Ftrace系统详解:Linux 6.6 内核函数追踪框架
- 2026-07-06 01:54:07
“在内核开发与性能调优的世界里,我们常常需要回答这样的问题:“这个函数是谁调用的?”、“这段代码执行路径有多深?”、“为什么系统在这里卡住了?”。Ftrace(Function Tracer)就是 Linux 内核内置的“超级侦探”,它能在几乎零开销的情况下,为我们揭示内核函数调用的全貌。本文将带您深入Ftrace的内部世界,从编译时的埋点到运行时的动态追踪,全面解析其工作原理。”
1.引言:Ftrace是什么?
Ftrace不仅仅是一个“函数跟踪器”,它是一个可扩展的追踪框架。它通过在编译阶段向每个函数入口插入一个微小的“探针”(probe),在运行时根据需求动态决定是否激活这些探针。这种“按需启用”的设计使其在未使用时几乎没有性能损耗。
核心能力:
· 函数跟踪(function):记录函数的进入。
·函数调用图(function_graph):记录函数的进入和返回,形成完整的调用栈。
·延迟追踪(latencytracing):追踪中断关闭、抢占禁用等关键路径的延迟。
·事件追踪(eventtracing):与TraceEvents子系统深度集成。
2.Ftrace架构概览
Ftrace的架构精巧而分层,各司其职。下图展示了其核心组件之间的关系:
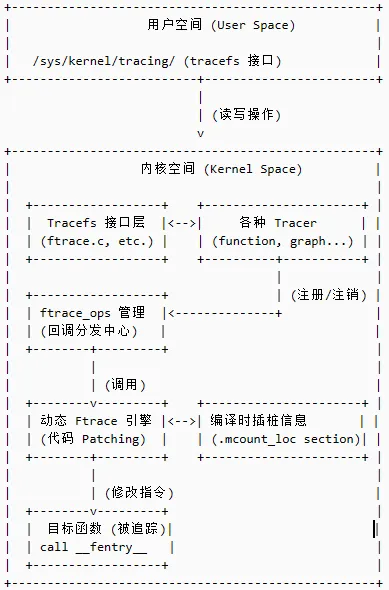
2.1 核心组件解析
1. 编译时插桩(Compile-timeInstrumentation):
· 原理:利用GCC的-pg编译选项,在每个函数的开头自动插入一条call__fentry__指令。
·作用:这是所有追踪的起点,为运行时的动态修改提供了“锚点”。
2. 运行时修改(RuntimeModification):
· 原理:在系统启动或用户触发时,内核会遍历所有__fentry__调用点,并将它们动态地修改为nop(空操作)指令。当需要追踪时,再将其修改为指向ftrace_caller的call指令。
· 作用:实现了“零开销”特性。不追踪时,函数就像从未被插桩过一样快。
3. 回调管理(CallbackManagement):
· 原理:使用ftrace_ops结构体来封装不同的追踪行为(如记录到环形缓冲区、调用BPF程序等)。所有活跃的ftrace_ops被组织成一个RCU保护的链表。
· 作用:提供了强大的可扩展性。不同的tracer或BPF程序可以同时监听同一个函数调用。
4. 过滤系统(FilteringSystem):
· 原理:通过哈希表、PID列表、模块名等方式,在函数被调用时快速判断是否应该触发回调。
·作用:避免追踪海量无关函数,精准定位目标,极大提升效率。
5. 子系统(Subsystems):
·FunctionTracer:最基础的追踪器,只记录函数进入。
·FunctionGraphTracer:更强大的追踪器,利用返回地址劫持技术,记录完整的调用-返回过程。
· StackTracer:定期采样当前调用栈,找出最深的栈使用情况。
·ProfileTracer:用于性能剖析。
2.2 关键文件
| 文件 | 功能描述 |
|---|---|
kernel/trace/ftrace.c | Ftrace 的心脏。包含核心逻辑、ftrace_ops 管理、动态修改引擎、过滤系统等。 |
kernel/trace/trace_functions.c | Function Tracer 的具体实现。 |
kernel/trace/trace_functions_graph.c | Function Graph Tracer 的具体实现。 |
arch/x86/kernel/ftrace_64.S | 架构相关代码。定义了 __fentry__ 和 ftrace_caller 的汇编实现。 |
3. 编译时插桩机制
这是Ftrace工作的第一步,发生在你编译内核的时候。3.1 mcount 插桩
当你在内核配置中启用CONFIG_FUNCTION_TRACER时,内核的顶层Makefile会自动为几乎所有C文件添加-pg编译标志。
编译前后对比:
// 编译前的 C 代码
voidkernel_function(intarg) {
do_something(arg);
}
//编译后生成的汇编代码 (x86-64)
kernel_function:
push %rbp
mov %rsp, %rbp
call __fentry__ ; <-- 这就是插桩点!
