大家好,我是小寒
今天给大家分享机器学习中的一个关键概念,SHAP
SHAP(Shapley Additive Explanations)是一种模型解释方法,它基于博弈论中的 Shapley值(Shapley Value)来计算每个特征对模型预测的贡献。
在机器学习中,尤其是深度学习和集成学习(如随机森林、梯度提升树等)模型中,我们通常面临模型的“黑箱”问题,即模型的决策过程难以解释。SHAP 通过提供每个特征对最终预测结果的贡献来帮助我们理解模型的决策过程。
Shapley 值概述
Shapley 值源于博弈论,由 Lloyd Shapley 在 1953 年提出,最初用于解决合作博弈中的资源分配问题。Shapley 值提供了一种公平的方式来分配合作博弈中每个参与者的贡献。
想象一个场景:三个人合作完成了一项任务,最终获得了 100 分的奖励。由于每个人贡献不同,我们该如何公平地分配这 100 分?
Shapley 值的做法是:对于每个玩家,考虑其在不同合作情况下(即不同的玩家组合中)的边际贡献,然后对所有可能的组合取平均。
在机器学习中,我们可以把每个特征看作一个“参与者”,而模型的预测则是 “收益”。
Shapley 值通过考虑每个特征在所有可能的特征排列下对模型预测的贡献,来为每个特征分配一个重要性分数。
Shapley 值的数学定义
1.加性解释模型
对于一个特定的样本 ,SHAP 将预测结果 表示为
其中
- 是第 个特征的 SHAP Value,它代表了该特征对预测结果的贡献。
SHAP 将原始复杂模型 的预测结果,用一个更简单、可解释的线性模型 来近似解释。
Shapley Value 的计算公式
特征 的贡献值 计算公式如下
其中
- :边际贡献。即加入特征 后,预测值发生了多少变化。
- :这是权重系数,代表了在所有可能的排列组合中,该特定子集出现的概率。
SHAP 的性质
SHAP 值具有以下几个重要性质
局部准确性
所有特征的 SHAP 值之和等于模型的预测值与基准值(均值)之差。
其中 是模型在所有训练集上的平均预测输出。
缺失性
如果一个特征在模型中不存在(或者取值为空),那么它的 SHAP 值应为 0。
一致性
如果一个模型改变后,某个特征的边际贡献增加了,那么其 SHAP 值不应该减少。
常用的近似算法
直接按照上面的公式计算是指数级的复杂度()。在工程实践中,我们通常使用以下几种近似算法。
- KernelSHAP:使用加权线性回归来估计 SHAP 值,适用于任何黑盒模型。
- TreeSHAP:专门为树模型(XGBoost, LightGBM, CatBoost)设计的算法。它利用树的结构,将计算复杂度从指数级降低到了多项式级,非常高效。
- DeepSHAP:专为神经网络设计,通过反向传播来分配贡献。
实际应用
SHAP 值在实际应用中具有非常广泛的用途。
- 模型解释:帮助理解和解释复杂模型(如深度学习或集成模型)的预测结果。
- 特征选择:通过评估每个特征的 SHAP 值,可以识别出最重要的特征,辅助特征选择过程。
