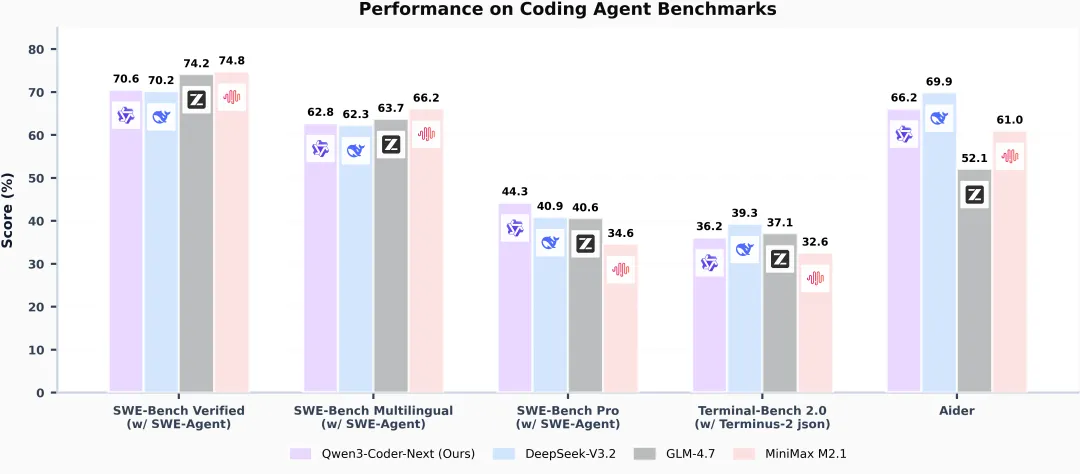
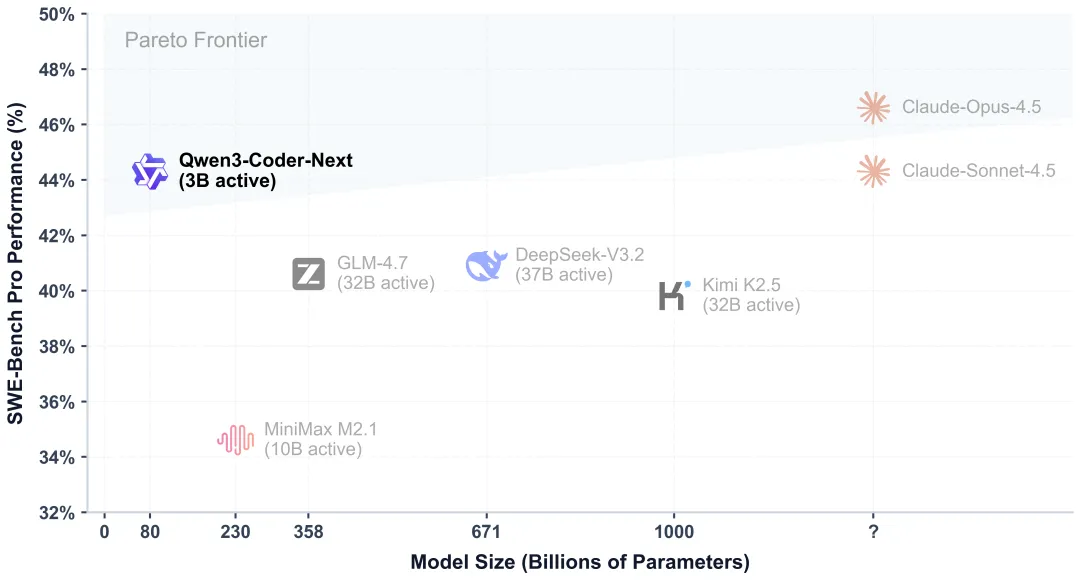
Qwen3-Coder-Next的特性包括:- • 混合布局:12 * (3 * (Gated DeltaNet -> MoE) -> 1 * (Gated Attention -> MoE))
注意:此模型仅支持非思考模式,不会在输出中生成<think></think>块。同时,不再需要指定enable_thinking=False。
Qwen3-Next (80B) 量化部署配置指南
根据 GGUF 文件的显存占用数据,部署这款 80B 参数量 的模型对显存(VRAM)或系统内存(RAM,如果仅用 CPU 推理)有极高的要求。
以下是针对不同量化精度的硬件配置推荐:
1. 极限压缩版 (1-bit ~ 2-bit)
适用场景:体验模型、测试流程、极端受限的硬件环境。精度损失严重。
| | | |
|---|
| 1-bit (TQ1_0 / IQ1_S) | | 单张 RTX 3090/4090 (24GB) | 勉强能跑,给上下文留的余量极少 (KV Cache 空间不足)。 |
| 2-bit (IQ2_XXS ~ Q2_K) | | 单张专业卡 (32GB/48GB) | 超过了单张消费级显卡的 24GB 上限,必须使用 CPU 卸载或多卡。 |
2. 低精度版 (3-bit)
适用场景:在硬件有限的情况下追求比 2-bit 更好的连贯性。
| | | |
|---|
| 3-bit (IQ3_XXS ~ Q3_K) | | 双张 RTX 3090/4090 (48GB) | 双卡 24GB 是最经济的方案,显存充裕,可跑较长上下文。 |
| | 单张 A6000 / A40 (48GB) | |
3. 均衡推荐版 (4-bit) 🔥
适用场景:主流选择。在速度、显存占用和模型智能程度之间取得最佳平衡。
| | | |
|---|
| 4-bit (IQ4_XS) | | 双张 RTX 3090/4090 (48GB) | 剩余约 5GB 显存用于上下文,适合中短文本对话。 |
| 4-bit (Q4_K_M / Q4_0) | | 双张 RTX 3090/4090 (极其勉强)
单张 A100/H100 (80GB) | 48GB 显存组合跑 Q4_K_M 会非常吃紧,很容易 OOM (显存溢出),建议退回到 IQ4_XS 或使用 80GB 显卡。 |
4. 高精度版 (5-bit ~ 6-bit)
适用场景:对逻辑推理能力要求较高,且硬件预算充足。
| | | |
|---|
| 5-bit (Q5_K_S) | | 单张 A100/H100 (80GB) | 80GB 显卡可以轻松运行,且有大量空间留给长上下文。 |
| 6-bit (Q6_K) | | 双张 A6000 (96GB) | |
5. 满血/近无损版 (8-bit ~ FP16)
适用场景:学术研究、微调、追求极致效果。
| | | |
|---|
| 8-bit (Q8_0) | | 双张 A100/H100 (160GB) | |
| BF16 (原版) | | 4张 A6000 (192GB) | |
💡 关键提示 (KV Cache 上下文开销)
图片中显示的仅仅是模型权重的静态显存占用。在实际运行时,上下文越长,额外占用的显存越多。
- • 对于 80B 模型:建议在上述基础数值上,预留 4GB ~ 8GB 的额外显存以支持正常的对话长度(如 4k-8k token)。
快速开始
建议使用最新版本的transformers。
以下是一个代码示例,展示如何根据给定输入使用模型生成内容。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-Next"
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# 准备模型输入
prompt = "编写一个快速排序算法。"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 进行文本生成
