当 Page Cache 管理不当,就像给服务器的运行埋下了一颗颗 “定时炸弹”。它不仅会增加系统 I/O 吞吐,让磁盘 I/O 这头 “巨兽” 频繁苏醒,消耗大量资源;还会导致业务性能抖动,使原本流畅的业务流程变得磕磕绊绊,严重影响用户体验。在高并发的业务场景下,比如电商大促、直播高峰时段,Page Cache 的不合理配置可能会让服务器瞬间 “崩溃” 。因此,深入理解和掌握 Page Cache 的原理与管理方法,是每一个 Linux 开发者的必修课。
一、认知底层:什么是 Linux Page Cache?
1.1 定义与核心定位
聊Page Cache之前,先给大家建立一个直观认知:Linux系统中,内存的读写速度是磁盘的上千倍,内核为了填平这层速度鸿沟,特意在内存中开辟了一块“专属缓存区”,这就是Page Cache(页高速缓冲存储器),相当于给磁盘数据建了个“内存中转站”。
从本质上讲,Page Cache是内核专门用于缓存文件数据的内存区域,64位系统默认以8KB为单位(32位系统4KB),和内存页大小保持一致,这样能最大程度减少内存与磁盘的数据交换开销。当用户进程读写文件时,内核会优先查Page Cache,命中就直接从内存拿数据,不用绕远路访问磁盘——这就是“以内存换性能”的核心逻辑。
给大家贴一段简单的实操代码,直观感受缓存命中与未命中的速度差异(bash脚本):
#!/bin/bash# 测试缓存命中与未命中的文件读取速度FILE="/tmp/test_cache.txt"# 生成100MB测试文件dd if=/dev/zero of=$FILE bs=100M count=1 >/dev/null 2>&1echo "第一次读取(未命中缓存):"time cat $FILE >/dev/nullecho "第二次读取(命中缓存):"time cat $FILE >/dev/null# 清理缓存(生产环境慎用)sync && echo 3 > /proc/sys/vm/drop_cachesecho "清理缓存后读取(再次未命中):"time cat $FILE >/dev/null# 清理测试文件rm -f $FILE
执行后能明显看到,第二次读取速度比第一次快几十倍甚至上百倍——这就是Page Cache的威力。比如我们频繁查看Nginx配置文件,第一次读取后文件被存入缓存,后续查看几乎瞬间完成,就是这个道理。
这种机制有效地减少了磁盘 I/O 操作的频率,就像是给磁盘这个 “辛勤的搬运工” 减轻了负担,同时也显著提升了系统的整体性能。Page Cache 的内存空间是独立于 CPU 缓存、磁盘缓存等其他层级的,它与它们协同工作,共同构建了一个高效的数据存储与读取体系,为 Linux 系统的稳定运行提供了坚实保障。
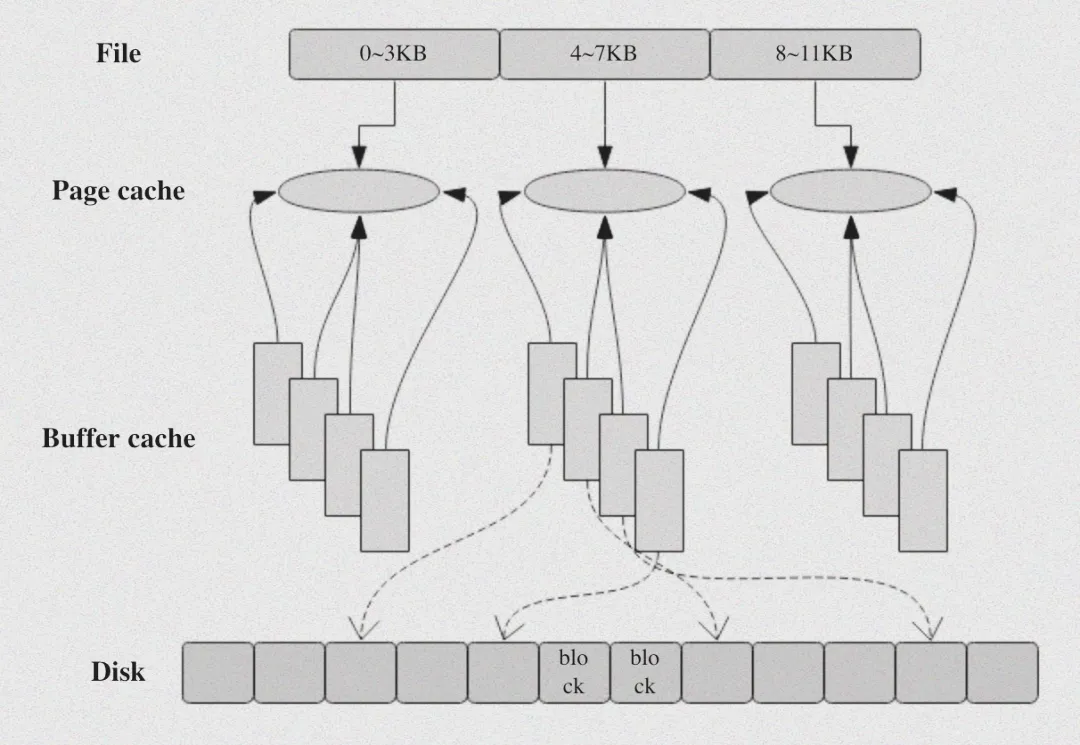
1.2 与 Buffer Cache 的 “前世今生”
很多初学者会把Page Cache和Buffer Cache搞混,其实二者的关系经历过一次“合并革命”。在Linux 2.4版本之前,它们是两个独立的“部门”,分工明确:
但这种分离设计会造成内存浪费,比如读取文件时,数据既要进Page Cache,元数据还要进Buffer Cache。后来内核优化后,Buffer Cache成了Page Cache的“子集”,专门负责块设备的数据缓冲,二者统一管理。我们可以用命令查看这种整合后的状态:
# 查看Buffers和Cached占用,二者合计为Page Cache核心占用cat /proc/meminfo | grep -E "Buffers|Cached"
执行结果中,Buffers就是原Buffer Cache的残留功能,Cached是文件内容缓存,二者共同构成了Page Cache的主要部分——这也是为什么free命令中,buff/cache会把两者合并显示。
