并行编程实战——CUDA环境的安装之高版本更新
- 2026-06-29 20:41:44

一、说明
在前面的CUDA环境安装中,安装过CUDA9.1,但没有安装cuDNN。随着CUDA系列的逐渐深入,对CUDA版本的要求也越来越高,不然很多新的技术没办法推进。所以只好重装驱动。甚至找了块RTX的高一些的显卡。但可惜的是,升级失败了。硬件虽然可以认出,但从Nivida官网下载的新驱动根本无法安装,在环境检查的那个环节就报无法支持。原因是Windows10的版本过低。查了下,正好小一个很小的版本号。在这个版本的Win10中只支持标准版的驱动,而NVIDIA公司已经在后续的版本不再支持标准版本转而全面支持DCH驱动。
后来只好又恢复了老的显卡,去官网下载了Nvidia App,这次倒很顺利将显卡的驱动升级到了470,CUDA支持11的初级版本。本来也想止步于此,至少大部分的CUDA相关内容可以继续展开。但天不遂人愿,在第二周正在写代码时,系统突然报“微信崩溃,恢复中”,然后好长时间没办法恢复,只好硬重启。然后,就没有然后了。再也无法进入系统,初步猜测是系统盘的固态硬盘寿命到了。
随即将电脑搬到朋友处,进行了测试确实是如此,只好换了张新的固态硬盘,重做了系统。但可笑的是,官网下载的Windows10竟然不能安装Nivdia App,总是报CUDA不支持这个操作系统。但最后还是通过升级Windows10将驱动升级到了580,支持了CUDA12.6。
本文将针对这个环境进行描述说明,重点描述CUDA12.66安装的不同与cuDNN的安装以及Pytorch的安装及相关验证方法。本文的环境是:
Windows1022h2+vistual Studio2019/2022++andconda3-2025-12-1+CUDA12.6+cuDNN8.7.9.29+ PyTorch2.10.0+cu126
从各种资料查看,理论上讲CUDA12.6可以适配cuDNN8以上及9以上的版本。但大多安装推荐的都是使用的8,故选用一个较新8的版本。vistual Studio以提前安装了2019和20022两个版本。之后安装了andconda3。
二、CUDA的安装
1、CUDA的安装
CUDA的安装方法与前文基本一致,但12.6的版本在安装时,指定路径时只有一个路径指定框架不像以前有三个指定路径的框(注意,如果C盘允许,推荐不要改变这个安装路径,对于新手不太友好,而且后面的cuDNN配置方便)。利用前文的验证方法也通过了验证,说明安装成功。此处出现了一个问题下面再说。安装成功后,用前文的各种验证方法都可以通过。
但打开VS2022或VS2019都没创建CUDA12.6运行时的这个模板,即在Vistual Studio的创建项目中没有模板可选。查询了很多资料,最简单的说是重装;其次有的说手动指定相关的文件。
在后者的说明中,查看一下相关的选项,在“C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\extras\”文件中根本没有visual_studio_integration这个文件夹。这也意味着根本就没有安装或没有安装成功VS扩展支持。想了一下,在安装CUDA时,是取消了“visual studio integration”这个安装选项的,于是觉得可能是高版本的里面需要安装或在安装VS时未选中相关的选项。
将CUDA安装程序打开,重新安装,但只安装这个选项即下图:
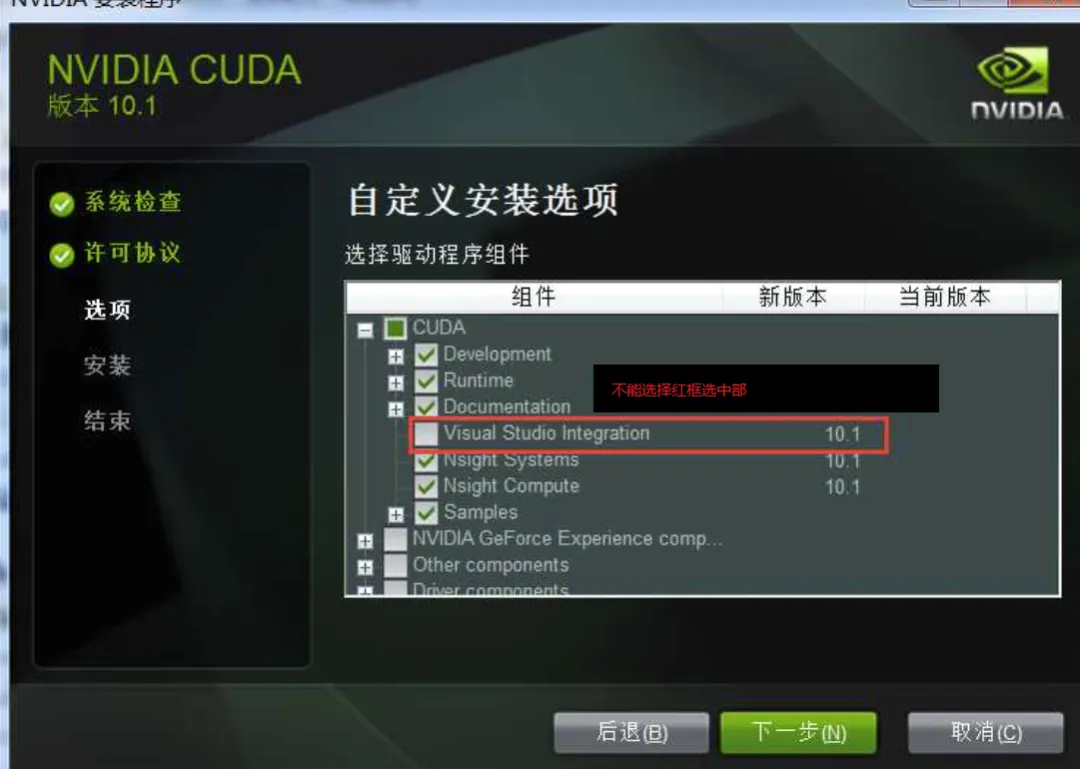
注意,图像中CUDA选项中是除了它(即红框选中部分)都选择了,而此次安装正好相反,其它所有都不选,只选这一个红框内的“visual studio integration”。重新安装后,再启动vs2019/2022,在创建新项目时,都出现了CUDA Runtime12.6这个模型。恢复成功。
