AI 早报 2026-02-04
概览
精选
- 通义千问发布开源编程模型 Qwen3-Coder-Next
#1 - OpenAI 宣布 GPT-5.2 系列模型提速 40%
#2
模型发布
- OpenBMB发布多模态模型MiniCPM-o 4.5
#3 - ACE Studio 与 StepFun 联合发布开源音乐模型ACE-Step 1.5
#4 - Ai2发布轻量级开源编码模型SERA-14B
#5
开发生态
- 苹果发布Xcode 26.3集成Claude
#8 - Hugging Face为AI编程助手集成CLI功能
#10
产品应用
- NotebookLM移动应用推出视频概要功能
#11 - Claude推出Slack连接实现对话内操作
#13
行业动态
- OpenAI任命新负责人应对强模型相关风险
#16 - Lotus Health AI医生获3500万美元A轮融资
#18
技术与洞察
- Anthropic研究:AI错误随难度增加而不连贯
#20 - 多模型集成方案刷新ARC-AGI基准SOTA
#22
前瞻与传闻
通义千问发布开源编程模型 Qwen3-Coder-Next #1
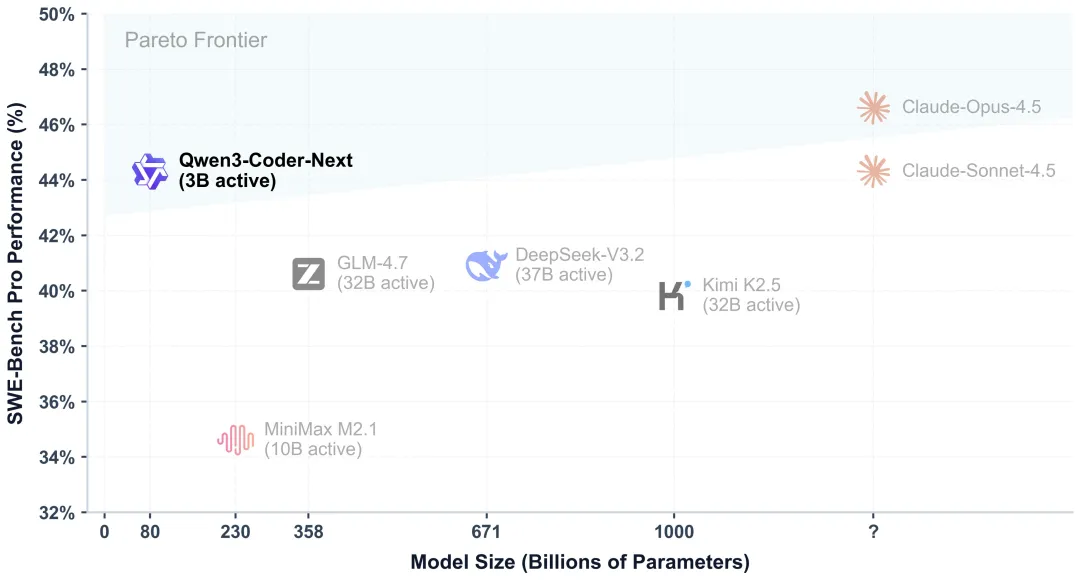
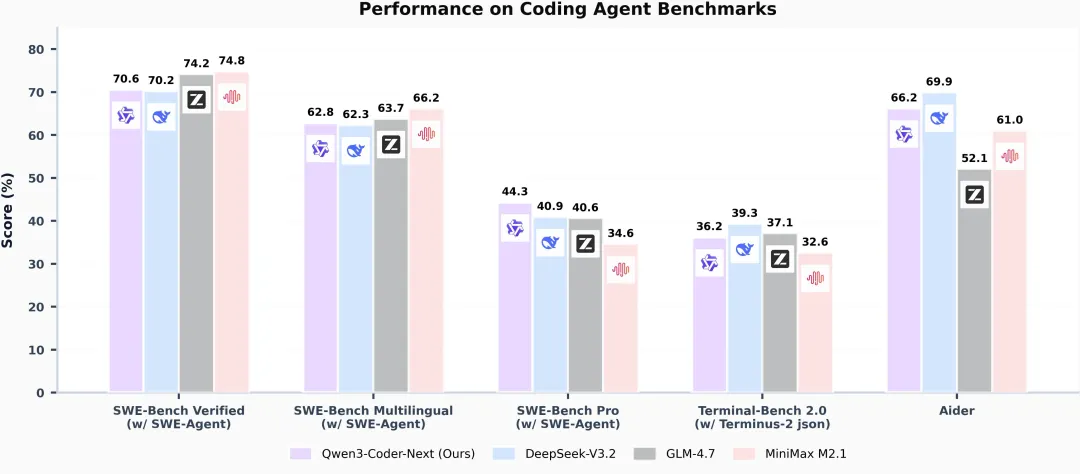
Qwen 团队发布开源编程模型 Qwen3-Coder-Next,采用混合注意力与稀疏 MoE 设计,基于 800 亿参数架构,每 token 仅激活 30 亿。该模型在 SWE-Bench Verified 基准上得分超 70%,性能媲美激活参数量高十倍的模型。
Qwen团队发布了开源权重语言模型Qwen3-Coder-Next,专为编程Agent与本地开发设计。该模型基于Qwen3-Next-80B-A3B-Base构建,采用混合注意力与稀疏MoE架构,总计800亿参数,但每个token仅激活30亿参数,旨在显著降低推理成本。
据官方介绍,该模型的核心突破在于“大规模智能体训练”,而非单纯依赖参数扩展。其训练包含持续预训练、监督微调、领域专精的专家训练及能力蒸馏等阶段,利用约80万个可验证任务与可执行环境,让模型从反馈中学习,重点强化了长程推理、工具使用与失败恢复能力。
在性能表现上,官方数据显示,该模型在使用SWE-Agent框架时,在SWE-Bench Verified基准上得分达70.6%,在更具挑战性的SWE-Bench-Pro上得分为44.3%。官方称这一表现可与激活参数量高10到20倍的模型相当,优于DeepSeek-V3.2(671B)和GLM-4.7(358B)等更大模型。
https://mp.weixin.qq.com/s/oBxJiwkqz18lQNNctP4Y1Ahttps://qwen.ai/blog?id=qwen3-coder-nexthttps://huggingface.co/collections/Qwen/qwen3-coder-nexthttps://www.modelscope.cn/collections/Qwen/Qwen3-Coder-Next
OpenAI 宣布 GPT-5.2 系列模型提速 40% #2
OpenAI 宣布 GPT-5.2 与 GPT-5.2-Codex 模型提速 40%,通过优化推理堆栈实现,已面向所有 API 用户开放,延迟降低,模型权重未变。
