用一行Python代码,把PDF转换为Word
- 2026-07-06 00:22:55
用一行Python代码,把PDF转换为Word
1分钟吃透半导体产业链:从沙子到你的手机,科技的“造物密码”藏在这里! 一张流程图,带你真正看懂「研究计划」怎么写 当情绪可以被“画出来”:一幅用 Python 描绘的情绪地形图 科技巨头的赚钱密码:从营收结构看数字经济的底层逻辑 谷歌发布:Aluminium OS:谷歌的人工智能首要桌面革命 OpenAI推出Prism,科研效率神器。
有没有遇到过这种情况: 有时需要将一个PDF文件转换为Word文档。
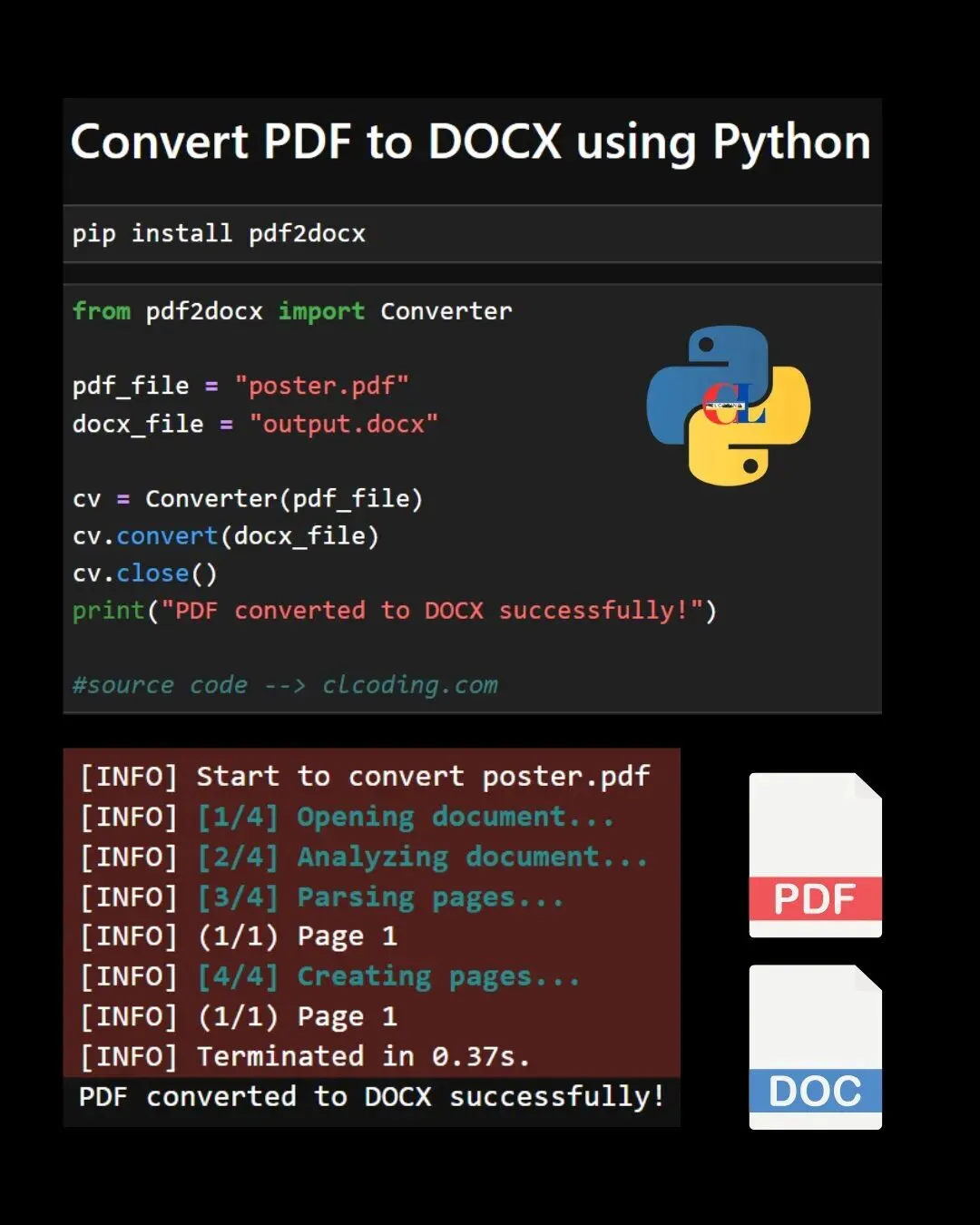
今天分享一个真正能省时间的办法👇 用 Python,把 PDF 直接转成 Word。
pdf2docx是个超实用的Python工具!它的工作流程很简单:先用PyMuPDF把PDF里的内容“抠”出来,再用一套规则把页面布局(比如段落位置、图片排版)摸清楚,最后用python-docx把这些内容“写”成DOCX文件。
要是你碰到这种需求——从PDF里拿文字、图片或者图表,还不想让原来的排版乱掉(比如标题位置、图片对齐方式),用pdf2docx准没错!
第一步:安装pdf2docx
pip install pdf2docx第二步:转换PDF文档
from pdf2docx import Converterpdf_file = "poster.pdf"docx_file = "output.docx"cv = Converter(pdf_file)cv.convert(docx_file)cv.close()print("PDF converted to DOCX successfully!")除了编程方式,pdf2docx还支持命令行操作。以下是使用命令行进行全部页面转换的命令:
pdf2docx convert example.pdf example.docx同样,也可以使用 start和 end参数来指定转换的页面范围。
pdf2docx能够解析并重新创建页面布局,包括页面边距、章节、列(仅支持1或2列)、页眉和页脚(待办事项)、段落的水平对齐(左/右/居中/两端对齐)和垂直间距等。它还能够解析并重新创建图像和表格,包括边框样式、底纹样式、合并单元格、嵌套表格等。 然而,pdf2docx也有一些限制,例如它仅支持基于文本的PDF文件、从左到右的语言、正常的阅读方向,不支持单词变换或旋转。此外,基于规则的方法不能100%转换PDF布局。
更多关于
pdf2docx的详细信息,包括安装指南、快速开始、命令行界面、图形用户界面和技术文档,都可以在其官方文档中找到。如果需要进一步的帮助,可以参考其在GitHub上的项目页面。
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 算法即宪法——当国家用代码分配资源,公平性就成了比选举更重要的合法性来源
- 程序员为何觉得少儿编程无用?3个误区你也可能犯了
- 滚筒洗衣机故障代码E21,怎么维修?请看视频.
- deepseek生成的代码怎么使用
- 猜猜我在哪兒,用python來得到一張照片的信息.
- PyWebIO:为Python开发者提供了一种快速、简洁的方式来创建Web应用,无需学习前端技术
- Pylir :让你的 Python 跑得像 C++ 一样快
- 视频:小牛顿慧编程精彩十周年!
- 5行代码复刻 OpenAI 数据神技!这个开源项目让 Text-to-SQL 彻底告别“人工智障”.
- 让AI写代码更靠谱的秘诀:先规划,后记录,再验证
