★- 原文:Simplifying LLM Fine-Tuning with Python and Ollama
【这篇文章介绍使用 Unsloth 微调模型,适合初学者系统了解模型微调流程】
作为一名对 AI 和机器学习充满热情的人,我花了不少时间探索如何让强大的语言模型在特定任务上表现得更好。今天,我想分享一份使用 Python 对大语言模型(LLM)进行微调的详细指南,以及如何通过 Ollama(一个可以在本地电脑上运行 AI 模型的工具)来使用微调后的模型。这篇内容基于我看到的一次实践演练,但我会补充更多解释和示例,使其更加全面、对初学者也更友好。
什么是对 LLM 进行微调?
想象一下你雇了一位世界级大厨,他什么菜都会做,但还需要学习你们家的祖传秘方。你不需要从零教他做菜,只要给他看几个你家菜品的例子就行。这就是微调!
微调是指在一个已经预训练好的 LLM(如 GPT 或 Llama)的基础上,让它针对你的特定任务进行“调校”。你向它提供来自你所在领域的示例,它就会调整自身知识,在这个领域表现得更出色。
工作原理:从一个已经理解英语(或其他语言)的基础模型开始,向它提供一对对“输入”(例如问题)和“输出”(例如理想答案)。模型会调整内部权重以匹配这些示例。与提示词(Prompting)的关键区别:提示词就像临时给指令(“用莎士比亚风格写作”),而微调会永久性地改变模型,使输出更加一致。与参数调优的区别:参数调优只是调整诸如“temperature”(输出有多有创意)之类的设置——就像调汽车收音机;微调则像是为越野驾驶升级发动机。
示例
假设你希望一个 LLM 从杂乱的邮件中提取信息。
未微调: 提示词:“从 ‘Hi, I’m John. Order pizza.’ 中提取姓名和订单。” 输出:可能不稳定,比如“Name: John, Food: Pizza”,或者只是一个摘要。
微调后: 用 100 封邮件示例进行训练。现在它始终输出 JSON:{"name": "John", "order": "pizza"}
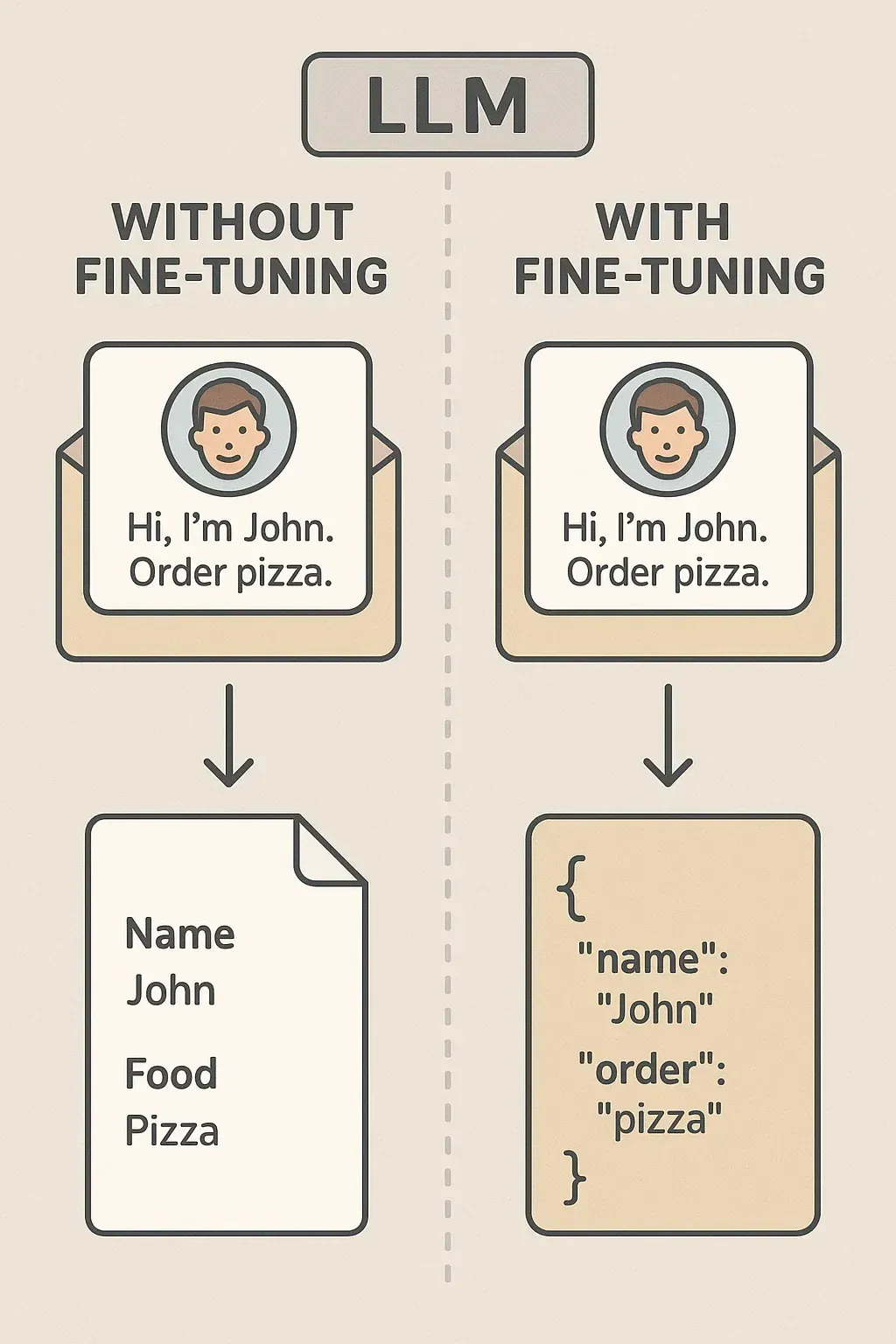 有无微调的对比
有无微调的对比什么时候应该微调 LLM?
不要什么都微调,这就像为了买菜去买一辆跑车。以下情况适合微调:
- 一致的格式/风格:当需要严格输出(如 JSON 或法律文书)而提示词无法稳定满足时
- 领域特定数据:模型没见过你的细分领域(如医学术语或公司日志)
- 节省成本:使用一个小而微调过的模型,替代像 GPT-4 这样的大模型

优缺点:
微调的替代方案
- 检索增强生成(RAG):在回答前动态引入外部数据(如搜索文档)
- 从零训练:仅适合 OpenAI 这样拥有海量数据和算力的巨头
微调 LLM 的分步工作流
下面是完整流程。我们将使用 Unsloth(免费的开源快速微调工具)和 Google Colab(免费的云 GPU,无需昂贵硬件)。基础模型:Phi-3 Mini(小而快)。
工作流:

第一步:准备数据
这是最关键的一步:垃圾数据 = 垃圾模型。需要 JSON 格式的输入-输出对。
示例数据集(用于 HTML 信息抽取,比如从网页代码中提取产品信息):
文件:extraction_dataset.json内容(为了示例的简化版,500 条中的 2 条):
[ {"input": "<div><h2>Product: Laptop</h2><p>Price: $999</p><span>Category: Electronics</span><span>Manufacturer: Dell</span></div>","output": {"name": "Laptop", "price": "$999", "category": "Electronics", "manufacturer": "Dell"} }, {"input": "<div><h2>Product: Book</h2><p>Price: $20</p><span>Category: Literature</span><span>Manufacturer: Penguin</span></div>","output": {"name": "Book", "price": "$20", "category": "Literature", "manufacturer": "Penguin"} }]
