1. 创始时间与作者
2. 官方资源
Python 官方文档:https://docs.python.org/3/library/multiprocessing.html
源码地址:https://github.com/python/cpython/tree/main/Lib/multiprocessing
PEP 371:https://www.python.org/dev/peps/pep-0371/
教程指南:https://docs.python.org/3/library/multiprocessing.html
3. 核心功能
4. 应用场景
1. 基础多进程编程
import multiprocessingimport osimport timedef worker_process(process_id, duration):"""工作进程函数"""print(f"进程 {process_id} (PID: {os.getpid()}) 开始执行")start_time = time.time()# 模拟 CPU 密集型工作result = 0for i in range(10**7):result += i*iend_time = time.time()print(f"进程 {process_id} 完成,耗时: {end_time - start_time:.2f}秒")return resultdef basic_multiprocessing_demo():"""基础多进程演示"""processes = []# 创建并启动多个进程for i in range(4):process = multiprocessing.Process(target=worker_process, args=(i, 2) )processes.append(process)process.start()print(f"启动进程 {i}")# 等待所有进程完成for i, process in enumerate(processes):process.join()print(f"进程 {i} 已加入")print("所有进程执行完毕")if __name__ == '__main__':basic_multiprocessing_demo()2. 进程池与并行计算
import multiprocessingimport timeimport mathdef cpu_intensive_task(n):"""CPU 密集型任务:计算素数"""print(f"开始计算 {n} 以内的素数")def is_prime(num):if num<2:return Falsefor i in range(2, int(math.sqrt(num)) +1):if num%i == 0:return Falsereturn Trueprimes = [i for i in range(2, n+1) if is_prime(i)]return len(primes)def pool_demo():"""进程池演示"""print(f"可用的 CPU 核心数: {multiprocessing.cpu_count()}")# 创建进程池,使用所有可用的 CPU 核心with multiprocessing.Pool() as pool:# 准备任务tasks = [100000, 200000, 300000, 400000, 500000]# 方法1: map - 阻塞式执行print("=== map 方法 ===")start_time = time.time()results_map = pool.map(cpu_intensive_task, tasks)map_time = time.time() -start_time# 方法2: map_async - 异步执行print("=== map_async 方法 ===")start_time = time.time()async_result = pool.map_async(cpu_intensive_task, tasks)results_async = async_result.get()async_time = time.time() -start_time# 方法3: apply_async - 逐个提交任务print("=== apply_async 方法 ===")start_time = time.time()async_results = []for task in tasks:result = pool.apply_async(cpu_intensive_task, (task,))async_results.append(result)results_apply = [r.get() for r in async_results]apply_time = time.time() -start_time# 输出结果for i, (task, result) in enumerate(zip(tasks, results_map)):print(f"任务 {i}: {task} 以内的素数个数 = {result}")print(f"\n性能比较:")print(f"map 耗时: {map_time:.2f}秒")print(f"map_async 耗时: {async_time:.2f}秒")print(f"apply_async 耗时: {apply_time:.2f}秒")if __name__ == '__main__':pool_demo()3. 进程间通信与数据共享