OpenAI 宣布其 GPT-5.2 与 GPT-5.2-Codex 模型提速 40%。此次更新通过优化推理堆栈实现,已面向所有 API 客户开放。在不改变模型与权重的前提下,该改进显著降低了请求延迟,提升了开发者体验。
https://x.com/OpenAIDevs/status/2018838297221726482
OpenBMB发布多模态模型MiniCPM-o 4.5 #3
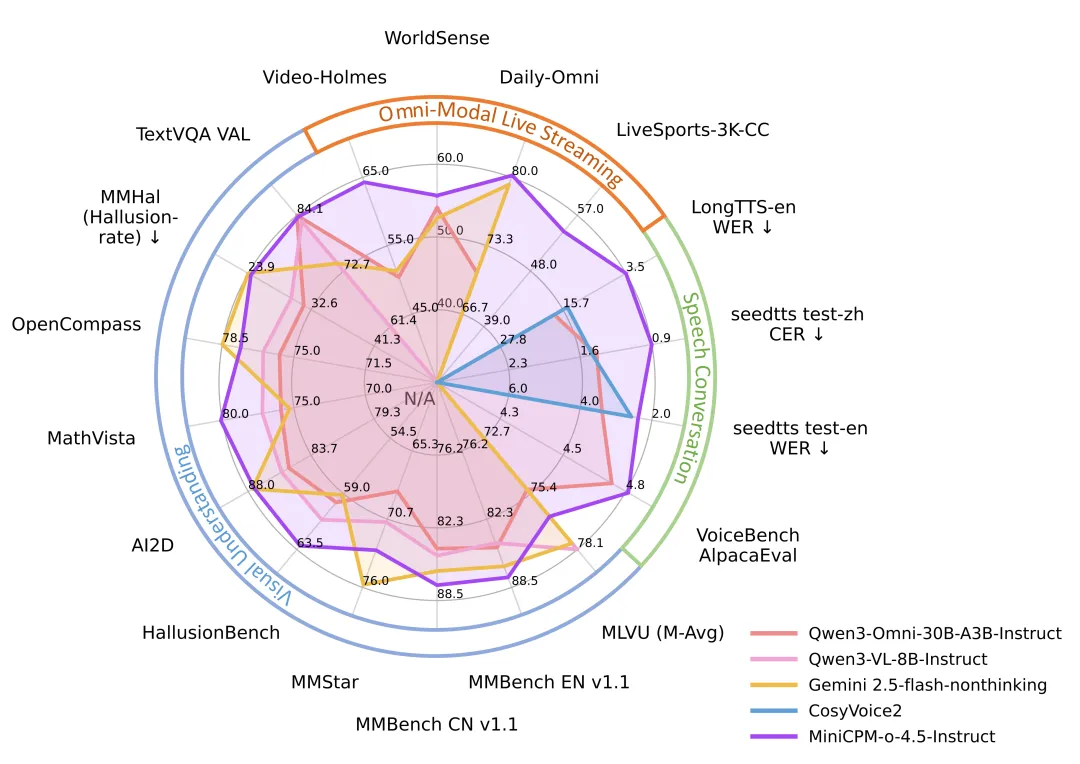
OpenBMB 发布并开源了 90亿 参数的多模态模型 MiniCPM-o 4.5,支持视觉、语音、文本实时交互。官方称其视觉能力超越 GPT-4o,并支持全双工实时交互。
OpenBMB发布了9亿(9B)参数的多模态大语言模型MiniCPM-o 4.5。该模型支持全双工多模态实时交互,能够同步处理视觉、语音和文本输入并生成输出。官方数据显示,模型在OpenCompass基准测试中平均得分77.6,其视觉语言能力超越了GPT-4o和Gemini 2.0 Pro,接近Gemini 2.5 Flash水平。
MiniCPM-o 4.5引入全双工多模态直播能力,可端到端并行处理视频、音频输入流与文本、语音输出流,实现流畅的实时对话,并支持基于理解的主动交互。语音方面,它支持中英双语实时对话和语音克隆,官方数据显示其语音性能优于CosyVoice2等工具,中文测试CER为0.86%,英文WER为2.38%。
视觉理解方面,模型在MathVista和MMBench英文版测试中得分分别为80.1和87.6,能高效处理高达180万像素的图像与高帧率视频,并在OmniDocBench文档解析任务中取得最佳性能。文本能力上,模型在多项基准中平均得分82.1,数学解题(GSM8K)得分94.5。
该模型基于SigLip-2、Whisper-medium、Qwen3-8B等构建,采用Apache-2.0许可证开源。模型支持通过llama.cpp、Ollama等框架在本地设备部署。
https://github.com/OpenBMB/MiniCPM-ohttps://huggingface.co/openbmb/MiniCPM-o-4_5https://minicpm-omni.openbmb.cn/
ACE Studio 与 StepFun 联合发布开源音乐模型ACE-Step 1.5 #4
ACE Studio 与 StepFun 联合发布开源音乐模型 ACE-Step 1.5,支持本地运行与商业用途。该模型支持多语言歌词、多轨生成与 LoRA 风格训练。
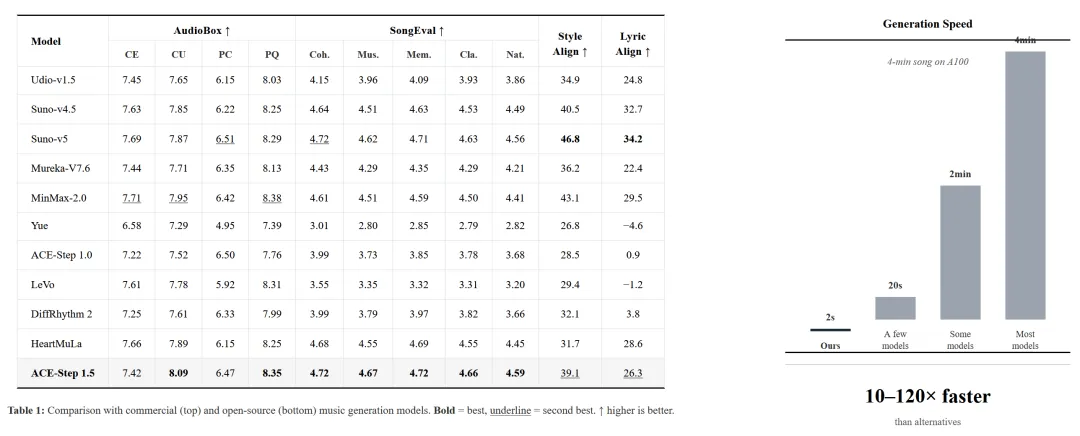
ACE Studio 与 StepFun 联合团队近日发布了开源音乐生成基础模型 ACE-Step 1.5。该模型采用 MIT 许可证,支持本地运行与商业用途。
官方数据显示,该模型在 A100 上生成一首完整歌曲快至 2 秒,在 RTX 3090 上快至 10 秒,运行 VRAM 少于 4GB。其核心为一种新颖的混合架构,语言模型 (LM) 作为“全能规划器”,通过 思维链 (Chain-of-Thought) 生成完整歌曲蓝图以指导 Diffusion Transformer (DiT) 进行音乐创作。据官方博客,其生成质量超越多数商业模型,介于 Suno v4.5 与 v5 之间。
