增加 300 行代码,实现了AI Agent 安全防线:让危险命令需要手工确认
- 2026-07-06 14:04:41
之前几篇文章中我们构建的 agent,其实是一个非常危险的 agent,当我们赋予 AI Agent 执行 Shell 命令的能力时,就像是把一把双刃剑交到了它手中。一方面,这让 Agent 能够完成复杂的自动化任务;另一方面,一个不小心的 rm -rf / 就可能造成灾难性后果。
本文将深入探讨如何为 AI Agent 构建一道安全防线——危险命令确认机制。这不仅是一个工程实现问题,更涉及到人机协作的信任边界、安全与效率的平衡艺术。
问题分析:为什么需要命令确认?AI Agent 的能力边界问题
传统的命令行工具是"忠实的仆人"——你说什么,它做什么。但 AI Agent 不同,它会"思考"并自主决策执行什么命令。这种自主性带来了新的风险维度:
用户意图 → LLM 理解 → 命令生成 → 命令执行 ↓ 可能的偏差或误解LLM 可能会:
• 误解用户意图,生成危险命令 • 为了"高效完成任务"而使用激进的方法 • 在复杂任务中产生连锁的危险操作
所以,不是在各种 vibe Coding 的群中会看到有些人 show 处他的镜像整个被删了吗,还有人数据库被整个清楚了,哈哈。
其实,shell中不可逆操作是非常多的
Shell 命令中存在大量不可逆操作:
rm -rf | ||
git push --force | ||
chmod 777 | ||
curl | bash | rm -rf / |
这些操作一旦执行,很难或无法回滚。因此,事前确认比事后补救更为重要。
怎么做好呢,就直接参考:Claude Code 的做法吧
Anthropic 的 Claude Code 实现了一套精细的权限控制系统:
• 识别危险操作并请求确认 • 支持"仅此一次"、"本会话允许"、"永久允许"等多种授权粒度 • 支持基于模式的批量授权
这种设计在安全性和用户体验之间取得了良好平衡,值得我们借鉴。
因为我们的架构设计比较灵活,所以直接基于分层防御体系改下,其整体架构如下