import multiprocessingimport timeimport randomdef producer(queue, producer_id, num_items):"""生产者进程"""for i in range(num_items):item = f"产品-{producer_id}-{i}"# 模拟生产时间time.sleep(random.uniform(0.1, 0.3))queue.put(item)print(f"生产者 {producer_id} 生产了: {item}")# 发送结束信号queue.put(f"生产者-{producer_id}-结束")def consumer(queue, consumer_id, shared_counter):"""消费者进程"""processed_count = 0while True:item = queue.get()if item.endswith("-结束"):# 如果是结束信号,放回队列以便其他消费者也能看到queue.put(item)print(f"消费者 {consumer_id} 接收到结束信号")break# 模拟消费时间time.sleep(random.uniform(0.2, 0.5))print(f"消费者 {consumer_id} 消费了: {item}")processed_count += 1# 更新共享计数器with shared_counter.get_lock():shared_counter.value += 1print(f"消费者 {consumer_id} 退出,共处理了 {processed_count} 个项目")return processed_countdef shared_memory_demo():"""共享内存演示"""# 创建进程间队列queue = multiprocessing.Queue(maxsize=10)# 创建共享计数器shared_counter = multiprocessing.Value('i', 0) # 'i' 表示整数类型# 创建生产者和消费者进程producers = []consumers = []# 启动生产者for i in range(2):producer_process = multiprocessing.Process(target=producer, args=(queue, i, 5) )producers.append(producer_process)producer_process.start()# 启动消费者for i in range(3):consumer_process = multiprocessing.Process(target=consumer, args=(queue, i, shared_counter) )consumers.append(consumer_process)consumer_process.start()# 等待生产者完成for producer in producers:producer.join()# 等待消费者完成for consumer in consumers:consumer.join()print(f"\n总共处理的项目数: {shared_counter.value}")if __name__ == '__main__':shared_memory_demo()4. 高级数据共享与同步
import multiprocessingimport timeimport numpy as npdef matrix_worker(worker_id, shared_array, lock, rows_per_worker, matrix_size):"""矩阵计算工作进程"""print(f"工作进程 {worker_id} 开始计算")# 将共享内存转换为 numpy 数组with lock:matrix = np.frombuffer(shared_array.get_obj()).reshape( (matrix_size, matrix_size) )# 计算分配的行start_row = worker_id*rows_per_workerend_row = min((worker_id+1) *rows_per_worker, matrix_size)# 执行矩阵运算(这里简单填充值)for i in range(start_row, end_row):for j in range(matrix_size):# 使用锁保护共享内存访问with lock:matrix[i, j] = i*matrix_size+j+worker_id*0.1print(f"工作进程 {worker_id} 完成计算行 {start_row} 到 {end_row-1}")def advanced_shared_memory_demo():"""高级共享内存演示"""matrix_size = 100num_workers = 4# 创建共享内存数组shared_array = multiprocessing.Array('d', matrix_size*matrix_size# 'd' 表示双精度浮点数 )# 创建锁lock = multiprocessing.Lock()# 计算每个工作进程处理的行数rows_per_worker = matrix_size//num_workers# 创建工作进程workers = []start_time = time.time()for i in range(num_workers):worker = multiprocessing.Process(target=matrix_worker,args=(i, shared_array, lock, rows_per_worker, matrix_size) )workers.append(worker)worker.start()# 