随着 Linux 内核的不断发展与优化,现代 Linux 系统对这两者进行了统一。如今,Buffer Cache 已经成为了 Page Cache 的一个子集,它的功能被整合进了 Page Cache 之中。在进行块设备操作时,相关的数据缓冲依然存在,但它们都被纳入了 Page Cache 的管理范畴。这种整合不仅简化了内核的缓存管理机制,还提高了内存的使用效率。我们可以通过 free 等工具查看系统内存使用情况,其中的 buff/cache 项就体现了这种整合,它包含了 Buffers(块设备缓存区)和 Cached(文件缓存)等相关信息,反映了 Page Cache 和 Buffer Cache 合并后的内存使用状态。
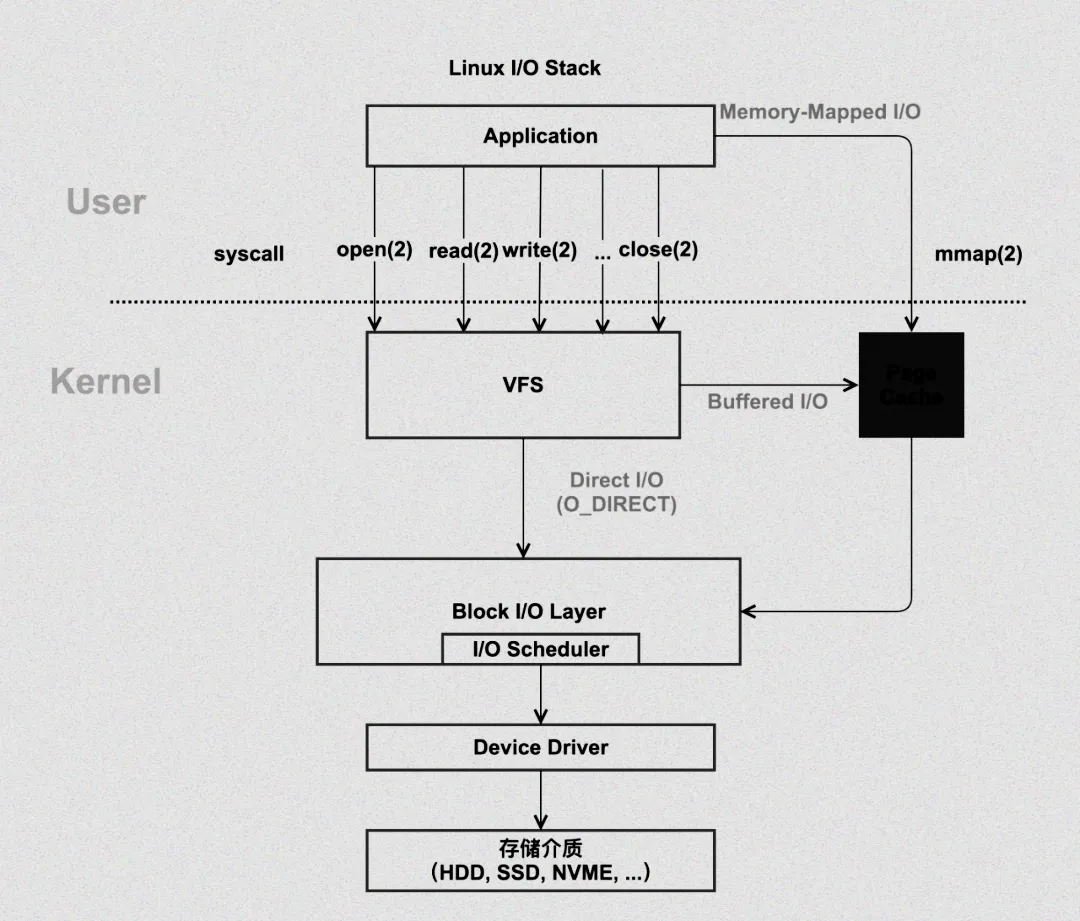
二、深度拆解:Page Cache 的工作逻辑
2.1 读操作:命中即提速,未命中则 “补货”
Page Cache的读操作逻辑很简单,核心就是“先查缓存,再读磁盘”,咱们结合实操拆解更易理解。先上一段C语言代码,模拟文件读操作,看看内核如何调用Page Cache:
#include<stdio.h>#include<stdlib.h>#include<fcntl.h>#include<unistd.h>intmain(){ int fd; char buf[8192]; // 与64位系统Page Cache页大小一致 ssize_t nread; // 打开文件(内核会自动检查Page Cache) fd = open("/tmp/test.txt", O_RDONLY); if (fd == -1) { perror("open failed"); return 1; } // 读取文件(命中缓存则直接从内存取,未命中则触发磁盘读取并缓存) while ((nread = read(fd, buf, sizeof(buf))) > 0) { // 处理读取的数据(此处省略) } close(fd); return 0;}
这段代码中,read()系统调用触发后,内核会先在Page Cache中检索对应的数据页:
然而,当 Page Cache 中没有找到所需数据时,就会触发缓存缺失流程 。这时,内核就像一个忙碌的 “采购员”,需要从磁盘这个 “大仓库” 中获取数据。内核会通过文件系统接口,向磁盘发起读请求,从磁盘中读取相应的数据块。在数据读取完成后,内核会将这些数据写入 Page Cache,就像是把新采购的货物放入仓库,以备后续使用 。
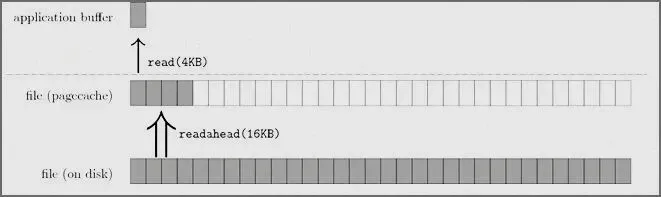
同时,为了进一步提升性能,Linux 内核还采用了预读(readahead)优化策略 。它就像是一个聪明的预测大师,会根据进程的访问模式,预测接下来可能会访问的数据。例如,如果进程连续读取了文件的前几个页面,内核会猜测进程接下来可能还会读取后续的页面,于是一次性从磁盘多读若干页面的数据到 Page Cache 中。这样,当下次进程请求这些数据时,就很有可能直接从 Page Cache 中命中,大大降低了缓存缺失的概率,提升了数据读取的效率。
2.2 写操作:延迟刷盘,高效合并请求
和读操作不同,Page Cache的写操作采用“延迟刷盘”策略——不是写完就立刻同步到磁盘,而是先改缓存、标记脏数据,再由内核异步批量刷盘,这样能最大程度减少磁盘I/O次数。
举个实操例子,用dd命令测试延迟刷盘的效果,再用sync命令强制刷盘:
# 写入100MB数据,观察写速度(默认延迟刷盘)time dd if=/dev/zero of=/tmp/write_test.txt bs=100M count=1 >/dev/null 2>&1# 查看脏数据占用(单位:页,1页=8KB)cat /proc/vmstat | grep dirty# 强制刷盘(同步写,等待所有脏数据写入磁盘)time sync# 再次查看脏数据,会发现数值大幅下降cat /proc/vmstat | grep dirty
可以看到,第一次dd写入速度很快,因为数据只写到了Page Cache;而sync命令会阻塞等待脏数据刷盘,耗时更长——这就是异步写和同步写的核心区别。