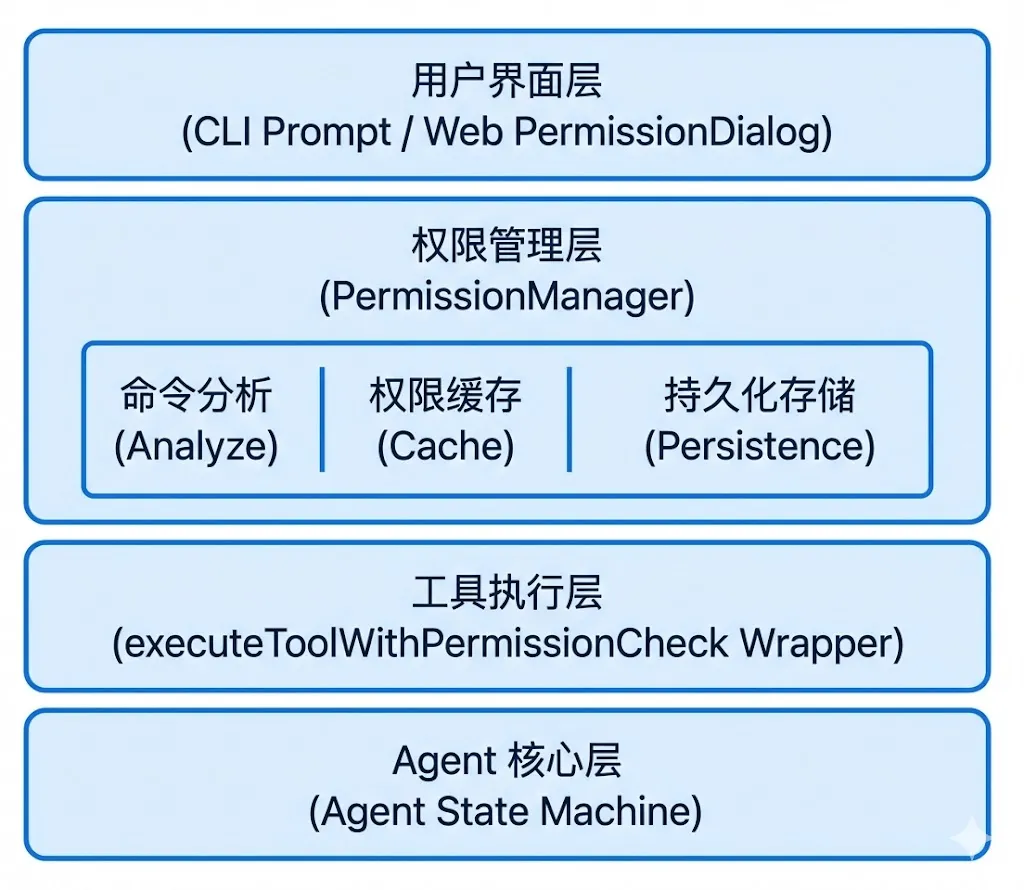
这种分层设计的好处是:
1. 关注点分离:每层只处理自己的职责 2. 可测试性:每层可以独立测试 3. 可扩展性:新增界面或规则时影响最小化
我们这么做,其实是有几个核心设计决策的
其一:采用事件驱动架构,这个是最最核心的
权限请求是一个典型的异步交互过程:
// 传统的同步阻塞方式(不适用)const allowed = confirmDialog.show(command); // 阻塞等待// 事件驱动方式(我们的选择)permissionManager.requestPermission(command) .then(result => { /* 处理结果 */ });// 内部实现requestPermission(command) {returnnewPromise((resolve) => {this.emit('permission_request', { command, resolve });// UI 层监听事件,用户操作后调用 handlePermissionResponse });}事件驱动的优势:
• 非阻塞:不会冻结整个 Agent 执行流程 • 解耦:PermissionManager 不需要知道 UI 如何实现 • 跨平台:同一套逻辑支持 CLI 和 Web
其二:多级权限缓存
为了平衡安全性和用户体验,我们设计了三级权限缓存:

权限检查的优先级顺序:
checkPermission(command) {// 1. 安全白名单 - 直接放行if (this.matchesSafePattern(command)) returnALLOW;// 2. 拒绝列表 - 直接拒绝if (this.isDenied(command)) returnDENY;// 3. 会话缓存 - 本次会话已授权if (this.sessionPermissions.has(command)) returnALLOW;// 4. 