等待所有工作进程完成for worker in workers:worker.join()end_time = time.time()# 将结果转换为 numpy 数组并显示部分结果with lock:result_matrix = np.frombuffer(shared_array.get_obj()).reshape( (matrix_size, matrix_size) )print(f"\n计算完成,耗时: {end_time - start_time:.2f}秒")print("矩阵左上角 5x5 部分:")print(result_matrix[:5, :5])# 验证结果expected_sum = sum(i*matrix_size+jfor i in range(matrix_size) for j in range(matrix_size))actual_sum = np.sum(result_matrix)print(f"\n期望总和: {expected_sum}")print(f"实际总和: {actual_sum}")print(f"差异: {abs(actual_sum - expected_sum)}")if __name__ == '__main__':advanced_shared_memory_demo()
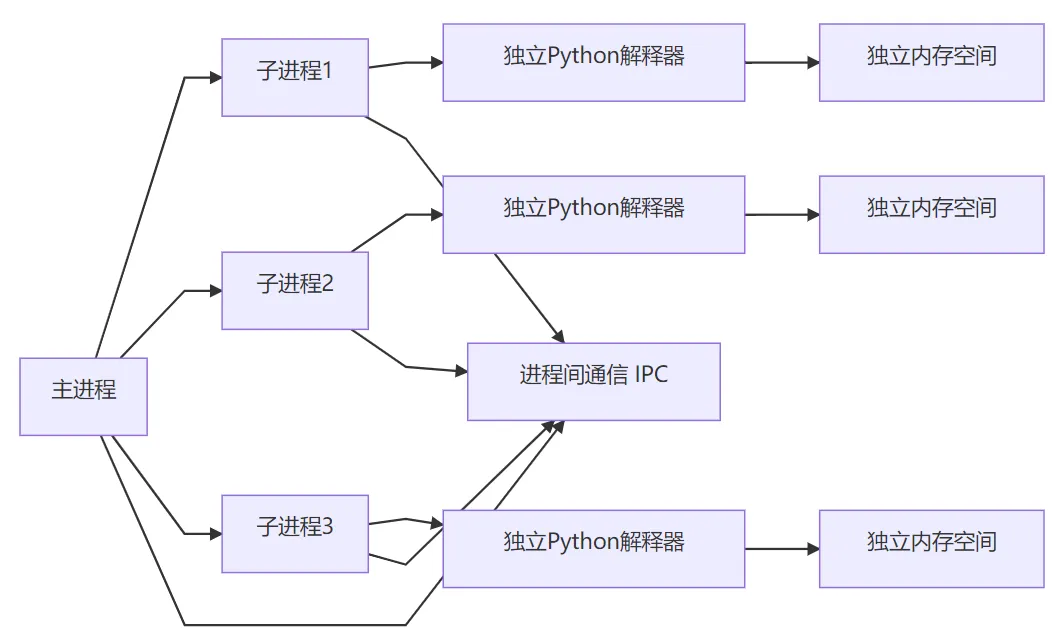
5. 底层逻辑与技术原理
核心架构
关键技术
进程创建机制:
进程间通信(IPC):
队列(Queue):基于管道和序列化
管道(Pipe):双向或单向通信通道
共享内存:使用 mmap 或系统共享内存
信号量:系统级同步原语
数据序列化:
GIL 绕过机制:
# 每个进程有独立的 Python 解释器和 GIL# 真正的并行执行,不受 GIL 限制# 适合 CPU 密集型任务
资源管理:
进程池重用进程,减少创建开销
自动清理僵尸进程
优雅的进程终止机制
进程启动方法
import multiprocessing as mp# 不同的进程启动方法if __name__ == '__main__':# 查看可用的启动方法print("可用启动方法:", mp.get_all_start_methods())# 设置启动方法mp.set_start_method('spawn') # 或 'fork', 'forkserver'# 创建进程上下文ctx = mp.get_context('spawn')# 使用指定上下文创建进程with ctx.Pool(4) as pool:results = pool.map(lambda x: x*x, range(10))print(results)
6. 安装与配置
基础安装
# multiprocessing 是 Python 标准库的一部分,无需额外安装# 验证安装python -c"import multiprocessing; print(multiprocessing.__doc__)"
环境要求
| 组件 | 最低要求 | 推荐配置 |
|---|
| Python | 2.6+ | 3.6+ |
| 操作系统 | Windows 7+/Linux 2.6+/macOS 10.6+ | 同左 |
| 内存 | 1GB | 8GB+ |
| CPU | 多核 | 多核多线程 |
平台差异配置
import multiprocessingimport platformimport osdef check_environment():"""检查多进程环境"""print(f"Python 版本: {platform.python_version()}")print(f"操作系统: {platform.system()} {platform.release()}")print(f"CPU 核心数: {multiprocessing.cpu_count()}")print(f"当前进程 PID: {os.getpid()}")# 检查启动方法try:methods = multiprocessing.get_all_start_methods()current_method = multiprocessing.get_start_method()print(f"可用启动方法: {methods}")print(f"当前启动方法: {current_method}")except AttributeError:print("启动方法检查不可用")if __name__ == '__main__':check_environment()
7. 性能指标
| 操作类型 | 执行时间 | 内存开销 | 适用场景 |
|---|
| 进程创建 | 10-100ms | 10-50MB | 长期运行任务 |
| 进程间通信 | 0.1-1ms | 可忽略 | 频繁数据交换 |
| 进程池初始化 | 100-500ms | 每个进程独立 | 批量任务处理 |
| 共享内存访问 | 0.01-0.1ms | 共享 | 大数据处理 |
8. 高级功能使用
1. 自定义进程类