; ... 函数体 do_something(arg) ...
pop %rbp
ret
注意:在较新的内核(包括6.6)中,x86架构已从mcount迁移到更快的__fentry__,但原理完全相同。3.2 .mcount_loc Section
编译器不仅插入了call__fentry__,还做了一件非常聪明的事:它把每一个__fentry__调用指令的地址都收集起来,放到一个名为.mcount_loc的特殊段(section)中。
链接脚本(vmlinux.lds.S)片段:
SECTIONS {
.mcount_loc : {
__start_mcount_loc = .;
KEEP(*(.mcount_loc))
__stop_mcount_loc = .;
}
}
内核中的访问:
// ftrace.c
externunsignedlong__start_mcount_loc[];
externunsignedlong__stop_mcount_loc[];
// 计算总共有多少个可追踪的函数
#defineMCOUNT_RECORD_COUNT \
((__stop_mcount_loc-__start_mcount_loc) / sizeof(unsignedlong))
这个段的存在,使得内核在启动时无需扫描整个内核镜像,就能立刻知道所有潜在的追踪点在哪里,极大地加速了初始化过程。
3.3 ftrace_caller(架构相关)
当call__fentry__被激活后,程序会跳转到__fentry__。__fentry__的任务是保存所有可能被破坏的寄存器,然后调用通用的C函数ftrace_caller。简化版__fentry__ (x86-64):
SYM_FUNC_START(__fentry__)
pushq %rax
pushq %rcx
... ; 保存所有参数寄存器
call ftrace_caller ; 跳转到 C 代码处理逻辑
popq %r11
... ; 恢复所有寄存器
popq %rax
ret
SYM_FUNC_END(__fentry__)
ftrace_caller会准备好ftrace_regs结构(包含了所有寄存器的状态),并最终调用ftrace_ops_list_func,进入Ftrace的核心分发逻辑。
4.动态Ftrace机制
这是Ftrace“零开销”神话的核心。
4.1 工作原理
1. 初始状态:所有函数开头都是call__fentry__。
2. 内核初始化(ftrace_init):内核读取.mcount_loc段,获取所有调用点地址。
3. 转换为NOP:内核将所有call__fentry__指令原地修改为5字节的nop指令(0x9090909090)。此时,函数执行速度与未插桩时完全一致。
4. 启用追踪:当用户通过tracefs启用某个tracer时,内核会将需要追踪的函数的nop指令动态修改回callftrace_handler(一个指向ftrace_caller的trampoline)。
5. 禁用追踪:再次将指令改回nop。
指令修改示意图:

4.2 ftrace_ops管理
ftrace_ops是Ftrace可扩展性的基石。每个需要监听函数调用的模块(如functiontracer、BPF程序)都需要注册自己的ftrace_ops。
关键数据结构:
structftrace_ops {
ftrace_func_t func; // 回调函数指针
structftrace_hash *filter_hash; // 过滤哪些函数
structftrace_hash *notrace_hash; // 不追踪哪些函数
void*private; // 私有数据,通常是 trace_array
unsignedlongflags; // 标志位 (如 FTRACE_OPS_FL_PID)
structftrace_ops __rcu *next; // 链表指针
};
注册流程(__register_ftrace_function):
1. 参数校验。
2. 将新的ops添加到全局的ftrace_ops_list链表中。
3. 如果启用了PID过滤,将ops->func替换为ftrace_pid_func(一个包装函数)。
4. 调用update_ftrace_function()更新全局的追踪函数指针。
4.3 Ftrace函数更新(update_ftrace_function)
这个函数决定了当一个被追踪的函数被调用时,最终会执行哪个C函数。
· 无ops:设置为ftrace_stub(一个空函数)。
· 只有一个ops:直接调用该ops的func,效率最高。
· 多个ops:设置为ftrace_ops_list_func,它会遍历整个链表,依次调用每个符合条件的ops的func。
5. 函数调用流程
让我们跟随一次函数调用,看看Ftrace是如何工作的。热路径调用链:

ftrace_ops_test过滤逻辑:在ftrace_ops_list_func中,对每个ops都会调用ftrace_ops_test进行快速过滤:
1. ops是否已启用?
2. 当前进程是否处于“暂停追踪”状态(防止递归)?
3. 当前ip(指令指针)是否在filter_hash中?
