学会Python正则表达式:秒变文本搜索、匹配、筛选高手!
- 2026-07-02 12:01:51
学会Python正则表达式:秒变文本搜索、匹配、筛选高手!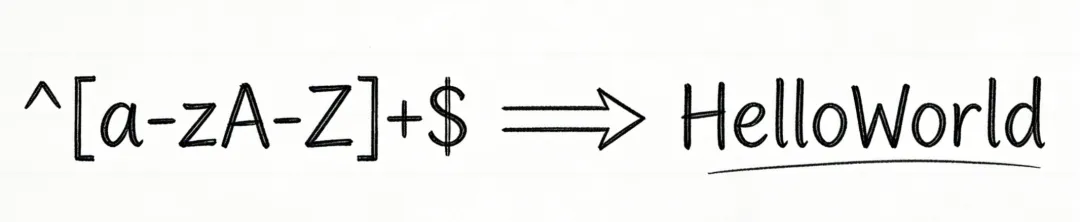

1.“摸鱼”新技能!用Python让Word自动干活,我喝茶它加班 2.要用 Python 爬虫,这些基础知识你一定要懂! 3.手把手教你 “ 爬取小红书评论内容 ”,0基础也能上手的 Python 爬虫实战! 4.告别手敲界面!用Qt Designer"拖拉拽"搞定Python GUI 5.超7000万次下载!Python自动化神器PyAutoGUI,助你轻松准时下班! 6.告别命令行,可视化的打包" 神器 "!轻松让 Python 程序转 EXE 7.用3分钟学会 Python 自动发邮件,定时推送+各种附件一劳永逸! 8.企业微信自动发送图文、文件、音视频 Python 实现指南 9.Pandas +Excel:数据筛选、VLOOKUP、透视、公式、绘图 一个案例全搞定 10.Python 生成二维码:自定义背景、Logo 与样式,批量生成超实用案例! 11.用Python玩转PDF:文字提取/图片抓取/转PPT技巧(附完整代码) 12.Python抓取摄像头图像,进行AI识别(四):AI火焰自动预警的实现
关注我,学习更多实用Python知识
🌈Hi,小伙伴们~
🛠️当需要匹配、搜索、替换文本内容时,正则表达式可能是你当之无愧的首选!它通过特定规则组成的模式(Pattern),能精准匹配文本中的目标字符,无论是在格式验证、文本处理、网络爬虫还是日志分析,正则表达式都扮演着重要角色
🎯今天,梳理和总结一下它的用法,帮你跨过它那看似复杂的语法门槛~✨
一、正则表达式核心原理 ⚙️
本质:是用特殊符号描述的字符串匹配规则。想象成一个"文本筛子":你定义好筛孔的形状和大小,文本经过时,符合规则的部分就被"筛"出来
🎯核心思想 :用简短的代码描述复杂的文本模式,而不是写冗长的判断逻辑
二、常用符号速记表 📚
3.1 基本匹配 🔤
\d→ 数字(0-9) 0️⃣1️⃣2️⃣\w→ 单词字符(字母/数字/下划线)\s→ 空白字符(空格、制表符等) ␣.→ 任意单个字符(除了换行符) 🎲^→ 字符串开头$→ 字符串结尾
3.2 数量控制 🔢
*→ 0次或多次 ⭕⭕⭕+→ 1次或多次 1️⃣/1️⃣2️⃣3️⃣?→ 0次或1次 0️⃣/1️⃣{n}→ 正好n次 3️⃣3️⃣3️⃣{n,m}→ n到m次 2️⃣3️⃣
3.3 逻辑与分组 🧩
[abc]→ 匹配a、b、c中任意一个 🅰️/🅱️/🅲️[a-z]→ 匹配a到z任意一个字母 🔤|→ 或(匹配左边或右边) ↔️()→ 分组(提取这部分内容) 📦
3.4 特殊字符与转义 🔧
\.→ 匹配实际的点号(不是任意字符) ⚫\\→ 匹配反斜杠 \(不是转义符) ⬅️\*→ 匹配*号(不是重复符) ✳️\+→ 匹配+号(不是多次符) ➕\?→ 匹配?号(不是可选符) ❓\t→ 匹配制表符 ⇥\n→ 匹配换行符 ↵\r→ 匹配回车符 ↩
3.5 预定义字符集 📦
\D→ 匹配非数字字符 🔢\W→ 匹配非单词字符 🔤\S→ 匹配非空白字符 ␣\b→ 匹配单词边界位置 🚧\B→ 匹配非单词边界位置 🚧
三、实用案例精炼 💼
✅3.1 数据验证之邮箱