- 公平性分析:SHAP 值可以用于分析模型是否对不同群体存在偏见,检查模型在各个群体上的预测是否公平。
- 模型调优:通过分析 SHAP 值,可以发现哪些特征影响模型表现,进而进行模型的调优。
SHAP 的可视化
常见的可视化方式包括
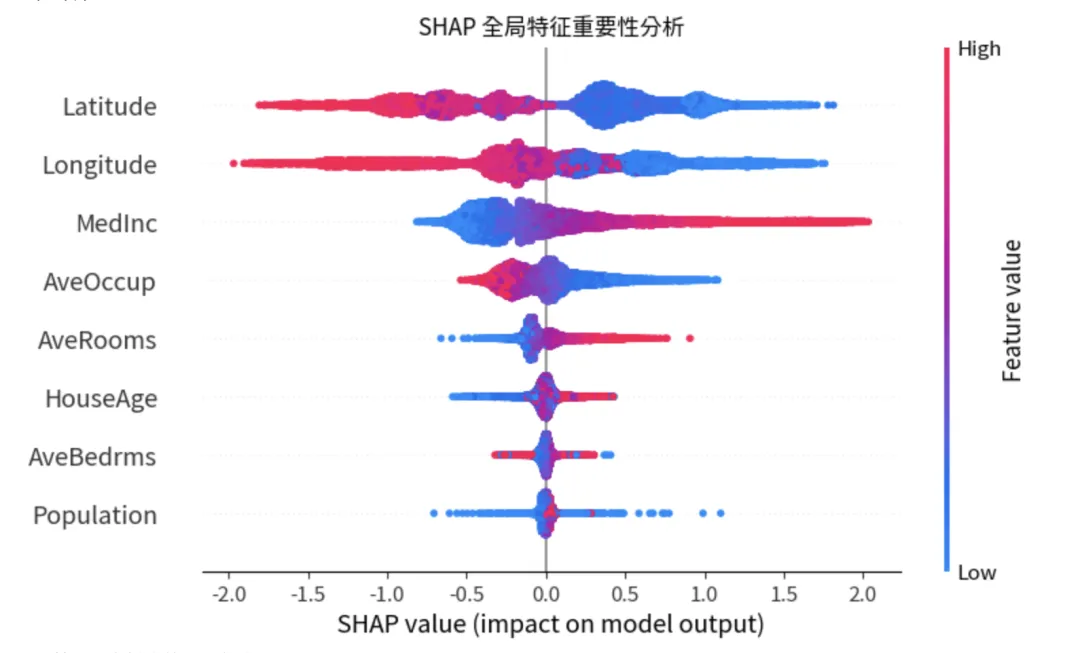
- Summary Plot:展示特征对模型输出的整体影响。它不仅显示哪些特征重要,还显示特征取值的高低如何影响预测结果
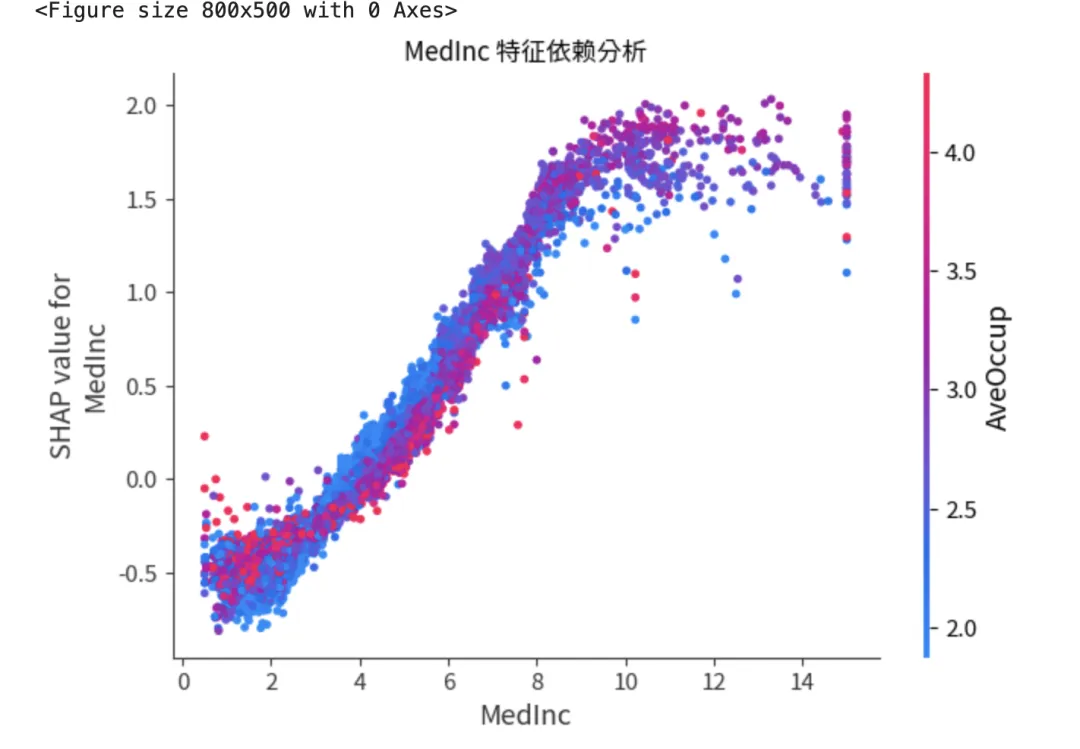
- Dependence Plot:展示单个特征与预测结果之间的非线性关系,以及特征间的交互作用。
- Force Plot:解释单个样本。红色箭头代表将预测值推高的特征,蓝色代表推低的特征。
案例分享
下面是一个使用 CatBoost 和 SHAP 进行回归预测的具体示例代码。
该代码包括以下几个步骤:
- 数据加载和预处理:加载一个回归任务数据集(例如:fetch_california_housing 数据集),对数据进行适当处理。
- 使用 K折交叉验证进行参数优化:使用 GridSearchCV 对 CatBoost 回归模型进行超参数优化。
- 训练 CatBoost 模型:根据优化后的超参数训练 CatBoost 模型。
- SHAP 可解释性分析:使用 SHAP 来解释训练好的模型,分析特征对预测结果的贡献。
import pandas as pdimport numpy as npimport shapimport matplotlib.pyplot as pltfrom catboost import CatBoostRegressorfrom sklearn.model_selection import KFold, GridSearchCVfrom sklearn.datasets import fetch_california_housingfrom sklearn.metrics import mean_squared_error, r2_score# 1. 加载数据集 (以加州房价回归问题为例)data = fetch_california_housing()X = pd.DataFrame(data.data, columns=data.feature_names)y = data.targetprint(f"数据集大小: {X.shape}")# 2. 定义 K折交叉验证与参数优化# 我们使用 GridSearchCV 配合 K-Fold 来寻找最佳超参数kf = KFold(n_splits=5, shuffle=True, random_state=42)# 定义待优化的参数网格param_grid = {'iterations': [500],'learning_rate': [0.05, 0.1],'depth': [4, 6],'l2_leaf_reg': [1, 3],'loss_function': ['RMSE'],'verbose': [False]}# 初始化 CatBoost 回归模型cb_model = CatBoostRegressor(allow_writing_files=False)# 3. 