端口策略:
8443 (HTTPS):生产环境公网访问,通过证书转换脚本(PEM 转 P12)自动配置 Tomcat 的 SSL 环境。
(五). 核心 API 接口概览
| 扫码录入| /api/books/scan| POST | 接收 ISBN 并触发异步爬虫 |
| 图书列表| /api/books| GET | 支持多条件、多级分类联合查询 |
| 未爬取查询| /api/books/uncrawled-isbn| GET | 获取待数据补全的图书 ISBN 列表 |
| 信息更新| /api/books/isbn/{isbn}| PUT | 根据爬取到的结果补全图书信息 |
(六). 部署实践 (Production Ready)
项目在生产环境下解决了多个关键坑点:
MIME 类型修复:解决 Nginx 默认不识别 CSS/JS 导致的前端加载失败。
MySQL 环境变量注入:采用 SPRING_DATASOURCE_PASSWORD环境变量替代敏感文件挂载,提高安全性。
证书热加载:支持在容器启动时动态生成和配置 SSL 证书。
(七). 总结
本项目通过现代化的技术栈(Java 17 + Spring Boot 3 + Vue 3)和精巧的业务流程设计,成功构建了一个易于扩展、安全稳定且用户体验优秀的家庭图书管理系统。其对 JPA 性能的打磨和生产环境部署的深度优化,使其具有极高的实战参考价值。
三、第三步:AI帮写部署配置,一键启动
主要方案如下:
家庭图书馆管理系统:本地开发测试与生产环境部署方案总结
本项目采用“本地构建,生产运行”的隔离策略,确保生产环境的轻量化与安全性。以下是详细的部署方案说明。
(一) 本地开发与测试方案
1.1 环境要求
操作系统:macOS / Windows / Linux
开发语言:Java 17 (LTS), Node.js (v16+)
构建工具:Maven 3.8+, npm / vite
数据库:MySQL 8.0 (建议使用 Docker 本地拉取)
1.2 本地运行流程
启动 MySQL,创建数据库 family_library。
配置 backend/src/main/resources/application-dev.yml中的连接信息。
使用 IDE (IntelliJ IDEA) 或命令行执行 mvn spring-boot:run。
进入 vue-migration目录,执行 npm install。
1.3 测试方法
接口测试:使用 Postman 或 curl测试 REST API(如 GET /api/books)。
单元测试:运行 mvn test执行 JUnit 5 测试用例。
联调验证:通过本地浏览器访问 localhost:5173进行全链路功能验证。
(二). 生产环境部署方案 (Ubuntu)
生产环境遵循 Immutable Infrastructure原则,不在服务器上安装构建工具(如 Maven),仅运行预编译的产物。
2.1 部署架构
核心引擎:Docker & Docker Compose
backend-prod: 运行生成的 .jar文件。
frontend-prod: 使用 Nginx 托管构建后的静态资源。
网络协议:强制开启 HTTPS (8443 端口),支持 HTTP (8080/8081) 内部流转。
2.2 核心部署逻辑:跳过构建,直接拷贝
为解决国内服务器拉取 Maven 依赖缓慢及环境一致性问题,采用以下流程:
后端:在本地执行 mvn clean package生成 family-library-management.jar。
前端:执行 npm run build生成 dist/文件夹。
- 将产物拷贝至服务器的
/prod/build/backend/和 /prod/build/frontend/。
- 在生产目录下执行
docker-compose -f docker-compose.prod.yml up -d。
2.3 关键配置优化
安全强化:数据库密码通过环境变量 SPRING_DATASOURCE_PASSWORD注入,而非明文硬编码。
HTTPS 证书管理:部署脚本包含证书转换逻辑(PEM 转 PKCS12),自动配置 Tomcat SSL 证书。
配置正确的 mime.types解决 CSS/JS 无法解析的问题。
数据持久化:使用 Docker Volume (mysql_data) 确保容器重启或更新时数据不丢失。
(三). 运维常用命令手册
3.1 日志查看
后端日志:docker logs -f family-library-backend-prod
前端/网关日志:docker logs -f family-library-frontend-prod
3.2 服务维护
重启所有服务:docker-compose -f docker-compose.prod.yml restart
清理并重新部署:docker-compose -f docker-compose.prod.yml down && docker-compose -f docker-compose.prod.yml up -d
3.3 数据库备份
docker exec family-library-mysql-prod mysqldump -u root -p family_library > backup.sql
(四). 总结
本部署方案通过本地编译+容器化同步的方式,极大降低了生产服务器的运维负担和环境污染风险。配合 HTTPS 和环境变量注入,确保了家庭私有书库的安全性与稳定性。
四、项目代码
git@gitee.com:jiangaifeng/family-library-management.git
git@gitee.com:jiangaifeng/jiangaifeng.com-weixin.git
git@gitee.com:jiangaifeng/book-information-crawler.git
五、最大的感悟:AI不是“替我写代码”,而是“放大我的想法”
AI没有让我变成“甩手掌柜”,而是帮我把“查文档、写重复代码”这些低效工作自动化,让我能把时间花在“更有温度”的地方——比如思考“怎么让扫码更流畅”“怎么让数据可视化更直观”“怎么加个阅读提醒更贴心”。
这个项目,前后花了睡前几个晚上,总成本不到2美元。这种“AI做基础,人做个性化”的模式,才是普通人用技术解决生活问题的核心。
最后想说
技术不再是“专业人士的专利”。只要你有明确的需求——不管是管理家里的绿植、记录宠物的饮食,还是整理藏书——借助AI的力量,都能靠自己的想法,快速做出好用的工具。