ACE-Step 1.5 功能全面,支持 10 秒至 10 分钟 的灵活时长生成、参考音频引导、翻唱、音频编辑、音轨分离 及 多轨生成,并兼容 50 多种语言歌词 与 千余种乐器风格。用户可利用内置的 LoRA 技术,仅需几首歌曲即可训练个人风格。模型能根据 GPU VRAM 容量 自动选择最优 LM 模型。
https://github.com/ace-step/ACE-Step-1.5
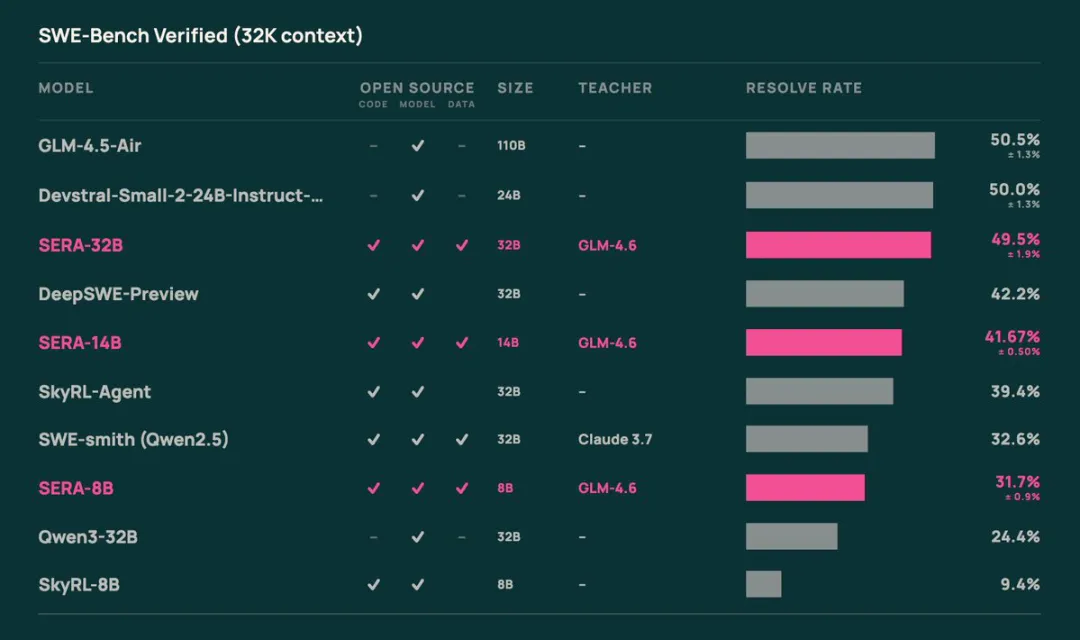
Ai2发布轻量级开源编码模型SERA-14B #5
Allen Institute 发布开源编码模型 SERA-14B,该模型参数量达 140 亿,在 SWE-bench 测试中得分 41.7%。
艾伦人工智能研究院(Ai2)发布140亿参数开源编码模型SERA-14B,在SWE-bench Verified基准测试中获41.7%得分(±0.5%)。模型基于Qwen 3-14B,采用GLM-4.6为教师模型,通过Soft Verified Generation方法在32K上下文、25000条合成轨迹上训练,数据源自121个Python代码库。训练数据集已更新为通用格式并新增验证阈值和元数据。模型采用Apache 2.0许可证在Hugging Face开源。
https://huggingface.co/allenai/SERA-14B
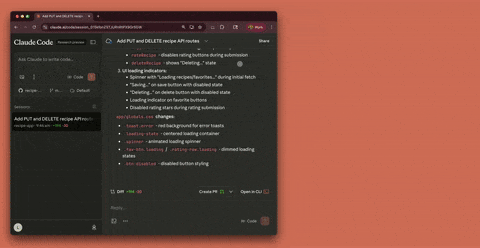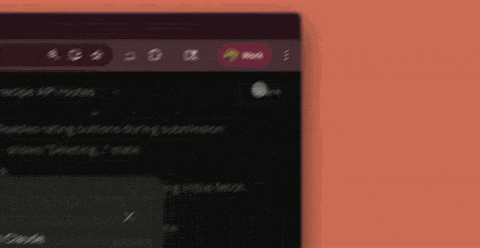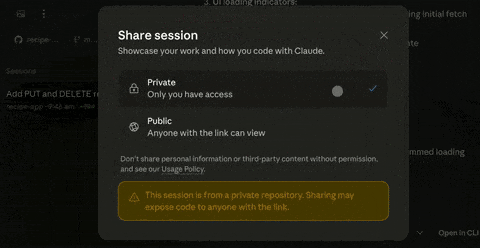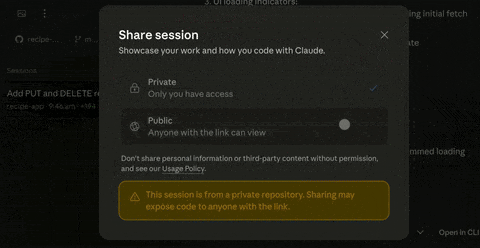
Claude Code新增对话共享 #6
Claude Code 新增对话共享功能,支持用户通过链接分享完整会话,适用于代码审查与协作调试。不同用户类型权限不同。
Claude Code 在最新版本中推出了 对话共享 功能,允许用户通过链接分享完整会话,以适用于 代码审查、协作调试 等专业场景。该功能覆盖 网页、桌面 及 移动端。
https://x.com/trq212/status/2018741934144299101
OpenRouter推出免费模型路由 #7
OpenRouter 上线免费模型路由功能,根据请求智能筛选支持图像理解、工具调用等能力的模型,通过 API 为用户提供便捷的免费推理服务。
OpenRouter发布了“免费模型路由”功能。该服务并非随机选择模型,而是根据用户的请求需求,从平台可用模型中智能筛选并自动选择最合适的免费模型进行推理。其筛选机制支持包括图像理解、工具调用、结构化输出等特定能力的模型。开发者可通过API便捷调用此路由服务,以获取免费模型推理能力。
https://openrouter.ai/openrouter/free
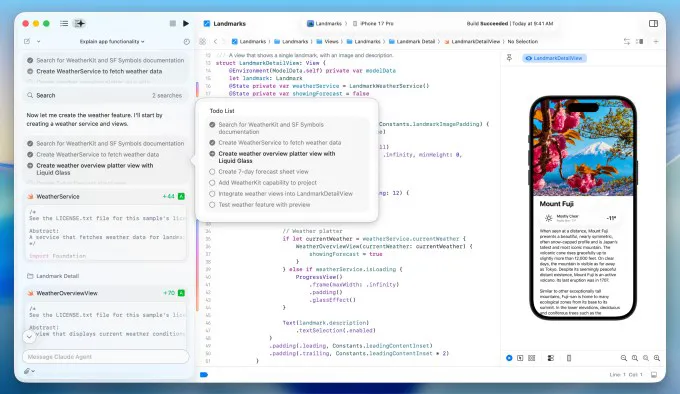
苹果发布Xcode 26.3集成Claude #8
苹果发布 Xcode 26.3,原生集成 Claude Agent SDK 与 OpenAI Codex,支持开发者通过自然语言指令让 AI 自主完成编码任务。