import multiprocessingimport timeimport queueclass WorkerProcess(multiprocessing.Process):"""自定义工作进程类"""def __init__(self, task_queue, result_queue, worker_id, timeout=5):super().__init__()self.task_queue = task_queueself.result_queue = result_queueself.worker_id = worker_idself.timeout = timeoutself.shutdown_flag = multiprocessing.Event()def run(self):"""进程主函数"""print(f"工作进程 {self.worker_id} 启动 (PID: {self.pid})")while not self.shutdown_flag.is_set():try:# 获取任务,支持超时task = self.task_queue.get(timeout=self.timeout)if task == "SHUTDOWN":print(f"工作进程 {self.worker_id} 接收到关闭信号")break# 处理任务result = self.process_task(task)self.result_queue.put((self.worker_id, task, result))except queue.Empty:# 超时,检查是否需要关闭continueexcept Exception as e:print(f"工作进程 {self.worker_id} 错误: {e}")self.result_queue.put((self.worker_id, "ERROR", str(e)))print(f"工作进程 {self.worker_id} 退出")def process_task(self, task):"""处理具体任务"""print(f"工作进程 {self.worker_id} 处理任务: {task}")time.sleep(1) # 模拟处理时间return f"处理结果: {task.upper()}"def shutdown(self):"""优雅关闭进程"""self.shutdown_flag.set()def custom_process_demo():"""自定义进程演示"""# 创建队列task_queue = multiprocessing.Queue()result_queue = multiprocessing.Queue()# 创建自定义工作进程workers = []num_workers = 3for i in range(num_workers):worker = WorkerProcess(task_queue, result_queue, i)workers.append(worker)worker.start()# 提交任务tasks = [f"task_{i}" for i in range(10)]for task in tasks:task_queue.put(task)# 等待任务完成time.sleep(2)# 收集结果results = []while not result_queue.empty():try:result = result_queue.get_nowait()results.append(result)print(f"收到结果: {result}")except queue.Empty:break# 发送关闭信号for _ in range(num_workers):task_queue.put("SHUTDOWN")# 等待进程退出for worker in workers:worker.join(timeout=10)if worker.is_alive():worker.terminate()print("自定义进程演示完成")if __name__ == '__main__':custom_process_demo()2. 管理器(Manager)实现复杂数据共享
import multiprocessingimport timefrom multiprocessing.managers import BaseManagerclass TaskManager:"""任务管理器"""def __init__(self):self.tasks = {}self.results = {}self.lock = multiprocessing.Lock()def add_task(self, task_id, task_data):"""添加任务"""with self.lock:self.tasks[task_id] = {'data': task_data,'status': 'pending','created_at': time.time() }return Truedef get_task(self):"""获取待处理任务"""with self.lock:for task_id, task_info in self.tasks.items():if task_info['status'] == 'pending':task_info['status'] = 'processing'task_info['started_at'] = time.time()return task_id, task_info['data']return None, Nonedef complete_task(self, task_id, result):"""完成任务"""with self.lock:if task_id in self.tasks:self.tasks[task_id]['status'] = 'completed'self.tasks[task_id]['completed_at'] = time.time()self.results[task_id] = resultreturn Truedef get_stats(self):"""获取统计信息"""with self.lock:stats = {'total_tasks': len(self.tasks),'pending_tasks': sum(1 for t in self.tasks.values() if