1. 简介:什么是 Numba,为何需要它?
1.1. Python 的性能瓶颈
Python 以其简洁易读的语法和丰富的库而广受喜爱,是许多开发者的首选语言。然而,当处理计算密集型任务时,尤其是涉及大量数值计算的循环时,Python 的性能常常会成为瓶颈。由于其解释型语言的特性,代码在运行时被逐行翻译和执行,这与 C 或 C++ 等编译型语言相比,效率要低得多。
1.2. Numba:你的 Python JIT 编译器
Numba 是一个专门为科学计算和数值密集型 Python 代码设计的即时(Just-in-Time, JIT)编译器。它能够在你运行代码时,将你的 Python 函数“即时”编译成高度优化的机器码,从而实现惊人的性能提升。
JIT 编译器是如何工作的?
我们可以用一个简单的类比来理解它:
- 标准 Python 解释器:就像一位同声传译员,逐句地听取(读取代码)并翻译(执行代码)。这个过程重复进行,效率较低。
- Numba JIT 编译器:更像一位专业笔译员,他会先完整地阅读整个段落(你的函数),理解其含义和上下文,然后将其翻译成一篇精炼、优美的文章(优化的机器码)。之后,每次需要时,你都可以直接阅读这篇已翻译好的文章,速度飞快。
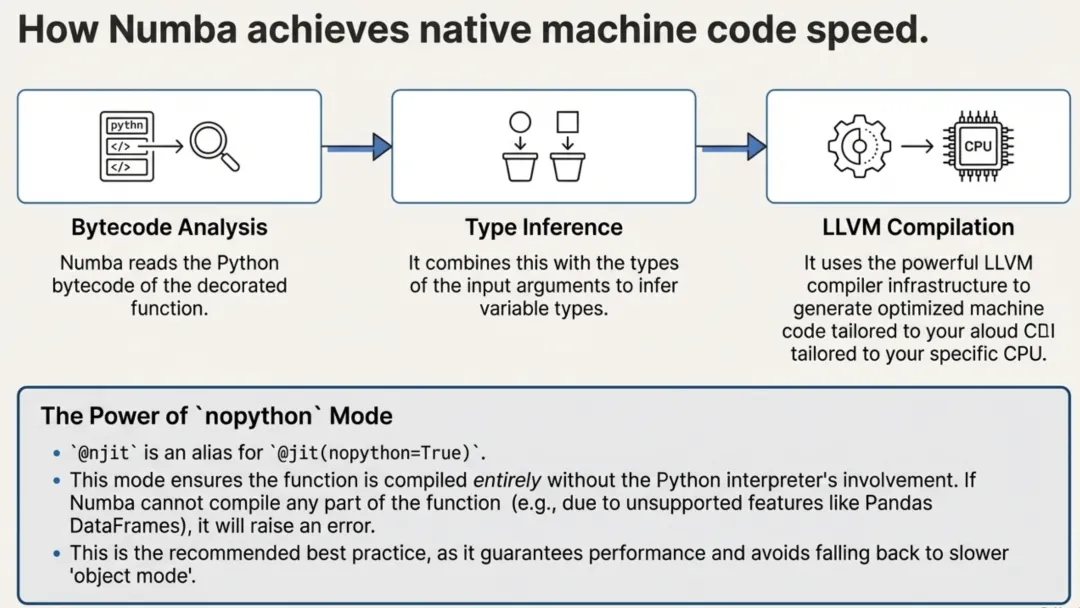
根据 Numba 的架构,其核心工作流程可以概括为以下几个步骤:
- 接收 Python 函数:Numba 读取你用特定装饰器标记的 Python 函数的字节码。
- 翻译为 Numba 中间表示 (Numba IR):Numba 将 Python 字节码翻译成其自有的、针对性能优化的中间表示。
- 生成机器码:Numba IR 随后被传递给 LLVM 编译器基础设施,由 LLVM 为你的特定硬件(如 CPU 或 GPU)生成高度优化的本地机器码。
这个过程使得原本纯 Python 的数值计算代码能够以接近 C 语言的速度运行,而你几乎不需要修改原始代码的逻辑。接下来,让我们看看如何轻松地开始使用 Numba。
2. 第一个 JIT 编译函数:@jit 装饰器的魔力
2.1. @jit 装饰器入门
在 Numba 中,最核心、最常用的工具就是 @jit 装饰器。装饰器是 Python 的一种特殊语法(以 @ 符号开头),用于修改紧随其后定义的函数。通过在函数定义前加上 @jit,你就在告诉 Numba:“请编译这个函数!”