值得注意的是,Page Cache 的写操作是以页为单位进行的 。即使应用程序只修改了 1 字节的数据,操作系统也会将整个页标记为脏数据 。这就好比我们在整理书架时,即使只移动了一本书,也会把整层书架都标记为 “需要整理”。虽然这样做看起来有些 “浪费”,但从整体效率和管理便捷性的角度来看,以页为单位进行操作可以减少系统的开销,提高数据处理的效率 。这种机制在高并发的写场景下尤为重要,它能够有效地减少磁盘 I/O 的次数,提升系统的整体性能 。
2.3 缓存同步:两种策略保障数据一致性
延迟刷盘虽能提升性能,但存在数据丢失风险——如果系统突然断电,未刷盘的脏数据会直接丢失。因此Linux提供了同步写和异步写两种策略,适配不同场景的一致性需求。
这里给大家贴一段C语言代码,对比普通写(异步)和fsync(同步)的差异,更直观理解缓存同步机制:
#include<stdio.h>#include<fcntl.h>#include<unistd.h>#include<string.h>intmain(){ int fd; const char *data = "test fsync vs normal write"; fd = open("/tmp/sync_test.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644); if (fd == -1) { perror("open failed"); return 1; } // 普通写(异步,数据先写入Page Cache,标记为脏数据) write(fd, data, strlen(data)); // 同步写(强制将脏数据写入磁盘,确保数据持久化) fsync(fd); // 若只同步文件数据、不同步元数据,可用fdatasync() close(fd); return 0;}
日常场景中,我们保存文档、传输文件用的是异步写,兼顾速度;而数据库、金融交易等核心场景,必须用fsync()强制刷盘,确保数据不丢失——这就是性能与一致性的取舍。
异步写,作为 Linux 系统默认的 “幕后英雄”,默默地在后台发挥着重要作用 。当数据被写入 Page Cache 后,内核会在系统较为空闲的时候,或者通过专门的后台线程,如 pdflush(在较新的内核版本中被其他机制替代,但原理类似),将脏数据批量地写入磁盘 。这种方式极大地提高了写操作的效率,就像我们在整理文件时,先把文件放在临时文件夹,等有时间了再统一整理归档,减少了频繁操作带来的开销 。在日常的文件写入场景中,比如我们保存文档时,数据先被快速写入 Page Cache,内核会在合适的时候将其同步到磁盘,让我们几乎感受不到延迟 。然而,异步写也存在一定的风险,在数据还未被写入磁盘之前,如果系统突然断电或者出现故障,这些未被刷盘的脏数据就有可能丢失 。
而同步写,则是数据一致性的 “坚定守护者”,通过 fsync ()、fdatasync () 等系统调用,为数据的可靠性提供了强有力的保障 。当应用程序调用 fsync () 时,它就像是给内核下达了一道紧急命令,强制内核将指定文件的所有脏数据立即写入磁盘 ,确保数据被安全地存储在磁盘上,才会返回操作结果 。这种方式就像我们在发送重要邮件时,一定要确认邮件已经成功发送到对方服务器才放心,保证了数据的即时持久性 。在数据库等对数据一致性要求极高的场景中,同步写发挥着不可或缺的作用 。比如在银行转账操作中,每一笔交易记录都必须准确无误地写入磁盘,以保证资金的安全和交易的完整性,fsync () 就能确保这一点 。通过这两种缓存同步策略,Linux 系统在性能和数据一致性之间找到了精妙的平衡,满足了不同场景下的需求 。
三、实操指南:如何 “看见” 并操作 Page Cache?
