Qwen 编程大模型全家桶来了,部分基准测试达到 Claude Sonnet 的水平,量化版消费级轻松跑!
- 2026-07-04 19:03:56

大家好,我是 Ai 学习的老章
关于 Qwen 编程模型,我之前写过:
Qwn3 发了一个「微不足道」的小更新,碾压 Kimi K2、DeepSeek V3 Qwen 更强大了,Qwen3-Code 编程大模型,额外情报 阿里 Qwen3 全部情报汇总,本地部署指南,性能全面超越 DeepSeek R1
今天阿里又放大招了,Qwen3-Coder 全家桶来了!这次的主角是 Qwen3-Coder-Next,一个专门为 Agent 编程和本地开发设计的开源大模型。
简介
说白了,Qwen3-Coder-Next 就是阿里想让咱们普通人也能玩 Agent 编程。
以前那些 Agent 模型要么太大跑不动,要么性能拉胯。Qwen3-Coder-Next 不一样,它基于一个叫 Qwen3-Next-80B-A3B-Base 的底座,采用了混合注意力 + MoE 的新架构。虽然总参数有 80B,但实际激活参数只有 3B(A3B),推理成本大幅降低。
它是怎么训练出来的呢?阿里用了大规模可执行任务合成、环境交互和强化学习,专门针对 Agent 场景进行优化。效果嘛,官方说能打 Claude Sonnet 的水平。
下图是 SWE-bench Pro 的性能对比:
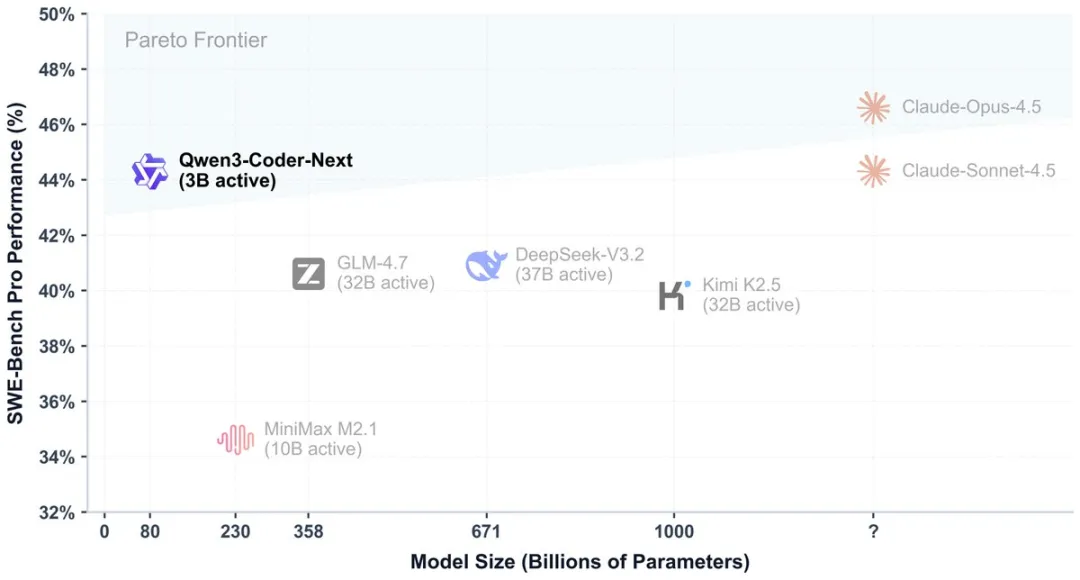
核心功能与亮点:
💻 性价比超高:在 Agent 编程、Browser-Use 和基础编程任务上,能达到 Claude Sonnet 的水平,推理成本却低得多 🛠️ 兼容主流平台:支持 Qwen Code、CLINE、Claude Code 等主流 AI 编程工具,专门设计了 Function Call 格式 📚 超长上下文:原生支持 256K tokens,用 Yarn 技术还能扩展到 1M tokens,整个代码仓库塞进去都没问题 🌐 支持 358 种编程语言:从 Python、JavaScript 到 Rust、Go,甚至 COBOL、Fortran 这种老古董都能写 🔧 Fill-in-the-Middle:支持代码中间补全,写代码时能自动补上缺失的部分
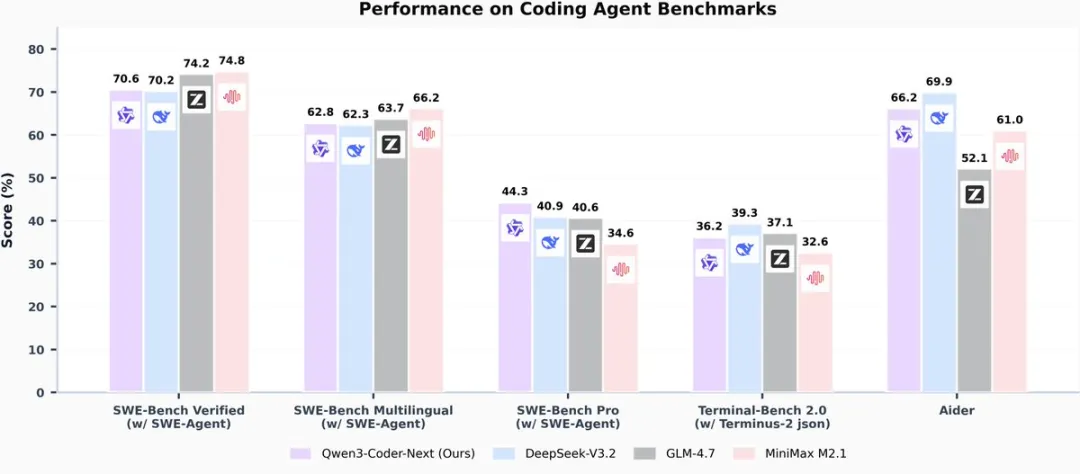
模型全家桶
Qwen3-Coder 一共发了好几个版本:
| Qwen3-Coder-Next | ||
480B 那个太大了,一般人玩不起。30B 的中规中矩。Qwen3-Coder-Next 是性价比之王,激活参数只有 3B,一张好点的消费级显卡就能跑。
安装与使用
Hugging Face 下载:
# 安装 transformers
pip install transformers