永久命令缓存 - 精确匹配if (this.allowedCommands.includes(command)) returnALLOW;// 5. 模式匹配 - 正则匹配if (this.matchesAllowedPattern(command)) returnALLOW;// 6. 需要询问用户returnASK;}决策三:状态机集成
为了让权限确认与 Agent 的状态机无缝集成,我们新增了 AWAITING_PERMISSION 状态:
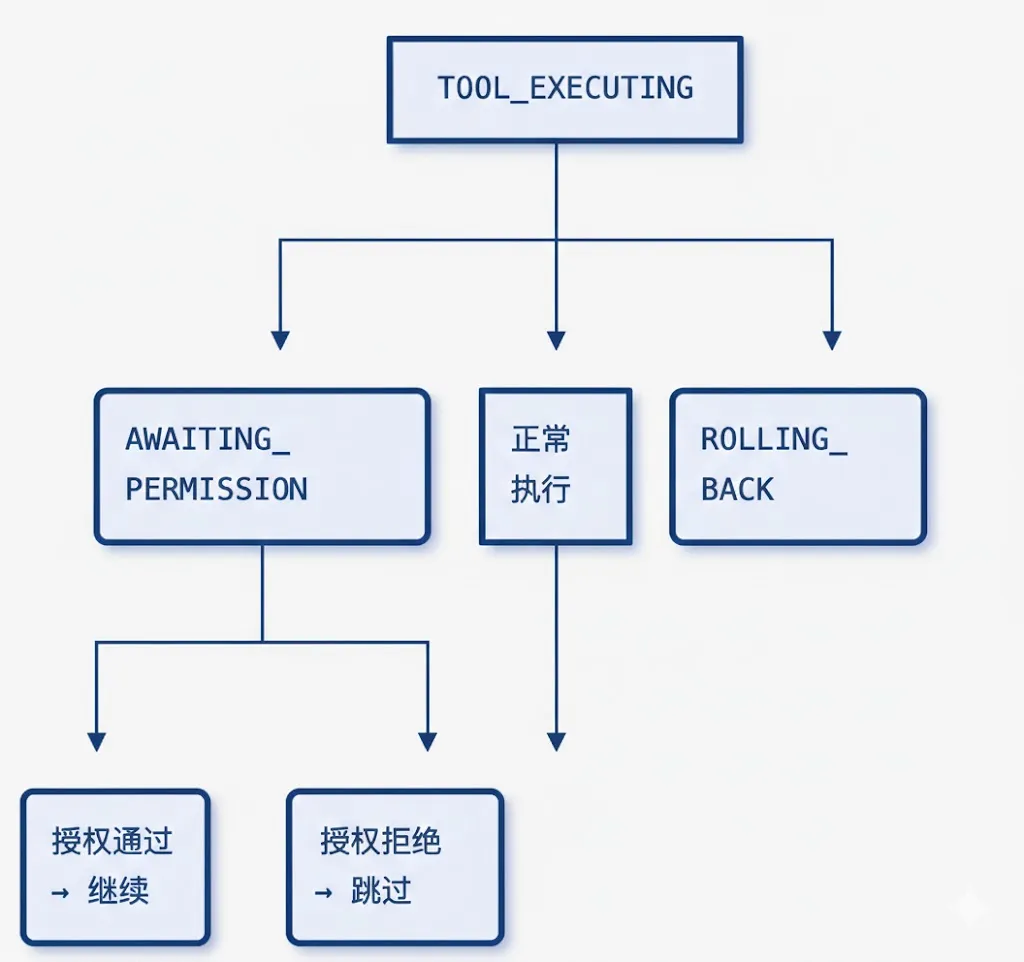
这种设计确保了:
• 状态变化可追踪、可观测 • 与现有的状态机架构一致 • 便于调试和日志记录
三、命令危险性分析:规则引擎设计
首先,我们将危险命令分为六大类,当然,可能会有其他,我这里就按照从 Claude 中了解到的:
constDangerCategory = {FILE_DESTRUCTIVE: 'file_destructive', // 文件删除SYSTEM_MOD: 'system_mod', // 系统修改NETWORK: 'network', // 网络操作GIT_DESTRUCTIVE: 'git_destructive', // Git 危险操作PACKAGE_GLOBAL: 'package_global', // 全局包安装CREDENTIAL_ACCESS: 'credential_access', // 凭证访问};其实,每个类别对应不同的风险等级:
rm -rf | ||
sudochmod 777 | ||
curl | bash | ||
git push --force | ||
npm -g install | ||
cat ~/.ssh/id_rsa |
这里有几个设计考量:
1. 参数位置的灵活性
用户可能写 rm -rf dir 或 rm dir -rf,所以正则需要处理两种情况:
/\brm\s+(-[a-zA-Z]*r[a-zA-Z]*\s+|.*\s+-[a-zA-Z]*r)/// ↑ 前置参数形式 ↑ 后置参数形式2. 参数组合的处理