提示:如有需要可以用 AI 生成数据,但最好使用真实数据以获得最佳效果。
第二步:环境配置
使用 Google Colab 获取免费 GPU。
- 打开 Colab:前往
colab.research.google.com - 连接 T4 GPU:Runtime > Change runtime type > T4 GPU
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"!pip install --no-deps xformers "trl<0.9.0" peft accelerate bitsandbytes
输出:安装完成(约 2 分钟)。如提示请重启运行时。
检查 GPU:
import torchprint(torch.cuda.is_available()) # 应输出 Trueprint(torch.cuda.get_device_name(0)) # 例如 Tesla T4
第三步:加载模型
选择一个基础模型(如 Phi-3 Mini)。
from unsloth import FastLanguageModelmodel_name = "unsloth/Phi-3-mini-4k-instruct"max_seq_length = 2048model, tokenizer = FastLanguageModel.from_pretrained( model_name, max_seq_length=max_seq_length, load_in_4bit=True)
输出:下载模型(小模型约 5–10 分钟)。
第四步:数据预处理
将输入格式化为单个字符串。
import jsonfrom datasets import Datasetwith open("extraction_dataset.json", "r") as f: data = json.load(f)defformat_prompt(item):returnf"{item['input']}\n{json.dumps(item['output'])}<|endoftext|>"formatted_data = [{"text": format_prompt(item)} for item in data]dataset = Dataset.from_list(formatted_data)print(formatted_data[0]["text"])
输出示例:
<div><h2>Product: Laptop</h2><p>Price: $999</p><span>Category: Electronics</span><span>Manufacturer: Dell</span></div>{"name": "Laptop", "price": "$999", "category": "Electronics", "manufacturer": "Dell"}<|endoftext|>
第五步:添加 LoRA 适配器
LoRA 让微调更高效(只训练一小部分参数)。
model = FastLanguageModel.get_peft_model( model, r=16, target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"], lora_alpha=16, lora_dropout=0, bias="none", use_gradient_checkpointing="unsloth", random_state=3407)
输出:“Unsloth: Patched 32 layers…”(很快)。
什么是 LoRA?低秩适配:为模型添加“外挂”层,只训练约 1% 的参数,节省时间和内存。
第六步:训练模型
使用 SFTTrainer。