# 也可以用 huggingface-cli download
huggingface-cli download Qwen/Qwen3-Coder-Next
ModelScope 下载:
国内用户走 ModelScope 更快:
modelscope download Qwen/Qwen3-Coder-Next
Python 快速上手:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-Next"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "write a quick sort algorithm."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=65536
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
vLLM / SGLang 部署:
官方说 Function Calling 需要用他们新的 tool parser,在 SGLang 和 vLLM 里都支持。这点要注意,如果你要用 Agent 功能,得用新的 tokenizer。
vLLM
pip install 'vllm>=0.15.0'

SGLang
玩法演示
官方给了几个很骚的演示,让我看看这货到底能干啥:
1. 一句话部署网站
Prompt: 下周我们要发布新的编程模型,帮我收集 Qwen Coder 的历史,写个网页,然后用 nginx 发布
它真的能自己搜索资料、写网页代码、配置 nginx、部署上线,全程自动化。
2. 整理桌面
Prompt: Please tidy up my desk.
它能分析桌面文件,自动分类整理。这波操作,直接把 AI 助手的上限拉高了。
3. 做游戏
Prompt: 一大段《僵尸大战植物》的需求描述...
它能直接写出一个完整的网页游戏,包括游戏逻辑、动画、UI、交互,一句话都不用改。
和 Claude Sonnet 比较
官方说性能能打 Claude Sonnet,但我觉得还是要理性看待:
优势:
开源开权重,可以本地部署 推理成本低得多(激活参数 3B vs Claude 的闭源大模型) 中文支持应该更好 支持的编程语言更多(358 种)
劣势:
Agent 能力到底如何还需要实测 刚发布,生态还不如 Claude 成熟 没有官方 API 服务(得自己部署或者用第三方)
本地部署建议
如果你想本地跑 Qwen3-Coder-Next:
显存要求:虽然激活参数只有 3B,但总参数是 80B,FP16 需要 160GB+ 显存。建议用 FP8 量化版或 GGUF 版本 推荐配置: GGUF 格式:单张 24G 显卡(如 4090)可以跑 Q4 量化 FP8 格式:2-4 张 A100/H100 推理引擎:SGLang 或 vLLM,记得用官方的新 tool parser