执行参数优化print("正在进行 K折交叉验证参数优化...")grid_search = GridSearchCV(estimator=cb_model, param_grid=param_grid, cv=kf, scoring='neg_mean_squared_error', n_jobs=-1)grid_search.fit(X, y)# 输出最佳参数best_model = grid_search.best_estimator_print(f"最佳参数: {grid_search.best_params_}")# 4. 模型评估y_pred = best_model.predict(X)print(f"全量数据 R2 Score: {r2_score(y, y_pred):.4f}")print(f"全量数据 RMSE: {np.sqrt(mean_squared_error(y, y_pred)):.4f}")# 5. SHAP 可解释性分析print("正在计算 SHAP values...")# TreeExplainer 是专门针对树模型优化的解释器,速度极快explainer = shap.TreeExplainer(best_model)shap_values = explainer.shap_values(X)# --- 可视化部分 ---# A. 全局解释:Summary Plot (蜂群图)# 展示哪些特征最重要,以及特征值高低如何影响预测结果plt.figure(figsize=(10, 6))shap.summary_plot(shap_values, X, show=False)plt.title("SHAP 全局特征重要性分析")plt.show()
# B. 局部解释:Force Plot (力导向图)# 解释单个样本(例如第 0 个样本)的预测过程# 注意:在 Jupyter 中使用需要执行 shap.initjs()print("展示第 1 个样本的预测解释:")shap.plots.force(explainer.expected_value, shap_values[0, :], X.iloc[0, :], matplotlib=True)

# C. 特征依赖图:Dependence Plot# 观察单个特征(如 'MedInc' 收入中位数)与预测值之间的非线性关系plt.figure(figsize=(8, 5))shap.dependence_plot("MedInc", shap_values, X, show=False)plt.title("MedInc 特征依赖分析")plt.show()