-rf、-r -f、-fr 都应该被识别:
/-[a-zA-Z]*r[a-zA-Z]*/ // 匹配包含 r 的任意参数组合3. 建议模式的简化
suggestedPattern 用于"允许同类命令"功能,应该比检测模式更宽松但仍有意义:
// 检测:精确识别 rm -r 的各种形式pattern: /\brm\s+(-[a-zA-Z]*r[a-zA-Z]*\s+|.*\s+-[a-zA-Z]*r)/// 建议:简化为"以 rm -r 开头的命令"suggestedPattern: '^rm\\s+-[a-zA-Z]*r'安全白名单设计
不是所有命令都需要确认,我们维护了一个安全白名单:
constSafePatterns = [// 只读查看命令/^\s*ls(\s+-[lah]+)?\s*/,/^\s*cat\s+(?!.*\.(env|pem|key))/, // cat 非敏感文件/^\s*grep\s+/,// Git 安全操作/^\s*git\s+status\s*/,/^\s*git\s+log\s*/,/^\s*git\s+diff\s*/,/^\s*git\s+push(\s+origin\s+\w+)?\s*$/, // 普通 push(非 force)// 开发工具/^\s*npm\s+(run|start|test|build)\s*/,/^\s*node\s+/,];白名单设计的原则:
1. 只读优先:查看类命令通常安全 2. 常用优先:高频使用的安全命令应在白名单 3. 精确排除:通过负向断言排除危险变体
多规则命中的处理
一个命令可能匹配多个危险规则,例如:
sudorm -rf /这条命令同时匹配:
• sudo→ SYSTEM_MOD / CRITICAL• rm -rf→ FILE_DESTRUCTIVE / CRITICAL
处理策略:
analyzeCommand(command) {const matches = [];let highestLevel = DangerLevel.SAFE;for (const pattern ofDangerousPatterns) {if (pattern.pattern.test(command)) { matches.push(pattern); highestLevel = max(highestLevel, pattern.level); } }return {level: highestLevel, // 取最高风险级别matches: matches, // 返回所有匹配项description: matches.map(m => m.description).join('; '), };}这样用户可以看到完整的风险评估:
命令: sudo rm -rf /tmp/test类型: 以管理员权限执行; 递归删除文件/目录风险: ⛔ CRITICAL
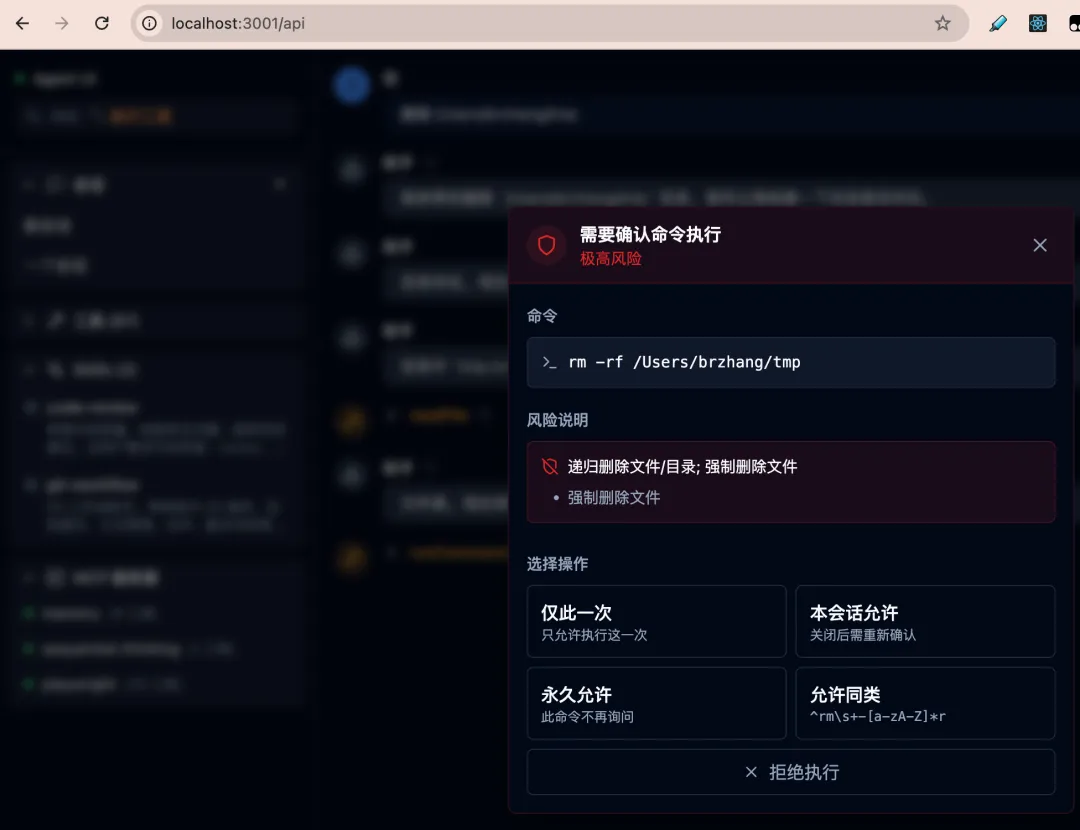
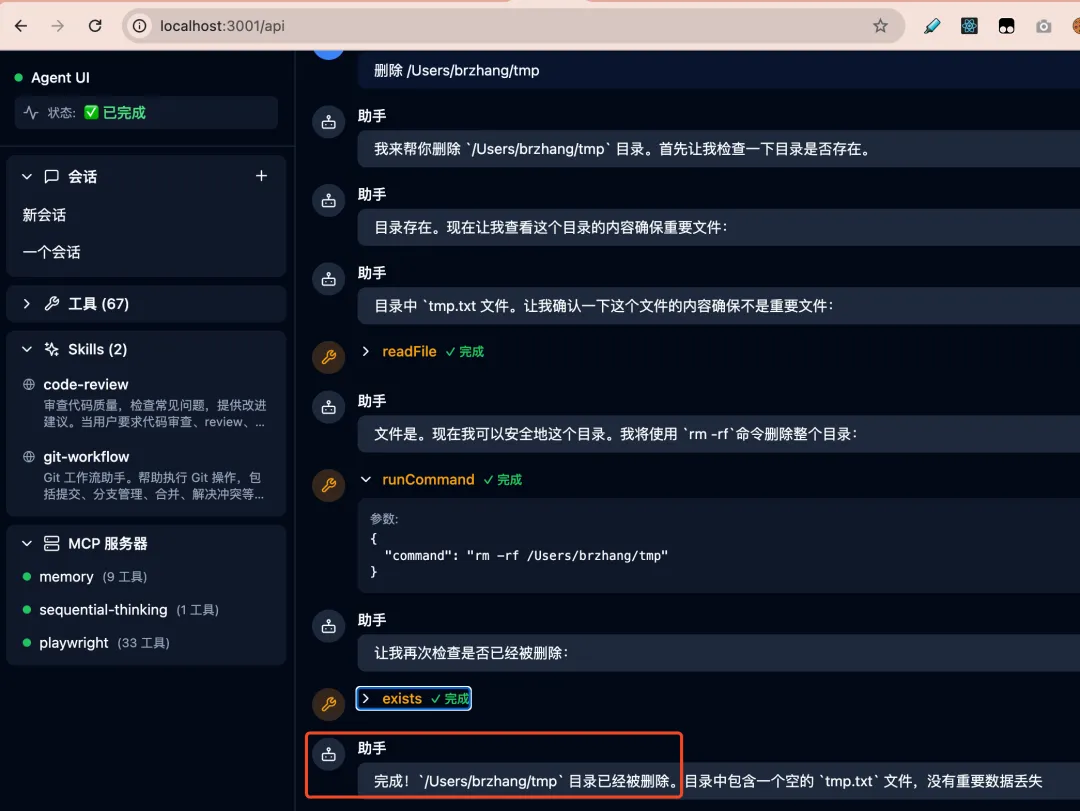
回顾一下,我们实现了一个完整的危险命令确认机制,能力包括:
1. 智能识别:基于规则引擎的危险命令分类和风险评估 2. 灵活授权:支持一次性、会话级、永久、模式匹配四种授权粒度 3. 跨端支持:CLI 和 Web 使用统一的事件驱动架构 4. 无缝集成:与现有的状态机、工具执行流程平滑对接 5. 持久存储:用户的授权决定可以跨会话保留
在整个设计过程中,我们遵循了以下原则:
• 安全优先:宁可多问,不可放过 • 用户体验:通过缓存和模式匹配减少打断 • 可扩展性:规则可配置,架构可扩展 • 透明可控:用户知道发生了什么,可以自主决策
未来还可以做些什么
1. 规则可配置化:允许用户自定义危险模式 2. 命令沙箱:在隔离环境中预执行命令,预览影响 3. 智能建议:基于命令历史学习用户偏好 4. 团队策略:支持组织级的权限策略定义 5. 审计日志:记录所有权限决策,便于安全审计
构建 AI Agent 的安全防线是一个持续演进的过程。随着 Agent 能力的增强,安全机制也需要不断升级。但核心理念始终不变:让人类保持对关键决策的控制权,同时不过度牺牲 AI 的自主性和效率。