量化版本与实测速度
好消息!Unsloth 团队已经做好了各种量化版本,让普通人也能跑起来。
不同量化精度的模型大小:
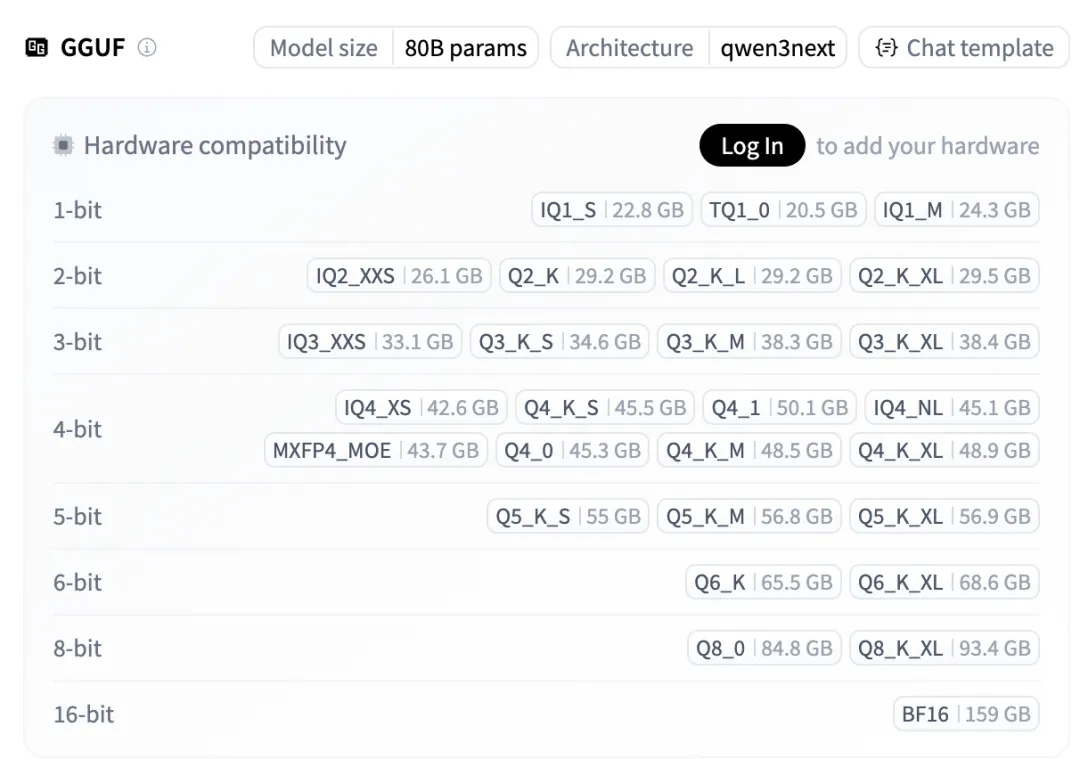
从上图可以看到,最低 22.8GB 就能跑起来!具体来说:
Unsloth 推荐的生成参数:
Temperature = 1.0 Top_P = 0.95 Top_K = 40 Min_P = 0.01(llama.cpp 默认是 0.05)
网友实测速度(来自 X/Twitter):
🔥 LM Studio 4-bit 量化:46.34 t/s(tokens/秒)
🔥 M4 Max 芯片:Qwen3-Coder-Next 跑到 50 t/s,使用 42.77GB 统一内存
这速度相当炸裂了!在 Mac 上跑到 50 tokens/秒,基本能做到实时编程对话。
llama.cpp 部署示例:
# 下载模型
huggingface-cli download unsloth/Qwen3-Coder-Next-GGUF
# 运行(4-bit 量化)
./llama.cpp/llama-cli \
-m Qwen3-Coder-Next-UD-Q4_K_XL.gguf \
--ctx-size 32768 \
--temp 1.0 --top-p 0.95 --top-k 40 \
-cnv
如果你的 RAM/VRAM 够大,上下文可以开到 262,144(256K)。用 --fit on 参数可以自动检测最佳上下文长度。
总结
Qwen3-Coder-Next 是目前开源里最强的 Agent 编程模型之一。如果你在做 AI 编程、代码助手、自动化脚本这类项目,这个模型非常值得一试。
优点是性价比高、开源可控、中文友好;缺点是刚发布,稳定性和生态还需要时间验证。
我个人会在接下来几天做个详细实测,敬请期待。
相关链接:
🤗 Hugging Face: https://huggingface.co/Qwen/Qwen3-Coder-Next 📦 ModelScope: https://modelscope.cn/models/Qwen/Qwen3-Coder-Next 📄 技术报告:https://github.com/QwenLM/Qwen3-Coder/blob/main/qwen3_coder_next_tech_report.pdf 💬 Discord: https://discord.gg/CV4E9rpNSD
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!


