slabinfo 是干什么的?——Linux 内核 中/proc/slabinfo 深度解读:从数据到定位内核以及内存异常问题
目录
slabinfo 是什么?它解决了什么问题
slab 分配器的设计回顾(为什么有 slab)
slabinfo 的输出结构详解
slabinfo 你能看出什么?(问题类型归类)
实战:用 slabinfo 定位内核内存增长
常见 slab cache 解释(工程师最常遇到的 20+ 个)
slabinfo + 其他工具:组合定位套路
slabinfo 的局限与误判点
工程排查模板(可复制到你团队)
结语:slabinfo 的价值与正确使用方式
1. slabinfo 是什么?它解决了什么问题
/proc/slabinfo 是内核暴露的一个“内核对象分配统计表”,它记录了所有 slab cache 的当前状态。
它的作用非常明确:
用来观察 内核对象分配 的真实情况,帮助定位内核态内存问题(泄漏、增长、碎片、过度分配等)。
与 top / free 这类面向进程/页框的工具不同,slabinfo 关注的是:
内核对象的数量
内核对象的类型
对象占用的内存
对象的活跃度(active)
所以,slabinfo 是排查 内核内存问题 的“第一手数据”。
2. slab 分配器的设计回顾(为什么有 slab)
理解 slabinfo,先理解 slab allocator 的目的:
2.1 内核内存分配的两个问题
频繁分配/释放导致碎片化
分配开销高(尤其是小对象)
例如:
网络栈会频繁分配 skb
文件系统会频繁分配 inode、dentry
驱动会频繁分配各种描述符结构体
如果每次都走通用分配器(buddy),会:
2.2 slab 的核心思路
对每种对象类型维护一个 cache:
预分配一批对象
对象大小固定
分配/释放时只需要从 cache 中取/还
好处:
分配速度快(只改链表指针)
对象复用减少缓存失效
内存碎片少(对象大小固定)
所以 slab 适合:
3. slabinfo 的输出结构详解
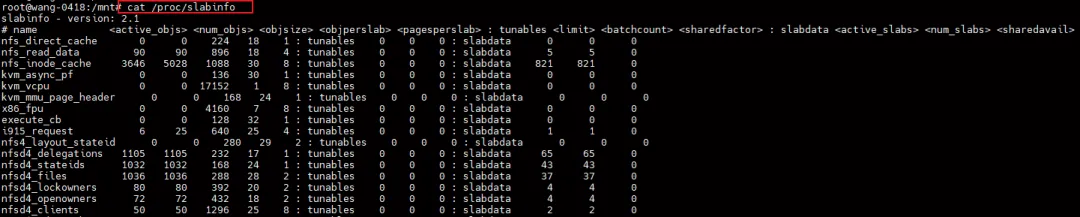
3.1 slabinfo 的典型输出
# name <active_objs><num_objs><objsize><objperslab><pagesperslab><...>kmalloc-32 1024 2048 32 64 1...
常见字段解释:
3.2 你需要重点关注的字段
1)active_objs
正在使用的对象数。它是判断“是否泄漏/增长”的关键。
2)objsize
对象大小。用于计算内存占用。
3)num_objs
分配的总对象数。num_objs - active_objs = 空闲对象数(cache 预分配的“缓存”)
4. slabinfo 你能看出什么?
你可以用 slabinfo 发现以下类型问题:
4.1 内核对象泄漏
表现:
active_objs 持续增长
与系统负载不匹配
甚至系统可用内存不断下降
例子:
dentry active_objs=300000 num_objs=320000
如果 active_objs 在持续增长,而且你没有大量文件操作或 mount/unmount,那么很可能是某个模块没释放 dentry。
4.2 某个 cache 占用内存过大(长期稳定但过大)
表现:
active_objs 很大,但不再增长
说明这个对象确实是系统需要的,但占用过多
例如:
inode_cache active_objs=400000
这可能是:
这种情况不一定是“泄漏”,但会影响内存压力。
4.3 碎片化导致分配失败(CMA/连续内存更明显)
slabinfo 不能直接告诉你碎片化,但你可以结合:
slab cache 增长
但整体内存仍有余量
仍然出现分配失败
这通常意味着:
4.4 频繁分配释放导致性能问题
如果 slab cache 的 active_objs 在快速波动,并且系统 load/irq 上升,说明某模块在疯狂申请释放对象。
比如:
netdev 每个包分配 skb
驱动每个中断分配结构体
这类问题常见于:
驱动设计不合理(每次都 new 结构体)
逻辑循环中无意义分配
5. 实战:用 slabinfo 定位内核内存增长
下面给出一个工程化的排查流程。
5.1 记录初始状态
cat /proc/slabinfo > /tmp/slab_before.txt
5.2 运行业务一段时间(或复现问题)
比如:
5.3 记录之后状态
cat /proc/slabinfo > /tmp/slab_after.txt
5.4 对比增长最多的 cache
下面是一个简单脚本,用来找增长最多的 cache:
awk 'BEGIN{FS=" "; OFS=" "}NR==FNR{ if($1 ~ /^#/){next} name=$1; active=$2; before[name]=active; next}{ if($1 ~ /^#/){next} name=$1; active=$2; if(name in before){ delta=active-before[name]; if(delta>0){ print delta, name, active; } }}' /tmp/slab_before.txt /tmp/slab_after.txt | sort -nr | head -n 30
输出示例:
12000 dentry 3400008000 inode_cache 180000...