让我们来看一个简单的例子。这是一个纯 Python 函数,用于计算一个大数组中所有元素的和。
纯 Python 版本:
import numpy as npdef sum_array(arr): total = 0.0 for i in range(arr.shape[0]): total += arr[i] return total
现在,我们使用 Numba 来加速它。你唯一需要做的就是导入jit并将其作为装饰器添加到函数上。
Numba 加速版本:
from numba import jitimport numpy as np@jitdef sum_array_numba(arr): total = 0.0 for i in range(arr.shape[0]): total += arr[i] return total
就是这么简单!除了增加 @jit 这一行,函数的内部逻辑完全没有改变。
2.2. 理解懒编译(Lazy Compilation)
Numba 采用了一种叫做“懒编译”(Lazy Compilation)的策略。这意味着 Numba 不会立即编译函数,而是会等到函数第一次被调用时才开始工作。在第一次调用时,Numba 会分析传入参数的类型(例如,一个 float64 类型的 NumPy 数组),然后编译一个专门针对该参数类型的优化版本。
这个机制带来一个非常重要的后果: 第一次调用 JIT 编译的函数会比较慢,因为它包含了编译本身所需的时间。但是,后续所有使用相同参数类型的调用都会直接使用已编译好的机器码,速度会快得多。
2.3. 最佳实践:使用 nopython 模式
为了获得最佳性能,官方文档强烈推荐使用 Numba 的 nopython 模式。在此模式下,Numba 会将整个函数完全编译成机器码,完全脱离 Python 解释器运行。这是实现最大加速的关键。
你可以通过 @jit(nopython=True) 来启用此模式。为了方便,Numba 提供了一个更简洁的快捷方式:@njit。
from numba import njitimport numpy as np@njit # 等同于 @jit(nopython=True)def sum_array_fast(arr): # ... 函数体不变 ...
为什么 nopython 模式如此重要?如果 Numba 在 nopython 模式下遇到无法编译的代码(例如,使用了它不支持的 Python 特性或第三方库),编译就会失败并报错。相比之下,普通的 @jit 可能会“回退”到对象模式(Object Mode)。在对象模式下,Numba 仍然会编译它能处理的部分(比如循环),但无法处理的部分会回调 Python 解释器来执行。这种模式虽然能保证代码可以运行,但性能提升非常有限,并且 Numba 通常会发出一个 NumbaWarning 来提醒你发生了回退。
因此,我们的目标始终是确保代码能够在 nopython 模式下成功编译。
3. 超越基础:面向 CPU 和 GPU 的编译
Numba 不仅仅能进行基础的 JIT 编译,还提供了更高级的功能来进一步压榨硬件性能。
3.1. 进一步优化 CPU 代码
通过为 @njit 装饰器提供参数,你可以启用更多 CPU 优化选项。
- 作用:这个选项会将函数的编译结果保存到一个基于文件的缓存中。
- 好处:当你再次运行整个脚本时,Numba 会直接从缓存加载已编译好的函数,从而避免了重新编译的开销。这对于开发和测试阶段非常有用,可以节省大量时间。
- 作用:启用 Numba 的自动并行化功能。它会分析你的循环,并在可能的情况下将其分配到多个 CPU 核心上并行执行。
- 用法:此选项需要与
prange() 结合使用,用它来替代 range()。Numba 会自动将 prange() 循环的迭代任务分配给多个线程。 - 建议:为了获得最佳效果,通常应将
parallel=True 和 prange() 应用于函数中最外层的循环。
语法示例:
from numba import njit, prange@njit(parallel=True, cache=True)def parallel_sum(arr): total = 0.0 # 使用 prange 进行并行循环 for i in prange(arr.shape[0]): total += arr[i] return total
3.2. 为 CUDA GPU 编译