3.1 /proc/meminfo:精准解析缓存构成
想精准掌控Page Cache,第一步得学会“看见”它——/proc/meminfo就是最核心的工具,能帮我们拆解缓存的详细构成,排查内存占用异常。先执行命令查看关键指标:
# 过滤Page Cache相关核心指标cat /proc/meminfo | grep -E "Buffers|Cached|SwapCached|Shmem|Active\(file\)|Inactive\(file\)"
执行后会看到一系列指标,它们的关系的是:Page Cache = Buffers + Cached + SwapCached,每个指标的作用的都要摸清,不然容易踩坑。
从数据构成来看,Page Cache 主要由 Buffers、Cached 和 SwapCached 这几部分组成 。Buffers 主要用于缓存块设备的数据,比如文件系统的元数据、inode 信息等 ,它就像是一个临时的 “数据中转站”,为块设备的读写操作提供了高效的缓冲支持 ;Cached 则专注于缓存文件的实际内容,是我们日常文件读写过程中最常打交道的缓存区域 ,当我们读取一个文件时,文件内容就会被缓存到 Cached 中,方便后续的快速访问 ;SwapCached 则涉及到内存交换空间的缓存,当系统内存不足时,会将一些不常用的内存页交换到磁盘的交换空间中,而 SwapCached 记录的就是这些被交换出去又可能被再次访问的数据在缓存中的状态 。
生产环境中,Active(file)和Inactive(file)是最需要重点关注的两个指标,直接关系到缓存回收和系统性能:
给大家分享一个实操排查脚本,用于监控Page Cache活跃/非活跃占比,及时发现缓存异常:
#!/bin/bash# 监控Page Cache活跃与非活跃占比while true; do ACTIVE=$(grep "Active(file)" /proc/meminfo | awk '{print $2}') INACTIVE=$(grep "Inactive(file)" /proc/meminfo | awk '{print $2}') TOTAL=$((ACTIVE + INACTIVE)) if [ $TOTAL -gt 0 ]; then ACTIVE_RATIO=$(echo "scale=2; $ACTIVE / $TOTAL * 100" | bc) INACTIVE_RATIO=$(echo "scale=2; $INACTIVE / $TOTAL * 100" | bc) echo "当前Page Cache活跃占比:$ACTIVE_RATIO%,非活跃占比:$INACTIVE_RATIO%" fi sleep 5done
如果发现Inactive(file)占比过高且长期不下降,说明大量缓存未被回收,可能导致内存紧张;如果Active(file)占比过高,说明高频访问数据较多,需确保内存充足,避免缓存被频繁回收。
此外,Shmem(共享内存)也是一个不可忽视的指标 。它主要用于进程间的共享内存通信,在一些多进程协作的应用场景中发挥着重要作用 ,比如数据库集群中的数据共享 。当 Shmem 占用过高时,可能会导致系统内存资源紧张,影响其他进程的正常运行 。我们可以通过观察 Shmem 的数值变化,来判断共享内存的使用是否合理 。在一个分布式数据库系统中,由于多个节点之间频繁进行数据同步和共享,Shmem 的占用逐渐升高 。通过监控 /proc/meminfo,我们发现 Shmem 的使用已经接近系统内存的上限,于是及时优化了数据共享策略,减少了不必要的共享内存使用,从而保障了系统的稳定运行 。SwapCached 同样具有重要的参考价值 ,当 SwapCached 的值持续上升时,说明系统正在频繁地进行内存与交换空间的数据交换,这往往意味着系统内存不足,需要及时进行调整 ,比如增加物理内存或者优化内存使用策略 。
3.2 free 命令:读懂 buff/cache 的真正含义
free命令是大家最常用的内存查看工具,但很多人只看free值,却看不懂buff/cache的真正含义——其实它藏着Page Cache的关键信息,先执行命令看直观输出:
# 以人类可读格式查看内存,重点关注buff/cache和availablefree -h
输出中,buff/cache = Buffers + Cached + SReclaimable,其中SReclaimable是可回收的内核内存(包含dentry目录缓存、inode元数据缓存),这部分内存是“弹性的”——应用需要时,内核会自动回收。
从内存管理的角度来看,buff/cache 重点强调的是内存的可回收性 。Linux 系统的内存管理机制非常智能,它会尽可能地利用空闲内存来缓存数据,以提高系统的性能 。当应用程序需要更多内存时,系统会自动从 buff/cache 中回收这些可回收的内存,为应用程序提供支持 。这就好比我们的房间,平时会把一些暂时不用的物品放在角落(缓存内存),当需要更多空间时,就可以把这些物品清理掉(回收内存) 。在一个运行着多个服务的服务器上,我们可以通过 free 命令观察到,随着服务的启动和运行,buff/cache 的占用逐渐增加 。当某个服务需要更多内存时,系统会自动从 buff/cache 中回收部分内存,以满足服务的需求 ,而不会对服务的正常运行产生明显影响 。
在实际应用中,我们可以通过对比 used、free 与 available 的值,来快速判断系统缓存的占用情况以及实际可用内存的大小 。used 表示已经被使用的内存,它包含了应用程序实际占用的内存以及缓存所占用的内存 ;free 则表示当前系统中真正空闲的内存 ;available 则是一个更为关键的指标,它表示系统中实际可用于分配给应用程序的内存大小 ,这个数值是综合考虑了缓存的可回收性以及系统的内存分配策略后得出的 。当我们发现 available 的值较低时,就需要警惕系统内存不足的问题,及时采取措施进行优化 ,比如清理不必要的缓存、调整应用程序的内存使用策略等 。在一次服务器性能优化中,我们发现系统的 used 内存占用较高,而 available 内存较低 。通过进一步分析 free 命令的输出,发现 buff/cache 占用了大量内存 。经过排查,发现是一些长时间运行的服务产生了大量的缓存数据 。我们通过优化服务的缓存策略,清理了部分不必要的缓存,使得 available 内存得到了显著提升,系统性能也得到了明显改善 。