4. 当前ip是否在notrace_hash中?
5. (如果启用了PID过滤)当前进程PID是否匹配?
只有全部通过,才会调用ops->func。
6. 函数过滤系统
精准过滤是高效追踪的关键。
6.1 函数哈希表
Ftrace使用哈希表来存储需要追踪(filter_hash)或不需要追踪(notrace_hash)的函数地址。
· 结构:ftrace_hash包含一个hlist_head数组(桶)。
· 查找:通过hash_long(ip,size_bits)计算桶索引,然后在桶内线性查找。
· 通配符:支持*和?,例如echo'*schedule*'>set_ftrace_filter。
6.2 模块过滤
可以通过module:function的格式来指定特定模块中的函数。
# 只追踪 ext4 模块中的 write 函数
echo 'ext4:*write*' > /sys/kernel/tracing/set_ftrace_filter
内核会解析这个字符串,并将其存储在ftrace_ops的mod_trace列表中,在ftrace_ops_test中进行匹配。
6.3 PID 过滤
这是一个非常实用的功能,可以只追踪特定进程(及其子进程)的内核活动。
echo$>/sys/kernel/tracing/set_ftrace_pid
实现上,Ftrace会将ops->func替换为ftrace_pid_func。这个函数首先检查当前task_struct的PID,如果不匹配就直接返回,否则才调用原始的saved_func。
7. 函数跟踪器实现
7.1 Function Tracer
这是最简单的tracer。它的function_trace_call回调函数会将ip(当前函数地址)和parent_ip(调用者地址)打包成一个ftrace_entry事件,写入per-CPU的环形缓冲区(ringbuffer)。
输出示例:
kworker/0:1-10 [000] ....100.123456: _raw_spin_lock <-blk_mq_run_hw_queue
这表示blk_mq_run_hw_queue函数调用了_raw_spin_lock。
7.2 Function Graph Tracer
这是Ftrace的王牌功能,它能绘制出类似用户态gprof的调用图。
核心挑战: 如何捕获函数的返回?
解决方案: 返回地址劫持。
函数入口(trace_graph_entry):
· 将函数的真实返回地址从栈上取出。
· 将其替换为一个特殊的return_to_handler地址。
· 将(真实返回地址,函数地址)保存到per-CPU的fgraph_ret_stack栈中。
函数返回:
· 函数执行完ret指令后,会跳转到return_to_handler。
· return_to_handler调用trace_graph_return。
· trace_graph_return从fgraph_ret_stack中弹出对应的条目,记录返回事件,然后跳转回真实的返回地址。
输出示例:
0) | SyS_write() {
0) | vfs_write() {
0) | ext4_file_write_iter() {
0) 0.578 us | generic_file_direct_write();
0) 1.234 us | }
0) 1.890 us | }
0) 2.100 us | }
缩进清晰地展示了调用深度和每个函数的执行时间。
8. 与周边模块的配合
Ftrace并非孤岛,它与内核的其他观测子系统紧密协作。
·TraceEvents:Ftrace的事件(如funcgraph_entry)本身就是一种TraceEvent,可以通过perf或trace-cmd等工具统一消费。
·Perf:perf工具可以通过perfprobe命令在内核函数上设置基于Ftrace的动态探针。
· eBPF:这是现代内核追踪的明星。BPF程序可以直接附加到Ftrace的ftrace_ops上,利用Ftrace的高效探针机制,在内核函数的入口/出口执行自定义的BPF代码,实现强大的可观测性和安全策略。
9. 调试定位方法 & 10.性能优化技巧
这两部分在实践中至关重要。核心思想是:精准、克制、按需。
· 调试:
·使用available_filter_functions确认你的函数是否可被追踪。
·使用set_ftrace_notrace排除干扰项(如打印函数)。
·启用record-func-recurse来检测和避免追踪死循环。
·优化:
·永远不要用*追踪所有函数,这会让系统卡死。
· 优先使用function而不是function_graph,后者开销大得多。
·使用具体的函数名,而不是宽泛的通配符。
·利用tracing_cpumask只在特定CPU上追踪。
·调整buffer_size_kb防止事件丢失。
11. 总结
Ftrace是一个集精巧设计、高性能、高灵活性于一体的内核追踪框架。它通过编译时插桩和运行时动态修改的完美结合,实现了“不用时不占资源,用时精准高效”的目标。理解Ftrace的原理,不仅能帮助您解决复杂的内核问题,更能让您深刻体会到Linux内核在工程实现上的卓越智慧。掌握Ftrace,就等于掌握了一把打开内核黑盒的万能钥匙。