from trl import SFTTrainerfrom transformers import TrainingArgumentstrainer = SFTTrainer( model=model, tokenizer=tokenizer, train_dataset=dataset, dataset_text_field="text", max_seq_length=max_seq_length, args=TrainingArguments( per_device_train_batch_size=2, gradient_accumulation_steps=4, warmup_steps=5, max_steps=60, learning_rate=2e-4, fp16=not torch.cuda.is_bf16_supported(), bf16=torch.cuda.is_bf16_supported(), logging_steps=1, optim="adamw_8bit", weight_decay=0.01, lr_scheduler_type="linear", seed=3407, output_dir="outputs", ),)trainer.train()
输出:损失值逐步下降的进度条(500 条样本约 10 分钟)。
第七步:测试推理
FastLanguageModel.for_inference(model)messages = [{"role": "user", "content": "<div><h2>Product: Phone</h2><p>Price: $500</p><span>Category: Gadgets</span><span>Manufacturer: Apple</span></div>"}]inputs = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")outputs = model.generate(inputs, max_new_tokens=256, use_cache=True)print(tokenizer.batch_decode(outputs)[0])
输出:
User: <div><h2>Product: Phone</h2><p>Price: $500</p><span>Category: Gadgets</span><span>Manufacturer: Apple</span></div>Assistant: {"name": "Phone", "price": "$500", "category": "Gadgets", "manufacturer": "Apple"}
如果不一致,继续训练!
第八步:导出为 Ollama 可用的 GGUF
model.save_pretrained_gguf("fine_tuned_model", tokenizer, quantization_method="q4_k_m")
然后下载(约 10–20 分钟)。
第九步:为 Ollama 创建 Modelfile
安装 Ollama(ollama.com)。
终端中:
cd ~/Downloadsmkdir ollama-testmv unsloth.Q4_K_M.gguf ollama-test/cd ollama-testtouch Modelfilenano Modelfile
Modelfile 内容:
FROM ./unsloth.Q4_K_M.ggufPARAMETER temperature 0.8PARAMETER top_p 0.9PARAMETER stop "<|endoftext|>"TEMPLATE "{{ .Prompt }}"SYSTEM "You are a helpful AI assistant."
创建模型:
ollama create html-extractor -f Modelfile
第十步:在 Ollama 中运行
ollama run html-extractor
提示:粘贴 HTML 示例。 输出:提取后的 JSON(本地、私有)。
最佳实践与常见陷阱
- 扩展:使用更大模型(如 Llama 3.1)效果更佳
微调中的伦理
总结
对大语言模型进行微调,就像为你的 AI 项目赋予超能力——将一个通用工具转变为为你需求量身定制的专业专家。按照本指南中的清晰步骤:收集高质量数据、搭建环境、使用 Unsloth 进行训练,并通过 Ollama 部署,你就能创建出在特定任务上表现精准且一致的定制模型。无论是从 HTML 中抽取数据、构建细分领域的客服回复,还是应对专业场景的挑战,微调都让这一切对初学者也触手可及。