3.3 实操小技巧:清空缓存的正确姿势
清空Page Cache是常用的实操操作,比如测试磁盘真实读写性能、临时释放内存,但生产环境必须谨慎——清空后所有读写都会直接命中磁盘,可能导致I/O压力骤增。
# 1. 仅清空Page Cache(推荐,不影响dentry和inode缓存)sync && echo 1 > /proc/sys/vm/drop_caches# 2. 清空Page Cache + dentry + inode缓存(彻底清理,慎用)sync && echo 3 > /proc/sys/vm/drop_caches# 3. 清空Swap缓存(需配合关闭Swap,生产环境谨慎)swapoff -a && swapon -a
关键注意点:
sync命令必须加:强制将脏数据刷盘,避免清空缓存时丢失数据;
避开业务高峰:清空后短时间内I/O会飙升,可能导致业务延迟;
不依赖清空缓存:频繁清空说明缓存策略有问题,需优化而非治标不治本。
在生产环境中,执行清空缓存的操作需要格外谨慎 。因为一旦清空缓存,系统在短时间内会失去缓存的加速作用,所有的文件读写请求都将直接落到磁盘上,这可能会导致磁盘 I/O 压力瞬间陡增 ,就像突然给磁盘这个 “搬运工” 增加了大量的货物,使其不堪重负 。在一个电商平台的服务器上,由于运维人员误操作,在业务高峰期执行了清空缓存的命令,导致服务器的 I/O 使用率瞬间飙升至 100%,业务响应时间从原本的几十毫秒延长到了数秒,大量用户的请求超时,给业务带来了巨大的损失 。因此,在生产环境中,我们必须充分评估清空缓存的必要性和可能带来的风险,确保操作的安全性 。如果确实需要进行缓存清理,建议选择在业务低谷期进行,并密切监控系统的性能指标 ,一旦出现异常,及时采取措施进行恢复 。
四、关键场景:缓存未命中的 “应急补货” 全流程
4.1 第一步:触发缺页异常(Page Fault)
缓存未命中就像“仓库没货了”,此时内核会启动“应急补货”流程,而整个流程的起点,就是“读缺页异常”(Page Fault)。咱们先通过一个简单的命令,模拟缺页异常的触发:
# 1. 清空缓存,确保无数据残留sync && echo 3 > /proc/sys/vm/drop_caches# 2. 读取一个未被缓存的大文件,同时监控缺页异常次数cat /var/log/messages &grep "Page Fault" /var/log/kern.log
执行后会发现,kern.log中会出现大量缺页异常记录——这就是内核在告诉我们:“需要的数据不在缓存里,得去磁盘拿了”。这里要注意,读缺页异常和内存不足的缺页异常完全不同:
需要注意的是,这里的读缺页异常与内存不足导致的缺页异常有着本质的区别 。内存不足导致的缺页异常,就像是仓库里的货物已经被搬空了,没有足够的库存来满足需求;而读缺页异常,是因为所需的货物原本就没有被存放在仓库中,需要从其他地方调货 。在一个文件处理程序中,当程序试图读取一个大文件的某一页数据时,如果这一页数据没有被缓存到 Page Cache 中,就会触发读缺页异常 ,内核会立即启动后续的处理流程,以满足程序对数据的需求 。
4.2 第二步:文件系统与块设备的层级协作
缺页异常触发后,内核不会直接去读磁盘,而是通过“层级协作”把请求拆解,确保数据能精准读取——这个过程就像“快递分拣”,从总仓到分仓再到配送,每一步都有明确分工。
我们可以通过查看进程的I/O调用链,直观看到文件系统与块设备的协作过程,用strace命令实操:
# 跟踪cat命令的系统调用,查看I/O协作流程strace -e trace=open,read,write,close cat /tmp/test.txt
输出中会看到,cat命令先调用open()打开文件(VFS层面),再调用read()读取数据(文件系统层面,如ext4),最后由块层将请求转换为磁盘操作——整个流程层层拆解,最终完成数据读取。
在这个过程中,块层会将逻辑块地址(LBA)精确地映射到物理磁盘位置 。这就像是在地图上找到目标地点的具体坐标,确保数据能够准确无误地被读取 。而 IO 调度器(如 CFQ、deadline)则像是一位高效的调度员,会对请求队列进行精心优化 ,避免磁盘寻道性能损耗 。它会根据不同的调度算法,合理安排请求的顺序,就像是安排快递员的送货路线,提高了磁盘 I/O 的整体效率 。在一个多进程并发的系统中,多个进程可能同时发出文件读取请求,IO 调度器会根据每个请求的优先级、数据的物理位置等因素,对这些请求进行排序和调度 ,使得磁盘能够以最高效的方式处理这些请求 ,减少了磁盘的寻道时间和旋转延迟 ,提高了系统的整体性能 。
4.3 第三步:DMA 传输与缓存页面更新
数据读取的最后一步,是把磁盘数据传输到内存缓存,而DMA(直接内存访问)技术是这里的“效率担当”——它能绕开CPU,直接让磁盘控制器和内存通信,大大减轻CPU负担。
我们可以通过lspci命令查看系统的DMA控制器,再用iostat查看DMA传输的负载:
# 查看DMA控制器信息lspci | grep -i dma# 查看磁盘I/O及DMA相关负载(%util接近100%说明DMA忙碌)iostat -x 1
当DMA完成数据传输后,会向CPU发送中断信号,CPU再触发内核处理:将数据填充到struct page结构体(缓存页容器),更新radix树(缓存索引,方便后续快速查找)——至此,“应急补货”完成,后续访问就能命中缓存了。
内核在收到中断信号后,会迅速将数据填充至新分配的 struct page 结构体中 ,就像是将新到的货物整齐地摆放在仓库的货架上 。同时,内核还会更新 address_space 的基数树(radix tree) ,这个基数树就像是仓库的库存管理系统,记录着每个货物(数据页)的存放位置和相关信息 。通过更新基数树,内核完成了缓存页面的添加与映射 ,使得后续对这些数据的访问能够快速、准确地进行 。在一个数据库系统中,当需要读取大量的数据页时,DMA 技术能够快速地将数据从磁盘传输到内存,内核将这些数据填充到 struct page 结构体中,并更新基数树 ,为后续的数据库查询和处理提供了高效的数据支持 ,大大提升了数据库系统的性能 。
五、内存紧张时,Page Cache 如何 “自处”?