所以建议在安装CUDA更高版本时,可注意此选项。这里再重申一下,较高版本的CUDA安装时,会自动进行相关环境变量的设置,如无特殊的应用或需求,一般不需要显示的进行环境变量的配置,这一点和网上的很多资料有些不同(不过,真正去设置也会发现已经设置好了)。
三、cuDNN的安装
因为要使用cdDNN,所以下载了上面的相应版本。虽然网上说9以上的版本也可以支持,但为了保险起见,还是下载了较老的版本。这里有一个不同,9以上的直接打开exe安装即可。9以下,是解压版本,即下载的是一个压缩包,解压缩后,将cuDNN相应路径名下的文件拷贝到CUDA安装的相关路径下同名文件夹下即可(即合并相同文件夹及其下面的文件)。也不用重新指定环境变量。即下图所示:
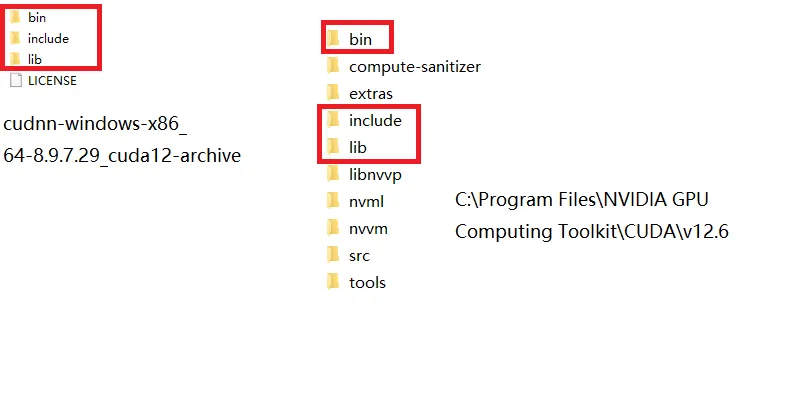
cuDNN安装完成后有一个很明显的问题,怎么验证它成功安装了。这就需要安装一个Pytorch来应用测试一下。
四、Pytorch的安装
pytorch的安装又经历了过山车一样的心情。参照相关的网上的安装说明,有好几种方法,可以下载离线包,也可以使用anaconda安装,也可以使用pip安装。这里参考使用pip安装。步骤如下:
创建虚拟环境
conda create -n pytorch_gpu_env python=3.13 #anaconda安装的Python是这个版本:python --version
conda activate pytorch_gpu_env
此处还犯了个低级错误pytorch写成了pytroch结果激活时报了个错误,无语。强烈推荐使用虚拟环境安装。
打开Pytorch的官网“https://pytorch.org/get-started/locally/”,其会自动检测当前的环境并给出相关的安装选项和命令,如下图:
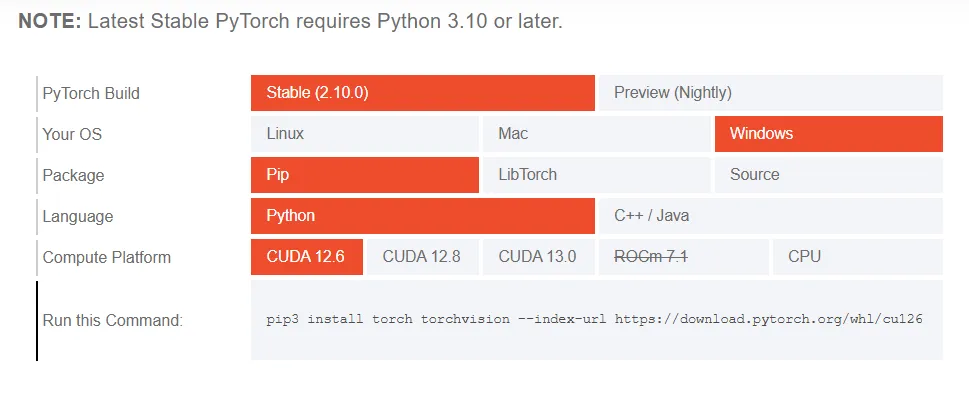
把上图最下面的命令复制出来,粘贴到虚拟环境的命令行中:
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu126
从理论上讲,就可以坐等成功了。可国内网络啊。连着报错,先是说“SSL”连接问题,然后说“远端主机强行关闭”,问了下DeepSeek,说是国内的网络的问题。解决方法推荐使用国内的镜像源。然后按照方法使用了清华的镜像。结果,确实安装成功了。但测试发现是一个CPU版本。本想着修改一下再创建一个新的虚拟环境,再装一个GPU版本,可忽然想到会不是科学的方法下载就好呢?于是用科学方法下载,果然,一分钟就安装好了。无语。干代码的,不容易。
安装成功后,使用下面的脚本测试一下:
import torch
import sys
print("=" * 50)
print("PyTorch安装信息:")
print(f"PyTorch版本: {torch.__version__}")
print(f"CUDA可用: {torch.cuda.is_available()}")
print(f"CUDA版本: {torch.version.cuda}")
print(f"cuDNN启用: {torch.backends.cudnn.enabled}")
print(f"GPU数量: {torch.cuda.device_count()}")
if torch.cuda.is_available():
print(f"当前GPU: {torch.cuda.get_device_name(0)}")
print(f"GPU内存: {torch.cuda.get_device_properties(0).total_memory / 1e9:.2f} GB")
# 测试cuDNN
x = torch.randn(1, 3, 224, 224, device='cuda')
try:
# 尝试一个使用cuDNN的操作
x = torch.nn.functional.conv2d(x, torch.randn(64, 3, 3, 3, device='cuda'))
print("cuDNN操作测试: 成功")
# 再次检查版本
print(f"cuDNN版本: {torch.backends.cudnn.version()}")
except Exception as e:
print(f"cuDNN操作测试失败: {e}")
说明,这段验证代码从网上找的。其运行结果是:
PyTorch安装信息:
PyTorch版本: 2.10.0+cu126
CUDA可用: True
CUDA版本: 12.6
cuDNN启用: True
GPU数量: 1
当前GPU: NVIDIA GeForce GTX 960
GPU内存: 4.29 GB
cuDNN操作测试: 成功
cuDNN版本: 91002
否则相关选项无法打印或干脆是None。
注意:安装可以中断,然后继续安装,不会影响进一步的安装。而且中断后也可以再次安装,会继续推进,但还会断,有耐心的可以不断尝试看是否最终可以安装成功。
如果在中断后想删除相关安装操作,可以使用下面的命令:
pip list #查看安装项目
pip uninstall torch torchvision torchaudio -y #移除相关安装
其实不如直接把这个虚拟环境删除,使用下面的命令:
conda remove -n pytroch_env --all // 删除虚拟环境名(如pytroch_env)环境及下属所有包
五、旧程序的兼容
在vs2019/2022中打开原来VS2017的CUDA项目,无法进行升级,直接报环境错误,找不到CUDA9.1的相关内容。可能如果同时安装了CUDA9.1就能够升级上来吧,没有经过实验验证。但推测可能是这样的。
在Windows上可以同时支持多个版本的CUDA的。相关的方法,可以查询资料,此处不把这个进行说明。
六、环境测试
依然沿用老的方法,直接打开VS2019/2022,在创建新项目时,选择“CUDA 12.6 Runtime”即可自动创建一个测试例程,将原来的回调函数相关部分的代码拷贝进来,如下:
#include"cuda_runtime.h"
#include"device_launch_parameters.h"
#include<stdio.h>
#include<cstdio>
#include<cstdlib>
// 回调函数
void CUDART_CB testCB(cudaStream_t stream, cudaError_t status, void* userData){
printf("enter callback!\n");
printf("cur status: %s\n", cudaGetErrorString(status));
if (userData != nullptr) {
int* d = (int*)userData;
printf("user data: %d\n", *d);
}
printf("GPU operate completed!......\n");
}
// 向量加法
__global__ voidvecAdd(constfloat* a, constfloat* b, float* c, int n){
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
c[i] = a[i] + b[i];
}
}
intmain(){
constint N = 10000;
constsize_t size = N * sizeof(float);
printf("CUDA callback demo start...\n");
// host mem
float* hA = (float*)malloc(size);
float* hB = (float*)malloc(size);