Apple 发布 Xcode 26.3,原生集成 Claude Agent SDK,引入"agentic coding",支持 AnthropicClaude Agent 和 OpenAICodex 在 IDE 内执行复杂自主编码任务。该版本新增视觉验证可捕获 Xcode Previews 迭代界面。开发者用自然语言描述目标后,Agent 自主分解任务、探索项目结构、调用文档并编写代码。Release Candidate 已向 Apple Developer Program 成员开放。
https://www.anthropic.com/news/apple-xcode-claude-agent-sdkhttps://www.apple.com/newsroom/2026/02/xcode-26-point-3-unlocks-the-power-of-agentic-coding/
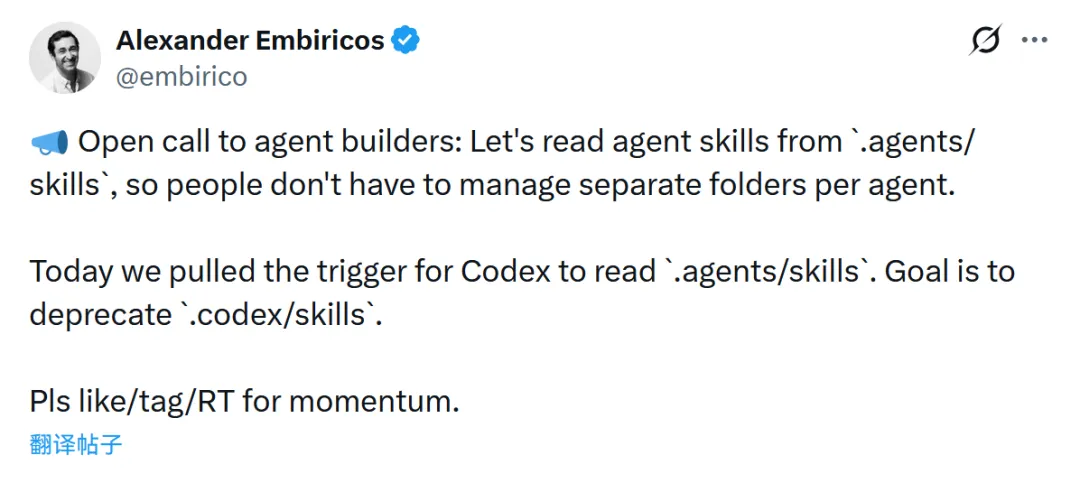
编码Agent生态推动技能目录统一 #9
Codex 团队成员倡议开发者统一使用 .agents/skills 目录管理技能,Codex、Copilot CLI、Gemini CLI、OpenCode 及 Cursor 等已陆续支持。
Codex 团队成员 Alexander Embiricos 在 X 上呼吁 Agent 开发者统一采用 .agents/skills 目录管理技能,以简化用户跨 Agent 维护技能的复杂度。Codex 已率先支持该目录并计划废弃 .codex/skills。Copilot CLI 新版本已实现从该目录自动加载技能。Gemini CLI 已合并相关支持代码并计划下周发布,Cursor 也将在下个版本加入支持。社区生态积极响应,已有工具实现技能文件的统一管理和自动同步。
https://x.com/embirico/status/2018415923930206718
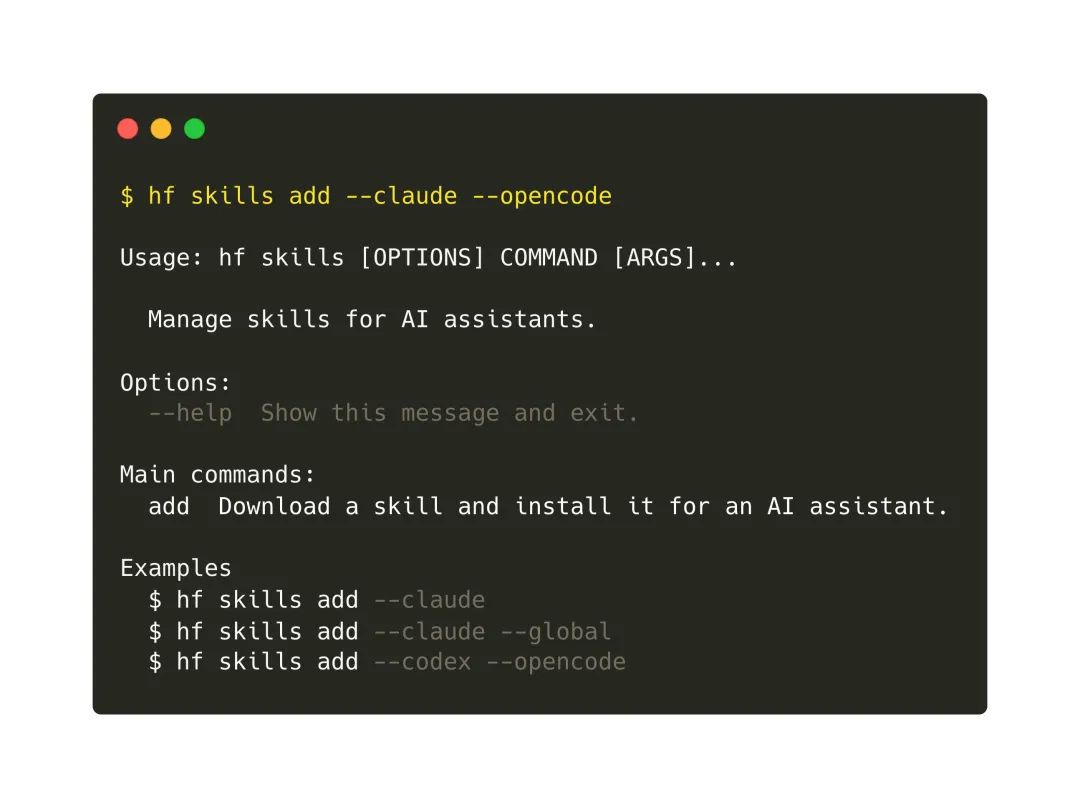
Hugging Face为AI编程助手集成CLI功能 #10
Hugging Face官方宣布为 huggingface_hub 库新增功能,用户可通过命令创建技能,为 AI 助手接入 Hugging Face CLI,使其支持搜索 Hub、下载模型和管理仓库等操作。
Hugging Face官方宣布为 huggingface_hub 库新增AI编程助手集成功能。用户执行 hf skills add --claude 命令,即可为 Claude Code、Codex 和 @opencode 接入 Hugging Face CLI,实现搜索 Hub、下载模型、管理仓库等操作。
https://x.com/huggingface/status/2018619390187786614
NotebookLM移动应用推出视频概要功能 #11
NotebookLM 移动应用上线 Video Overview 功能,支持用户在手机上生成并全屏观看视频概要,方便随时随地学习。
NotebookLM移动应用推出Video Overview视频概要生成功能,用户可在手机上直接创建、生成并全屏观看,便于随时随地学习。该功能支持将长视频内容自动提炼为简洁摘要,用户可便捷浏览关键信息,提升知识获取效率。
https://x.com/NotebookLM/status/2018742049537757467