5.5 你拿到结果后应该怎么判断?
1)如果是 dentry / inode 增长
通常意味着:
文件打开过多
mount/unmount 频繁
业务存在大量临时文件或频繁遍历文件系统
此时建议检查:
2)如果是 skb / netdev growth
通常意味着:
网络包处理存在瓶颈
可能出现报文风暴
或驱动中断处理逻辑异常
此时建议检查:
3)如果是 kmalloc-* 系列增长
kmalloc-* 是内核通用小对象分配器。
增长通常意味着:
你需要进一步定位来源(可以用 ftrace 或 kmemleak)。
6. 常见 slab cache 解释(工程师最常遇到的 20+ 个)
下面列出常见 cache 及其含义(工程实践中最常见的那些):
这些名称的变化取决于内核版本、配置、文件系统、网络栈等。
7. slabinfo + 其他工具:组合定位套路
slabinfo 是“第一步”,真正定位到“哪个模块在泄漏”需要组合工具。
7.1 slabinfo + kmemleak(定位泄漏来源)
kmemleak 是内核的内存泄漏检测器。
适用场景:
你确认某个 cache 在持续增长
你需要知道“哪个函数/模块申请但不释放”
步骤:
打开 kmemleak(需要内核开启 CONFIG_DEBUG_KMEMLEAK)
运行业务
查看 /sys/kernel/debug/kmemleak
kmemleak 会给出“泄漏对象的堆栈”,这通常是最直接的定位方式。
7.2 slabinfo + ftrace(定位分配来源)
如果 kmemleak 没有开启或不方便开启,你可以用 ftrace:
追踪 kmalloc
追踪特定 cache 的 alloc/free
例如:
trace-cmd record -e kmalloc -e kfreetrace-cmd report | grep <your-cache-name>
这种方式适合你要“知道是谁在申请”,但它会带来一定的性能开销。
7.3 slabinfo + perf
如果你看到 slab cache 频繁波动导致系统负载高,可以用 perf 观察:
哪个函数在频繁调用 kmalloc
哪个函数在频繁释放
perf 的输出可以帮助你判断“性能瓶颈是否来自内存分配”。
8. slabinfo 的局限与误判点
slabinfo 非常有用,但也有误判点,工程上要注意:
8.1 slabinfo 只看“对象数量”,不是“真实内存占用”
你必须自己计算:
内存占用 ≈ active_objs * objsize
否则你可能误判:
8.2 slab cache 本身会保留空闲对象(预分配机制)
num_objs >= active_objs,这意味着:
cache 可能保留空闲对象作为“缓存”
这不一定是泄漏
你需要看的是 active_objs 的增长趋势。
8.3 有些 cache 增长是正常业务需求
例如:
这不一定是“内存泄漏”,而是业务本身的需求。
9. 工程排查模板(可复制到你团队)
下面是一个可直接作为团队排查流程的模板:
9.1 初步诊断
查看系统总体内存状态
查看 slab 总体占用
cat /proc/slabinfo | awk '{sum += $2*$4} END {print sum}'观察 slab 占用最多的前 20 个 cache
9.2 记录对比(关键步骤)
记录 before
cat /proc/slabinfo > /tmp/slab_before.txt运行业务/复现问题
记录 after
cat /proc/slabinfo > /tmp/slab_after.txt对比增长最多的 cache
# 参考上面提供的 awk 脚本
9.3 进一步定位
如果 cache 是 dentry/inode:检查文件句柄、mount、文件操作
如果 cache 是 skb:检查网络流量、报文风暴、驱动中断
如果 cache 是 kmalloc:使用 ftrace/kmemleak 定位来源
10. 结语:slabinfo 的价值与正确使用方式
slabinfo 不是“看一眼就能知道原因”的工具,但它是:
内核内存问题定位的第一张地图
它告诉你:
哪些对象在增长
哪些 cache 占用最多
内核内存压力来自哪里
而真正的定位需要你结合业务、结合其他工具、结合源码分析。
如果你能把 slabinfo 作为日常排查的第一步,很多“莫名其妙的内存增长”都会变得可追踪、可定位、可修复。