t['status'] == 'pending'),'processing_tasks': sum(1 for t in self.tasks.values() if t['status'] == 'processing'),'completed_tasks': sum(1 for t in self.tasks.values() if t['status'] == 'completed'), }return statsdef worker_process(manager, worker_id):"""工作进程"""print(f"工作进程 {worker_id} 启动")while True:# 获取任务task_id, task_data = manager.get_task()if task_id is None:# 没有任务,等待后重试time.sleep(1)continueif task_data == "SHUTDOWN":print(f"工作进程 {worker_id} 接收到关闭信号")break# 处理任务print(f"工作进程 {worker_id} 处理任务 {task_id}: {task_data}")time.sleep(2) # 模拟处理时间# 完成任务result = f"Worker {worker_id} processed: {task_data}"manager.complete_task(task_id, result)print(f"工作进程 {worker_id} 退出")def manager_demo():"""管理器演示"""# 创建自定义管理器class TaskManagerManager(BaseManager):passTaskManagerManager.register('TaskManager', TaskManager)# 启动管理器with TaskManagerManager() as manager:task_manager = manager.TaskManager()# 创建工作进程workers = []num_workers = 3for i in range(num_workers):worker = multiprocessing.Process(target=worker_process, args=(task_manager, i) )workers.append(worker)worker.start()# 添加任务for i in range(10):task_manager.add_task(f"task_{i}", f"data_{i}")# 监控进度for _ in range(5):stats = task_manager.get_stats()print(f"任务统计: {stats}")time.sleep(2)# 添加关闭任务for i in range(num_workers):task_manager.add_task(f"shutdown_{i}", "SHUTDOWN")# 等待工作进程退出for worker in workers:worker.join()print("管理器演示完成")if __name__ == '__main__':manager_demo()
9. 与同类工具对比
| 特性 | multiprocessing | threading | concurrent.futures | joblib |
|---|
| 并发模型 | 进程 | 线程 | 线程/进程池 | 进程池 |
| GIL 影响 | 无 | 受限制 | 进程池无,线程池有 | 无 |
| 内存开销 | 高 | 低 | 进程池高,线程池低 | 高 |
| 数据共享 | 需要 IPC | 直接共享 | 进程池需要 IPC | 需要序列化 |
| 适用场景 | CPU 密集型 | I/O 密集型 | I/O 和 CPU 密集型 | 数值计算 |
| 编程复杂度 | 中等 | 低 | 低 | 低 |
10. 企业级应用案例
科学计算
NumPy、SciPy 使用多进程进行并行计算
大规模数值模拟和数据处理
机器学习
数据处理
Pandas 数据框的并行处理
大规模 ETL(提取、转换、加载)流程
Web 服务
Gunicorn 等多进程 Web 服务器
并行处理多个客户端请求
金融分析
总结
Python multiprocessing 是 CPU 密集型并行计算的终极解决方案,核心价值在于:
真正的并行:绕过 GIL 限制,实现真正的多核并行
功能丰富:提供完整的进程管理、通信和同步机制
稳定可靠:进程隔离确保单个进程崩溃不影响整体
灵活配置:支持多种进程启动方法和资源管理策略
技术亮点:
进程池和任务队列简化并行编程
多种进程间通信方式(队列、管道、共享内存)
灵活的同步原语和共享数据机制
跨平台兼容性和自动资源管理
适用场景:
CPU 密集型计算任务
需要真正并行执行的应用
大规模数据处理和数值计算
需要进程隔离的稳定系统
安装使用:
# 无需安装,直接导入python -c"import multiprocessing; print('multiprocessing 模块可用')"学习资源:
官方文档:https://docs.python.org/3/library/multiprocessing.html
并发编程指南:https://docs.python.org/3/library/concurrency.html
实战教程:https://realpython.com/python-concurrency/
Python multiprocessing 模块虽然进程间通信开销较大,但在需要真正并行计算的场景中是不可替代的工具,特别适合科学计算、数据分析和机器学习等 CPU 密集型任务。