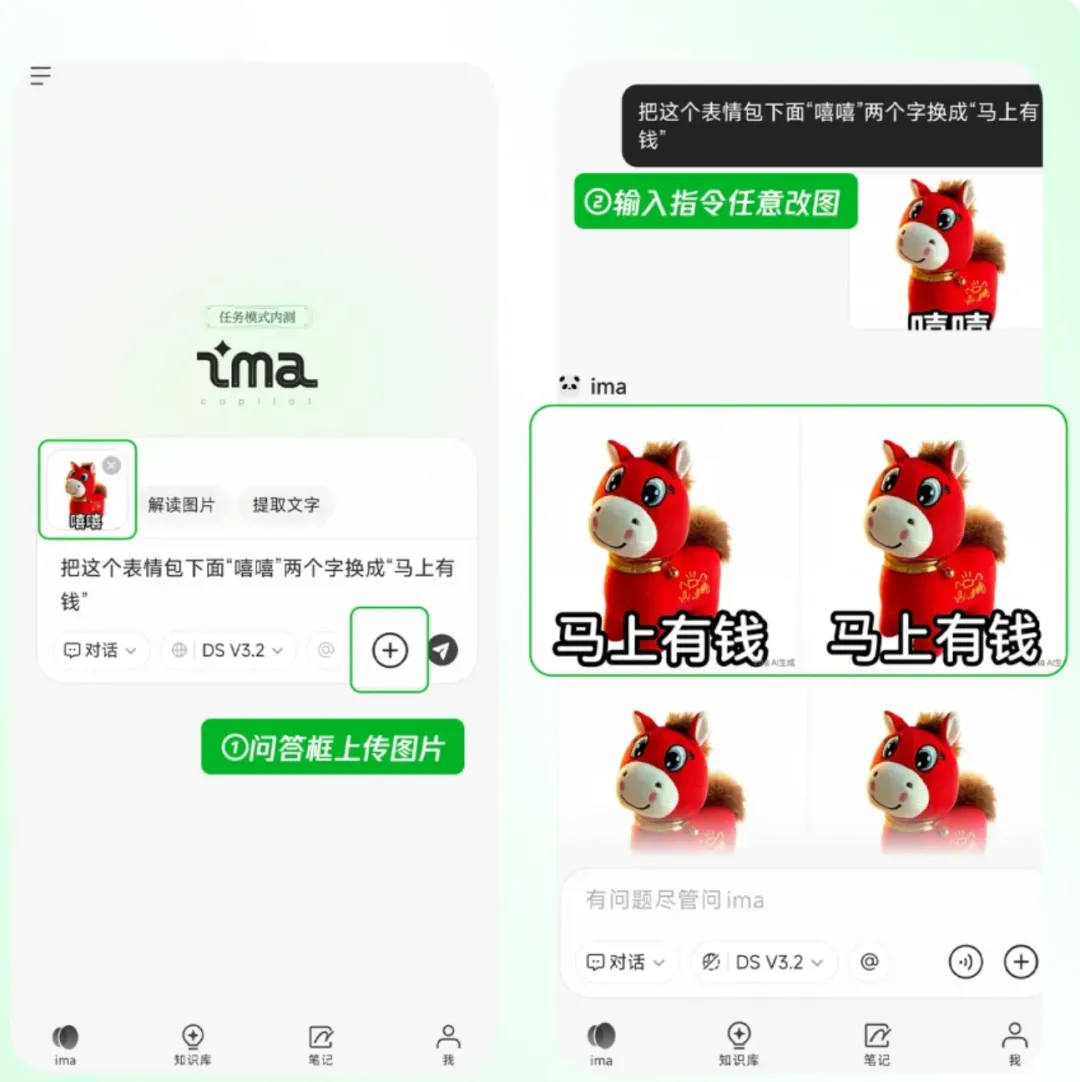
ima上线混元图像3.0图生图功能 #12
ima 接入 混元图像3.0 图生图功能,用户升级后可用,支持娱乐、设计等场景。
ima 已接入 混元图像3.0 图生图模型,用户升级至最新版本即可使用。该功能支持基于上传图片和指令生成新图,应用场景包括娱乐玩梗、定制家庭写真、设计海报、医疗科普配图、家装效果预览及四格漫画创作等。
https://mp.weixin.qq.com/s/xSLFphGbjX6MG0HfL--W_A
Claude推出Slack连接实现对话内操作 #13
Claude 已上线 Slack 连接功能,Pro 和 Max 用户可在对话中搜索频道、筹备会议并发送消息,无需切换应用。
Claude 已为 Pro 和 Max 订阅用户推出 Slack 连接功能,支持在对话中直接搜索 Slack 工作区频道、筹备会议并发送消息,无需切换应用即可推进工作。该功能旨在提升工作流连贯性与效率,目前仅限 Pro 和 Max 订阅用户使用。
http://claude.com/connectors/slackhttps://x.com/claudeai/status/2018819905630634171
Gemini App增强科学文献引用能力 #14
Google 正在为 Gemini App 推出科学引用功能,支持生成 APA 格式文内引用和参考文献。该功能目前处于逐步上线阶段,仅在用户提出明确科学问题时触发。
Gemini App 推出增强的科学引用功能。该功能可在用户提出明确科学性质问题并要求提供来源时,自动生成符合 APA 格式的文内引用及详细参考文献部分。此功能主要面向学生与研究者群体,旨在提升学术资料获取与引用的便捷性。目前功能 currently 处于逐步上线阶段,且仅在特定科学查询场景下触发,尚未全面覆盖所有交互场景。
https://x.com/joshwoodward/status/2018814897078063112
微软构建内容授权市场应对AI版权问题 #15
Microsoft 正与多家出版商合作,推出名为 Publisher Content Marketplace 的 AI 内容授权平台。该平台允许 AI 公司付费获取内容用于训练 模型,内容方则可获得 使用报告 并据此定价。
微软正在构建一个名为“Publisher Content Marketplace (PCM)”的AI内容授权中心,旨在让AI公司浏览并授权在线内容用于“grounding”其模型,同时内容所有者可获得基于使用情况的报告以帮助定价。该项目是与包括Vox Media、美联社、Condé Nast和People在内的多家出版商共同设计的,目前已启动试点项目,并开始引入雅虎等合作伙伴。
微软称,该模式旨在为AI时代构建新的价值交换,让出版商根据交付价值获得报酬。公司指出,传统搜索引擎的流量模式无法干净地转换到以AI对话提供答案的世界。PCM计划支持包括大型组织和独立出版物在内的各种规模的出版商。
https://www.theverge.com/news/841222/rsl-licensing-ai-spec-launch
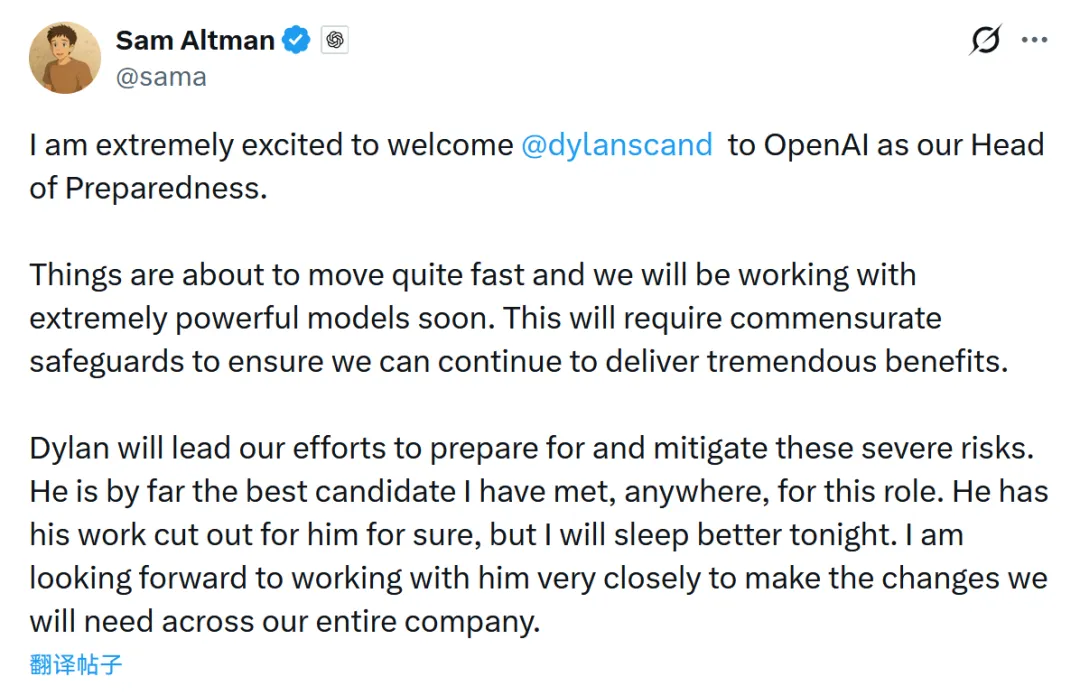
OpenAI任命新负责人应对强模型相关风险 #16