float* hC = (float*)malloc(size);
for (int i = 0; i < N; i++) {
hA[i] = i;
hB[i] = i + 1;
}
// dev mem
float* dA, * dB, * dC;
cudaMalloc(&dA, size);
cudaMalloc(&dB, size);
cudaMalloc(&dC, size);
cudaStream_t stream;
cudaStreamCreate(&stream);
// user data
int userData = 108;
printf("user data: %d\n", userData);
printf("start copy data from host...\n");//host->dev
cudaMemcpyAsync(dA, hA, size, cudaMemcpyHostToDevice, stream);
cudaMemcpyAsync(dB, hB, size, cudaMemcpyHostToDevice, stream);
printf("start kernel...\n");
int bSize = 256;
int nBlocks = (N + bSize - 1) / bSize;
vecAdd << <nBlocks, bSize, 0, stream >> > (dA, dB, dC, N);
// copy :dev->host
printf("start copy from dev...\n");
cudaMemcpyAsync(hC, dC, size, cudaMemcpyDeviceToHost, stream);
// add callback
cudaStreamAddCallback(stream, testCB, &userData, 0);
printf("host continues to work ...\n");
for (int i = 0; i < 10; i++) {
printf("host:cur num %d...\n", i);
}
// wattting
printf("waitting...\n");
cudaStreamSynchronize(stream);
for (int i = 0; i < 100; i++) {
printf("result data :%f\n", hC[i]);
}
// 清理资源
cudaStreamDestroy(stream);
cudaFree(dA);
cudaFree(dB);
cudaFree(dC);
free(hA);
free(hB);
free(hC);
printf("app end!\n");
return0;
}
程序可以正常编译并启动运行。但有一个警告出现:
Cuda12Stream.lib 和对象 D:\vs2022_cuda_project\Cuda12Stream\x64\Debug\Cuda12Stream.exp
1>LINK : warning LNK4098: 默认库“LIBCMT”与其他库的使用冲突;请使用 /NODEFAULTLIB:library
它的意思和原来开发多线程库时的“多线程调试(MT或MTd)”选择问题一样,可以不处理。也可以使用下面的方式去除警告:
右键项目——属性
配置属性-链接器-命令行
粘贴下面的代码:
/NODEFAULTLIB:LIBCMT /NODEFAULTLIB:LIBCMTD
再重新编译相关项目则没有了这个问题。
五、总结
通过本文的升级安装,同样的显卡已经可以支持相当新的CUDA版本(虽然无法支持最新的CUDA13)。在这种情况下,一般的验证型应用都可以进行开发使用了。以后有时间再把C++版本的Pytorch和TensorFlow安装起来,就可以更好的把相关软硬件利用起来。