5.1 LRU 算法:缓存回收的核心逻辑
系统内存就像“共享仓库”,应用程序和Page Cache都要抢着用——当内存紧张时,Page Cache不能“占着茅坑不拉屎”,必须通过回收策略释放内存,而LRU(最近最少使用)算法就是最核心的回收规则。
LRU的逻辑很简单:“最近没被用的,未来也大概率用不上”,所以优先回收最久未访问的缓存页。我们可以通过内核参数调整LRU的回收策略,实操命令如下:
# 查看当前LRU回收相关参数(控制活跃/非活跃缓存的比例)cat /proc/sys/vm/vfs_cache_pressure# 调整参数:值越大,越优先回收缓存(默认100,推荐生产环境设50-80)echo 60 > /proc/sys/vm/vfs_cache_pressure# 永久生效(需重启系统或执行sysctl -p)echo "vm.vfs_cache_pressure = 60" >> /etc/sysctl.conf
举个例子:如果vfs_cache_pressure设为100,内核会平等对待应用内存和缓存内存;设为60,内核会更倾向于保留缓存,减少频繁回收带来的性能损耗——这个参数需要根据业务场景微调。
LRU 算法的核心思想基于一个简单而直观的假设:如果一个数据在最近一段时间内没有被访问过,那么在未来它被访问的可能性也相对较低 。因此,当需要回收内存页面时,LRU 算法会优先选择那些最久未被访问的页面 。在 Page Cache 中,系统会为每个缓存页面维护一个访问时间戳,就像是给每个物品都贴上了一个记录最后使用时间的标签 。当一个页面被访问时,其访问时间戳会被更新,标记为最新被访问 。而当内存不足需要回收页面时,系统会扫描 Page Cache,找到访问时间戳最早的页面,也就是最久未被访问的页面,将其从缓存中移除 ,释放出内存空间供其他数据使用 。
这种基于 LRU 算法的缓存回收机制,能够动态地平衡 Page Cache 的大小与应用程序的可用内存 。在一个同时运行着多个服务的服务器上,可能会有各种不同类型的文件被频繁访问,如 Web 服务的静态页面文件、数据库的索引文件等 。随着时间的推移,Page Cache 会逐渐被这些文件的缓存页面填满 。当系统内存紧张时,LRU 算法会根据各个页面的访问时间戳,将那些长时间未被访问的文件缓存页面回收 ,比如一些不常用的日志文件的缓存页面 ,从而确保 Page Cache 中始终保留着最有可能被再次访问的数据 ,为系统的稳定运行提供了有力保障 。通过这种方式,LRU 算法有效地提高了内存的使用效率,使得系统能够在有限的内存资源下,高效地运行各种应用程序 。
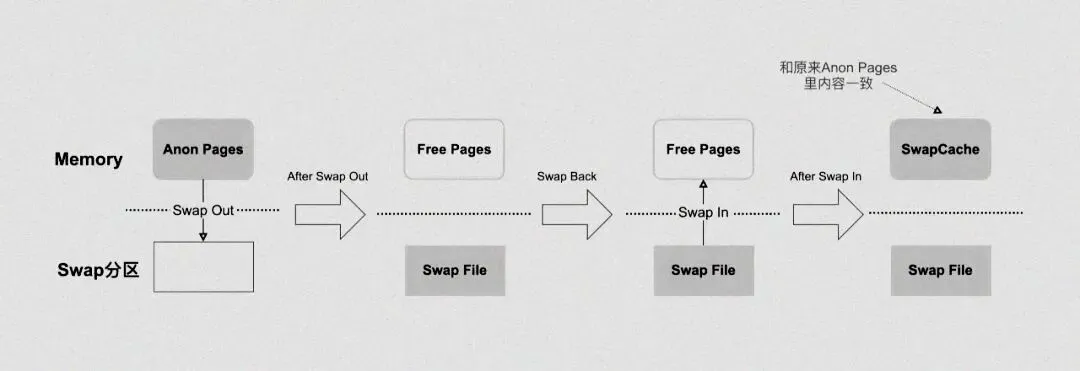
5.2 Swap 分区的 “坑”:生产环境建议关闭
Swap分区是Linux的“内存备胎”——当物理内存不足时,内核会把不常用的内存页(包括部分Page Cache)换到磁盘上,腾出物理内存。但这个“备胎”很容易帮倒忙,尤其是生产环境。
先给大家实操查看Swap的使用情况,以及SwapCached的占用:
# 查看Swap整体使用情况free -h | grep Swap# 查看SwapCached占用(单位:KB)cat /proc/meminfo | grep SwapCached# 查看哪些进程在使用Swap(定位Swap占用过高的进程)for i in $(cd /proc; ls -d [0-9]*); do echo -n "$i "; grep VmSwap /proc/$i/status 2>/dev/null; done | sort -k 3 -n -r | head -10
当SwapCached持续上升,说明系统在频繁做“内存-Swap”交换——这个过程涉及大量磁盘I/O,速度极慢,会直接导致业务延迟飙升。
然而,在生产环境中,Swap 分区的使用往往会带来一些性能问题 。Swap 过程涉及到磁盘 I/O 操作,而磁盘的读写速度远远低于内存 。当系统频繁地进行内存与 Swap 分区的数据交换时,会导致 I/O 性能急剧下降,就像在一条原本畅通的道路上设置了许多减速带,使得数据的传输变得缓慢而卡顿 。在一个对实时性要求极高的在线交易系统中,如果由于内存不足而频繁触发 Swap 操作,可能会导致交易响应时间大幅延长,甚至出现交易超时的情况 ,给用户带来极差的体验,同时也可能给企业带来巨大的经济损失 。
为了避免这些问题,在生产环境中,通常建议关闭 Swap 分区 。关闭 Swap 分区后,系统将不再依赖于这个 “备用仓库”,而是更加严格地管理物理内存的使用 。这样可以避免因 Swap 操作而导致的性能抖动,提高系统的稳定性和响应速度 。在一些对性能要求极高的服务器上,如大型数据库服务器、高并发的 Web 应用服务器等,关闭 Swap 分区已经成为一种常见的优化策略 。通过合理地配置内存资源,优化应用程序的内存使用,这些服务器能够在不依赖 Swap 分区的情况下,稳定高效地运行 。
5.3 内核缓存 vs 应用层缓存