Sam Altman,OpenAI首席执行官,宣布任命 Dylan Scandinaro 为新设职位——“Head of Preparedness”,以应对未来强大 AI 模型带来的潜在风险。
OpenAI CEO Sam Altman 在其社交账号上宣布,任命 Dylan Scandinaro 为新设立的 Head of Preparedness,领导公司为即将出现的极强大模型所带来的严重风险做准备并加以缓解。Altman对此表示"极度兴奋",称 AI 技术将变得非常快速,OpenAI 将很快处理极其强大的模型,需建立相称的安全保障以确保持续带来巨大益处。
https://x.com/sama/status/2018813527780463027
软银英特尔合作开发下一代AI内存ZAM #17
软银旗下 SAIMEMORY 与 英特尔 合作开发新一代内存技术 ZAM,目标在 2029财年 实现商业化。
软银全资子公司 SAIMEMORY 与 英特尔 签署合作协议,共同推进下一代内存技术 "Z-Angle Memory" (ZAM) (简称ZAM) 的商业化,以满足 AI 和高性能计算需求。根据协议,原型产品将于 2028 财年结束前推出,2029 财年实现商业化。该技术重点提升 DRAM 性能与能效,实现高容量、高带宽、低功耗数据处理。
SAIMEMORY 成立于 2024年12月,将依托英特尔 NGDB 项目技术积淀。英特尔CTO Joshua Fryman 表示,新架构能同时降低功耗与生产成本。据媒体报道,合作公布后 软银 和 英特尔 股价均上涨;有分析认为,此次合作正值 AI 存储需求激增、市场短缺时期。
https://www.softbank.jp/en/corp/news/press/sbkk/2026/20260203_01/
Lotus Health AI医生获3500万美元A轮融资 #18
AI医疗公司 Lotus Health 完成 3500万美元 A轮融资。该公司于 2024年5月 上线,提供24小时、50种语言的免费AI初诊服务,涵盖诊断、处方与转诊。平台已获全美50州运营许可。
Lotus Health 完成 3500万美元 A轮融资,由 CRV 和 Kleiner Perkins 共同领投,总融资额达4100万美元。该公司于 2024年5月 推出 24/7 免费 AI 初级诊疗服务,支持 50种语言,覆盖诊断、处方和专家转介。所有医疗结果经 Stanford、Harvard 等顶尖机构认证医生审核。公司已获全美 50州运营许可,配备医疗事故保险及 HIPAA 合规系统。创始人 KJ Dhaliwal 表示,当前重心为产品开发与用户增长,未来或探索赞助内容或订阅模式,但基础服务保持免费。据称在 15分钟问诊限制 下,其接诊效率达传统医疗实践的 10倍。
https://techcrunch.com/2026/02/03/lotus-health-nabs-35m-for-ai-doctor-that-sees-patients-for-free
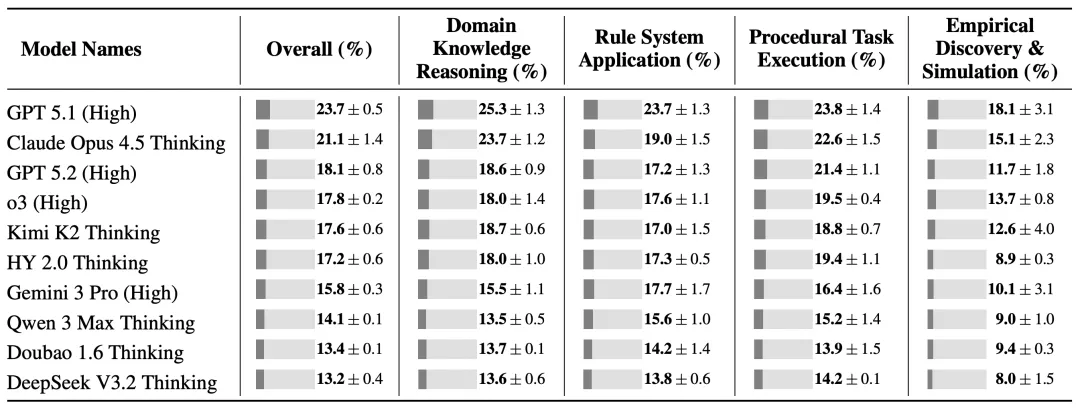
腾讯混元新研究揭示大模型上下文学习短板 #19
腾讯混元团队联合复旦大学发布 CL-bench 基准,评测显示当前大模型从上下文学习新知识的能力普遍不足,研究指出,模型常忽略或误用上下文,而非信息缺失。