Numba 最强大的功能之一是它能够将 Python 函数编译为在 NVIDIA GPU 上运行的 CUDA 代码。这使得利用 GPU 强大的并行计算能力变得异常简单。
为 GPU 编译需要使用不同的装饰器:@cuda.jit。
理解主机和设备内存 在开始编写 CUDA 代码之前,必须理解一个核心概念:CPU(主机)和 GPU(设备)拥有各自独立的内存空间。这意味着,如果想让 GPU 处理数据,你必须首先将数据从 CPU 的内存中显式地复制到 GPU 的显存中。计算完成后,再将结果从 GPU 显存复制回 CPU 内存。这个数据传输过程是 GPU 编程的基础。
让我们看一个简单的向量加法示例。
from numba import cudaimport numpy as np@cuda.jitdef add_kernel(x, y, out): # 计算全局唯一的线程索引 idx = cuda.grid(1) # 边界检查,确保线程不会访问越界内存 if idx < x.shape[0]: out[idx] = x[idx] + y[idx]# 准备数据n = 1000000x = np.arange(n).astype(np.float32)y = 2 * xout = np.empty_like(x)# 将数据从 CPU 内存(主机)复制到 GPU 显存(设备)x_device = cuda.to_device(x)y_device = cuda.to_device(y)out_device = cuda.to_device(out)# 配置并启动内核threads_per_block = 128blocks_per_grid = (x.size + (threads_per_block - 1)) // threads_per_blockadd_kernel[blocks_per_grid, threads_per_block](x_device, y_device, out_device)# 将结果从 GPU 显存复制回 CPU 内存out_host = out_device.copy_to_host()
对于初学者来说,理解以下两个核心概念至关重要:
- 内核函数 (Kernel Function):被
@cuda.jit 装饰的函数被称为“内核”。你编写内核的逻辑时,是从单个线程的视角出发的。在上面的例子中,add_kernel 函数描述了每个线程应该做什么:获取自己的唯一 ID,然后对数组中对应位置的两个元素进行相加。 - 内核调用 (Kernel Invocation):启动内核的语法
add_kernel[blocks_per_grid, threads_per_block](...) 非常特殊。这对方括号里的配置告诉 GPU 要启动多少个线程,以及如何组织它们。启动的线程总数等于 blocks_per_grid * threads_per_block。其中,blocks_per_grid = (x.size + (threads_per_block - 1)) // threads_per_block 是一种标准的计算模式,用于确保我们启动足够多的线程块来覆盖数组中的每一个元素,即使数组的大小不是线程块大小的整数倍也能正确处理。
4. 总结
通过本教程,你已经掌握了使用 Numba 加速 Python 代码的基础知识。以下是三个最重要的核心要点:
- JIT 编译 Numba 使用
@jit(以及性能更佳的 @njit)装饰器,在函数首次执行时将其即时编译成高速的机器码。 - 首次调用开销 第一次调用 JIT 编译的函数会包含编译时间,因此速度较慢。真正的性能提升体现在后续的所有调用中。
- 多目标编译 Numba 不仅能优化 CPU 代码(通过
parallel=True 等选项实现并行化),还能使用 @cuda.jit 将函数编译为在 NVIDIA GPU 上运行的 CUDA 内核,从而利用大规模并行计算的能力。
Numba 的功能远不止于此。当你准备好深入学习时,可以探索内存管理、调试工具和更高级的优化技巧。查阅 Numba 官方文档是开启下一阶段学习之旅的最佳途径。
Reference
[1] https://numba.pydata.org/
[2] https://numba.readthedocs.io/en/stable/user/index.html



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