# 邮箱验证defis_valid_email_advanced(email): pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'return bool(re.match(pattern, email))# 解析: ^[a-zA-Z0-9._%+-]+ 用户名:允许更多特殊字符 @ 必须有@ [a-zA-Z0-9.-]+ 域名部分:允许点号和中划线 \.[a-zA-Z]{2,}$ 顶级域名:至少2个字母✅3.2 数据验证之手机号码
# 手机号验证def is_valid_phone(phone):return bool(re.match(r'^1[3-9]\d{9}$', phone))# 解析:^ - 字符串开头锚点,必须从开头匹配1 - 必须以数字1开头(中国手机号标准)[3-9] - 第二位必须是3-9中的任意一个数字\d{9} - 后面必须有正好9个数字$ - 字符串结尾锚点,必须匹配到结尾✅3.3 信息提取
# 从混合文本中提取关键信息text = "张三,电话138-1234-5678,邮箱zhangsan@qq.com"# 提取姓名、电话、邮箱name = re.search(r'^(.+?),', text).group(1)phone = re.search(r'电话(\S+)', text).group(1)email = re.search(r'邮箱(\S+)', text).group(1)✅3.4 文本清洗 🧹
# 清理不规范数据dirty_text = "价格:$100.00 特价!!优惠¥80.5元"# 提取所有价格数字prices = re.findall(r'[¥$](\d+\.?\d*)', dirty_text)print(prices) # ['100.00', '80.5']# 清理特殊字符cleaned = re.sub(r'[!!]', '', dirty_text)print(cleaned) # 价格:$100.00 特价优惠¥80.5元四、记住这5个常用模式 🎯
📧 邮箱: \w+@\w+\.\w+📱 手机号: 1[3-9]\d{9}🌐 网址: https?://\S+🖥️ IP地址: \d+\.\d+\.\d+\.\d+🇨🇳 中文: [\u4e00-\u9fa5]+
五、工作原理图解 📈
原始文本:"我的电话是138-1234-5678"正则模式:r"(\d{3})-(\d{4})-(\d{4})"匹配过程:1. 🔍 正则引擎扫描文本2. ✅ 找到"138-1234-5678"符合模式3. 📦 括号分组捕获: group(0): "138-1234-5678"# 整个匹配 group(1): "138"# 第一个括号 group(2): "1234"# 第二个括号 group(3): "5678"# 第三个括号六、两个重要技巧 ⚡
6.1 贪婪 🐷 vs 非贪婪 🐇
text = "<div>标题</div><div>内容</div>"# 贪婪匹配(默认):尽可能多地匹配greedy = re.search(r'<div>.*</div>', text)print(greedy.group()) # <div>标题</div><div>内容</div># 非贪婪匹配(加?):尽可能少地匹配lazy = re.search(r'<div>.*?</div>', text)print(lazy.group()) # <div>标题</div>✅ 总结:要尽可能多地匹配就贪婪,少匹配就非贪婪
6.2 编译提高效率 ⚡
# 如果需要多次使用同一个正则,先编译pattern = re.compile(r'\d+')# 然后重复使用result1 = pattern.findall(text1)result2 = pattern.findall(text2) # 更快!七、总结 💡
记住思维方式:先想清楚你要匹配的什么特征,然后用符号去描述这个特征,比如匹配电话号码 → "1开头,后面10个数字" → 1\d{10}
大多数情况下,掌握上面列出的基本符号就足够解决80%的实际问题了
💡 关注我,每周分享 Python 干货 × 操作技巧
📌 如果这篇文章对你有帮助,欢迎:
👍 点赞 | ⭐ 收藏 | 🔄 分享给朋友
👇点击阅读往期文章
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