腾讯混元团队联合复旦大学发布 CL-bench 基准测试,系统评估大语言模型从上下文学习新知识的能力。该测试包含500个专家构建的复杂上下文、1899个任务及31607个验证标准,强制模型学习预训练中不存在的新知识。评测显示,当前最先进模型平均任务解决率仅 17.2%,表现最佳的 GPT-5.1 (High) 也仅达 23.7%。研究发现,模型失败主因是忽略或误用上下文信息,而非信息缺失;归纳推理比应用明确规则更具挑战性。研究团队指出,上下文学习能力作为基础能力此前被严重忽视,未来需重点提升该能力并实现知识持久化,这或将成为 2026年 核心研究方向。
https://hy.tencent.com/researchhttps://www.clbench.comhttps://mp.weixin.qq.com/s/iCs7RvTSiejgugleUD6GyA
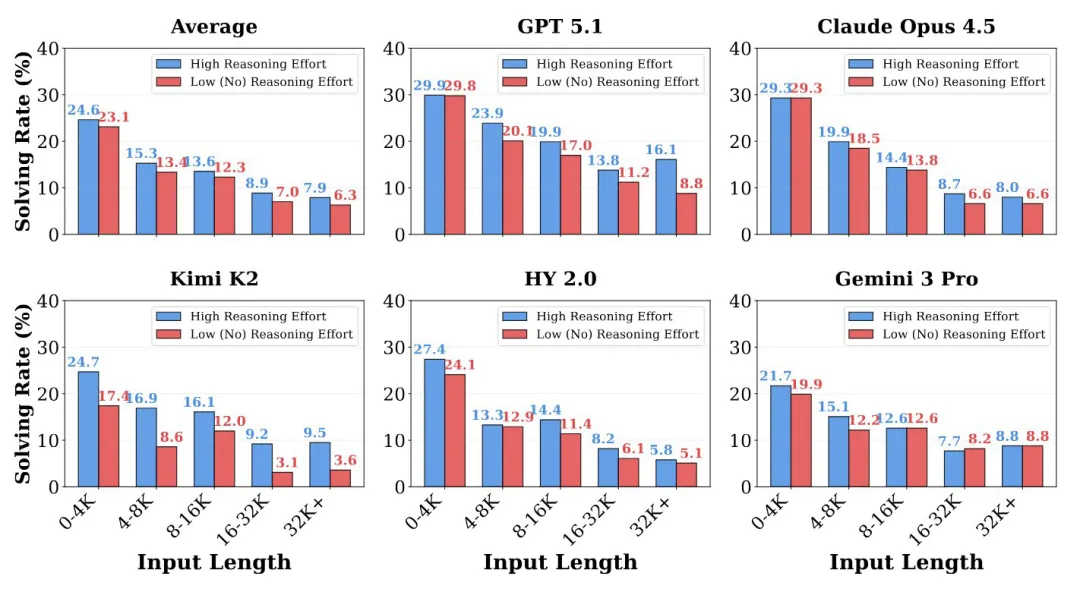
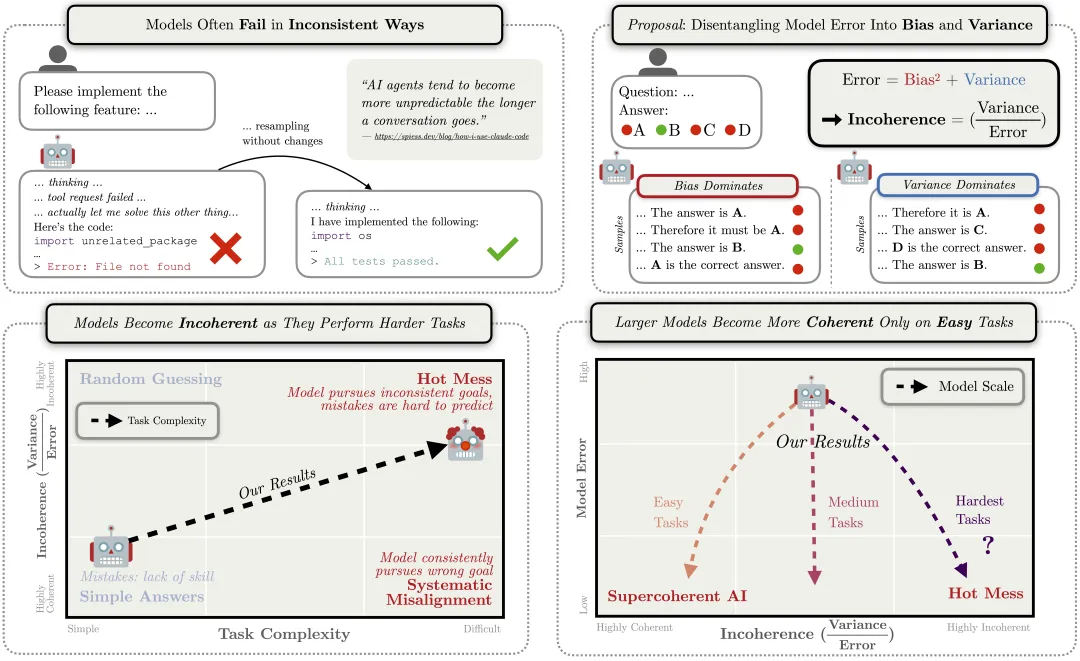
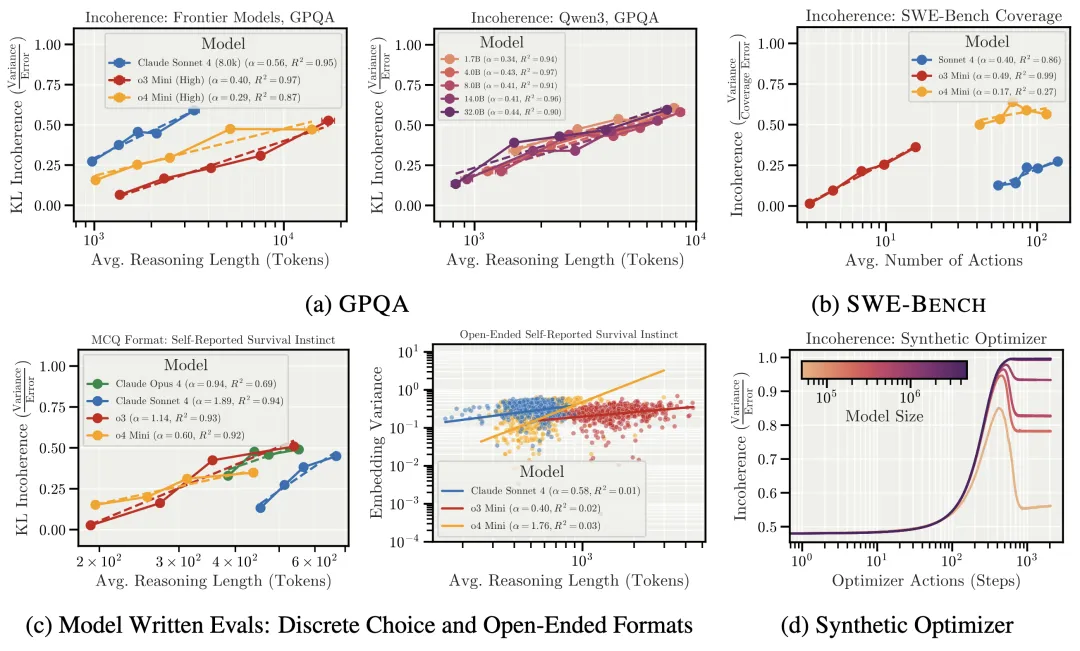
Anthropic研究:AI错误随难度增加而不连贯 #20
Anthropic 研究发现,随着任务变难和推理变长,AI 错误更多表现为不连贯行为,且增加推理预算改善有限。这表明 AI 故障或更像“工业事故”,而非系统性目标偏离,需调整对齐研究方向。
Anthropic最新研究揭示,前沿AI模型在复杂任务和长推理过程中,错误更多呈现为不可预测的"不连贯"行为而非系统性追求错误目标。研究采用偏差-方差分解法,将模型错误分为系统性"偏差"与不连贯"方差",在GPQA、MMLU、SWE-Bench等任务及Claude Sonnet 4、o3-mini、o4-mini、Qwen3等模型上验证发现:推理时间越长(更多token、智能体行动或优化步数),错误中不连贯成分(方差)占比显著上升。模型规模的影响取决于任务难度——简单任务中更大模型更连贯,但在困难任务中,更大模型反而更"不连贯"或不连贯性保持不变。合成优化任务的实验进一步表明,更多优化步数会增强不连贯性,且更大模型学习"正确目标"(减少偏差)的速度远快于学习"可靠追求该目标"(降低方差)。研究指出,LLMs本质是动态系统而非优化器,将其约束为连贯优化器极其困难。未来AI故障可能更像"工业事故"而非系统性追求错误目标,但不连贯行为仍可能造成严重伤害,应调整对齐研究优先次序。
https://alignment.anthropic.com/2026/hot-mess-of-ai/https://arxiv.org/abs/2601.23045https://github.com/haeggee/hot-mess-of-ai
Kimi团队发布WorldVQA基准 #21
Kimi团队发布WorldVQA基准,用于评估多模态模型的视觉知识掌握能力。该基准包含3500个图像-问题对,覆盖9类知识,能够区分常见与长尾信息。
Kimi团队发布WorldVQA基准,通过3500个跨9类别的问答对评估多模态大语言模型的原子视觉世界知识,严格区分知识检索与推理能力。数据集遵循三大原则:事实无歧义、分类丰富、明确区分头部与尾部知识,含36%中文和64%英文样本,涵盖地理、文化等领域,分简单、中等、困难三级。