做开发或运维时,常会纠结:到底用内核Page Cache,还是自己做应用层缓存(比如MySQL的InnoDB Buffer Pool、Redis缓存)?其实没有绝对的好坏,只有适配与否,咱们结合实操场景对比更清晰。
先看应用层缓存的例子(以Redis缓存文件内容为例):
# 1. 读取文件内容,存入Redis(应用层缓存)cat /tmp/data.txt | redis-cli -x set data_key# 2. 后续访问直接从Redis获取,绕过Page Cacheredis-cli get data_key
| 对比维度 | 内核Page Cache | 应用层缓存 |
|---|
| 开发成本 | 零成本,内核自动管理 | 高成本,需开发缓存逻辑、处理一致性 |
| 控制粒度 | 粗粒度(按页管理) | 细粒度(可按需缓存指定数据) |
| 适用场景 | 普通文件读写、静态资源(Nginx静态页) | 高频访问、复杂查询(数据库、接口结果) |
结论:多数场景下,优先用内核Page Cache(低成本、高性价比);只有需要细粒度控制、高频访问特定数据时,再做应用层缓存——比如静态页面用Page Cache,数据库查询结果用Redis缓存,二者结合效率最高。
相比之下,内核 Page Cache 就像是一个 “免费的午餐”,它无需应用程序进行额外的开发和维护 。内核会自动根据系统的整体运行情况,智能地管理 Page Cache 。当应用程序进行文件读写操作时,内核会自动将相关数据缓存到 Page Cache 中,并且会根据 LRU 算法等策略,动态地调整缓存的内容 。在大多数场景下,依赖内核 Page Cache 能够以更低的成本提升系统性能 。在一个简单的 Web 应用中,大量的静态文件,如 HTML、CSS、JavaScript 文件等,通过内核 Page Cache 进行缓存,就能够显著提高文件的读取速度,减少磁盘 I/O 操作,而应用程序无需进行任何额外的缓存配置 。因此,在一般情况下,优先依赖内核 Page Cache 是一种更为明智和经济的选择 ,它能够在保证系统性能的同时,降低开发和维护的复杂度 。
六、Page Cache 引发的性能问题排查
6.1 场景 1:应用 RSS 不高,系统内存使用率却爆表
这是生产环境中最常见的“迷惑性”问题:top命令看单个应用的RSS(常驻内存)不大,但free命令显示内存使用率快满了——大概率是Shmem(匿名共享映射内存)在“偷内存”,它属于Page Cache的一部分,却容易被忽略。
给大家贴一段排查脚本,快速定位Shmem占用过高的原因:
# 1. 查看Shmem总占用cat /proc/meminfo | grep Shmem# 2. 查看tmpfs占用(tmpfs基于Shmem,临时文件会占用大量内存)df -h | grep tmpfs# 3. 定位占用Shmem的进程(查找匿名共享内存段)for pid in $(ps aux | awk '{print $2}'); do grep -q "Shmem" /proc/$pid/smaps 2>/dev/null && echo "PID: $pid 占用Shmem"done | head -10
比如在微服务架构中,多个服务通过共享内存通信,若未及时释放,Shmem会持续飙升;又比如tmpfs挂载的/tmp目录,存放大量临时文件,也会占用Shmem——找到原因后,清理临时文件或优化共享内存配置即可解决。
我们可以通过查看 /proc/meminfo 中的 Shmem 指标,来直观地了解其占用情况 。如果 Shmem 的值持续攀升,接近甚至超过系统内存的可用阈值,就需要警惕了 。这可能意味着系统中存在一些不合理的共享内存使用方式,或者某些进程在使用完共享内存后没有及时释放资源 。tmpfs 等临时文件系统也会大量占用内存,它们基于内存进行文件存储,其数据实际上也存储在 Shmem 中 。在一个基于微服务架构的电商平台中,各个微服务之间通过共享内存进行数据交互 。由于部分微服务的设计缺陷,在高并发场景下,频繁地创建和使用共享内存,导致 Shmem 占用急剧上升 。尽管单个微服务的 RSS 看似正常,但系统内存使用率却不断攀升,最终引发了系统性能的急剧下降,页面加载缓慢,用户投诉不断 。通过深入分析 /proc/meminfo,定位到了问题所在,优化了共享内存的使用方式,及时释放了不再使用的共享内存资源,系统性能才得以恢复正常 。
6.2 场景 2:I/O 吞吐飙高,业务响应延迟飙升
I/O吞吐飙高、业务延迟飙升,本质是“磁盘I/O扛不住了”,而核心原因往往和Page Cache的缓存命中率相关。咱们用vmstat和pidstat两个命令,快速排查问题根源:
# 1. 监控I/O状态,重点看bi(读磁盘)、bo(写磁盘)vmstat 1# 2. 监控进程I/O,定位哪个进程导致I/O飙升pidstat -d 1# 3. 计算Page Cache命中率(核心指标,命中率低于90%需优化)# 公式:命中率 = (总读请求 - 磁盘读请求) / 总读请求 * 100%# 用iostat获取相关数据,简化脚本如下:iostat -x 1 5 > io.logREAD_TOTAL=$(awk '/^vda/ {sum += $4} END {print sum}' io.log)DISK_READ=$(awk '/^vda/ {sum += $5} END {print sum}' io.log)HIT_RATE=$(echo "scale=2; ($READ_TOTAL - $DISK_READ)/$READ_TOTAL * 100" | bc)echo "Page Cache命中率:$HIT_RATE%"
如果bi值持续偏高、命中率低于90%,说明缓存未命中频繁,需优化缓存策略(比如增大预读、调整LRU参数);如果bo值异常,就是脏数据批量刷盘,需调整内核刷盘参数。
而当 bo(块设备写)的数值异常时,则需要警惕脏数据批量刷盘的情况 。当系统中的脏数据积累到一定程度时,内核会触发刷盘操作,将这些脏数据一次性写入磁盘 。这可能会导致磁盘 I/O 压力瞬间增大,影响业务的正常响应 。在一个实时数据写入的场景中,大量的数据被不断写入系统,脏数据迅速积累 。当达到内核的刷盘阈值时,脏数据被批量刷盘,bo 值急剧上升,业务响应延迟也随之飙升 。为了缓解这种压力,我们可以适当调整内核的刷盘参数,如调整 dirty_ratio(脏数据占内存的比例阈值)和 dirty_background_ratio(触发后台刷盘的脏数据占内存的比例阈值)等参数 ,使得脏数据能够更及时、更分散地被刷盘,避免出现集中刷盘导致的 I/O 压力过大的问题 。
6.3 生产环境优化建议
结合前面的实操和问题排查,给大家整理一套生产环境可直接落地的优化方案,每个优化点都配实操命令,方便直接套用。
优化点1:关闭Swap分区(优先操作)
# 临时关闭Swapswapoff -a# 永久关闭Swap(注释/etc/fstab中的Swap配置)sed -i '/swap/s/^/#/' /etc/fstab# 验证是否关闭成功free -h | grep Swap
优化点2:调整文件预读大小(适配访问模式)
# 查看当前预读大小(单位:512字节扇区,默认256=128KB)blockdev --getra /dev/vda# 调整预读大小(顺序访问场景,设为1024=512KB)blockdev --setra 1024 /dev/vda# 永久生效(添加到/etc/rc.local)echo "blockdev --setra 1024 /dev/vda" >> /etc/rc.localchmod +x /etc/rc.local
优化点3:调整脏数据刷盘参数(避免批量刷盘)
# 查看当前参数(单位:百分比/KB)sysctl -a | grep dirty# 临时调整参数sysctl -w vm.dirty_ratio=20 # 脏数据占内存20%时,强制刷盘sysctl -w vm.dirty_background_ratio=10 # 脏数据占10%时,后台异步刷盘sysctl -w vm.dirty_expire_centisecs=3000 # 脏数据30秒后强制刷盘# 永久生效echo -e "vm.dirty_ratio=20\nvm.dirty_background_ratio=10\nvm.dirty_expire_centisecs=3000" >> /etc/sysctl.confsysctl -p
合理设置文件预读参数也是关键 。通过调整内核参数,如 read_ahead_kb(文件预读大小)等,可以根据业务的数据访问模式,更精准地控制文件预读的量 。对于顺序访问为主的业务,适当增大预读大小,可以提前将更多的数据加载到 Page Cache 中,提高缓存命中率;而对于随机访问较多的业务,则需要适当减小预读大小,避免不必要的磁盘 I/O 。在一个视频流媒体服务中,由于视频文件的访问大多是顺序读取,通过增大 read_ahead_kb 参数,将预读大小调整为合适的值,使得视频播放更加流畅,缓冲时间明显减少 。
我们还应避免滥用 Direct I/O 绕过 Page Cache 。虽然 Direct I/O 在某些特定场景下,如数据库的裸设备访问等,有其独特的优势,但在大多数情况下,绕过 Page Cache 会失去缓存带来的性能提升 。因此,在选择使用 Direct I/O 时,需要谨慎评估业务需求,确保其必要性 。定期监控 buff/cache 的变化也是必不可少的 。通过观察 buff/cache 的大小变化、缓存命中率等指标,结合业务的访问模式,及时调整缓存策略 。在业务访问高峰期,可以适当增加缓存容量,以应对大量的读写请求;而在业务低谷期,则可以回收部分缓存,释放内存资源,供其他进程使用 。通过这些优化措施的综合应用,我们能够更好地管理 Page Cache,平衡系统性能与内存资源的使用,确保生产环境的稳定、高效运行 。