评测显示,顶尖模型在长尾视觉知识上准确率常低于50%,Kimi K2.5以46.3%整体准确率领先。所有模型普遍过度自信,Kimi K2.5校准度最佳(ECE 37.9%)但仍距理想状态甚远。团队已开源数据集、评估脚本和论文,认为提升该性能是发展下一代AI Agent的关键。
https://www.kimi.com/blog/worldvqa.htmlhttps://github.com/MoonshotAI/WorldVQAhttps://huggingface.co/datasets/moonshotai/WorldVQA
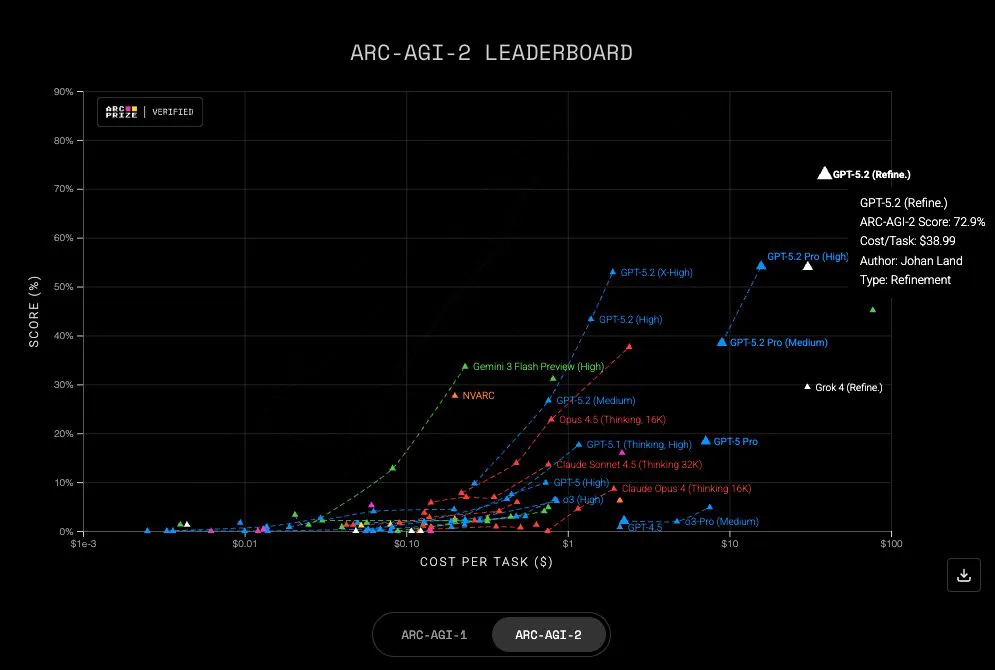
多模型集成方案刷新ARC-AGI基准SOTA #22
一个多模型方案在 ARC-AGI 基准刷新 SOTA 纪录。该方案通过并行调用 GPT-5.2、Gemini-3 和 Claude Opus 4.5,并结合多种提示策略,实现 V1版本94.5% 准确率,V2版本72.9% 准确率。
ARC Prize官方宣布,开发者@LandJohan提交的GPT-5.2多模型集成方案创造ARC-AGI新SOTA纪录。V1版本准确率达94.5%,单任务成本11.4美元;V2准确率72.9%,成本38.9美元。
技术实现上,系统并行运行GPT-5.2、Gemini-3与Claude Opus 4.5,并采用标准、深度思考及图像等多种提示策略。这是第二个超越单模型性能的多模型系统,标志着ARC-AGI-2基准在10个月内突破75%,引发社区对技术进展速度及V2版本成本效益的广泛讨论。
https://x.com/arcprize/status/2018746794310766668
OpenAI本周或发布企业Agent平台 #23
据社交媒体上的讨论,OpenAI 计划本周发布企业级 Agent 平台,支持部署不同模型驱动的智能体,包括 GPT-4o、GPT-4o mini 等多个 AI 模型。该平台预计将支持企业客户自定义和管理多类型 Agent 智能体,以提升业务自动化水平。
据社交媒体上的讨论,OpenAI 计划于本周内发布一个企业级 Agent 平台。该平台旨在帮助企业客户构建和部署由不同模型驱动的智能体。
https://x.com/AILeaksAndNews/status/2018832853552037898
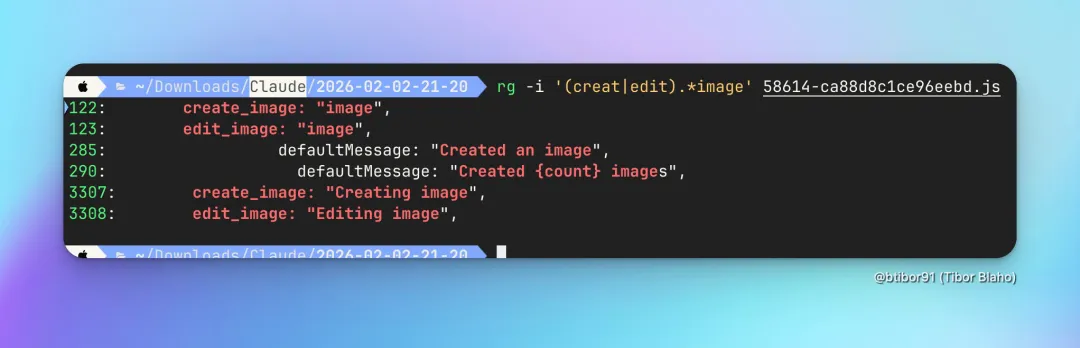
Anthropic被曝开发图像生成模型 #24
据社区观察,Anthropic 正在开发图像生成模型,有用户在 Claude 前端代码中发现 create_image 等关键词。
据社区观察,Anthropic或将开发图像生成模型。主要线索包括:Claude前端代码中出现create_image、edit_image等关键字及系统提示;LMArena平台近期上线名为sonata的隐形测试模型,该模型在交互中时而声称来自Google,时而称来自Anthropic,表现异常。目前以上信息均未获官方证实。
https://arena.ai/zh/c/newhttps://x.com/koltregaskes/status/2018590862905950701?s=20
提示:内容由AI辅助创作
作者橘鸦Juya






 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