generated_ids = model.generate(
**model_inputs,
max_new_tokens=65536
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
注意:如果遇到内存不足(OOM)问题,请考虑将上下文长度减少到较短的值,例如32,768。
服务部署
可以使用最新的sglang或vllm创建一个与OpenAI兼容的API端点。
SGLang
SGLang是一个快速的服务框架,用于大型语言模型和视觉语言模型。
SGLang可以用于启动一个具有OpenAI兼容API服务的服务器。
sglang>=v0.5.8是Qwen3-Coder-Next所需的版本,可以通过以下命令安装:
pip install 'sglang[all]>=v0.5.8'
以下命令可用于在http://localhost:30000/v1创建一个API端点,最大上下文长度为256K tokens,使用4个GPU进行张量并行。
python -m sglang.launch_server --model Qwen/Qwen3-Coder-Next --port 30000 --tp-size 2 --tool-call-parser qwen3_coder
vLLM
[vLLM]是一个高吞吐量和内存高效的推理和服务引擎。
vLLM可以用于启动一个具有OpenAI兼容API服务的服务器。
vllm>=0.15.0是Qwen3-Coder-Next所需的版本,可以通过以下命令安装:
pip install 'vllm>=0.15.0'
有关更多详细信息,请参阅其文档。
以下命令可用于在http://localhost:8000/v1创建一个API端点,最大上下文长度为256K tokens,使用4个GPU进行张量并行。
vllm serve Qwen/Qwen3-Coder-Next --port 8000 --tensor-parallel-size 2 --enable-auto-tool-choice --tool-call-parser qwen3_coder
代理编码
Qwen3-Coder-Next在工具调用能力上表现出色。
您可以简单地定义或使用任何工具,如以下示例。
# 您的工具实现
def square_the_number(num: float) -> dict:
return num ** 2
# 定义工具
tools=[
{
"type":"function",
"function":{
"name": "square_the_number",
"description": "输出数字的平方。",
"parameters": {
"type": "object",
"required": ["input_num"],
"properties": {
'input_num': {
'type': 'number',
'description': 'input_num是将被平方的数字'
}
},
}
}
}
]
from openai import OpenAI
# 定义LLM
client = OpenAI(
# 使用与OpenAI API兼容的自定义端点
base_url='http://localhost:8000/v1', # api_base
api_key="EMPTY"
)
messages = [{'role': 'user', 'content': '将数字1024平方'}]
completion = client.chat.completions.create(
messages=messages,
model="Qwen3-Coder-Next",
max_tokens=65536,
tools=tools,
)
print(completion.choices[0])
最佳实践
为了获得最佳性能,千问推荐以下采样参数:temperature=1.0,top_p=0.95,top_k=40。
更多详情
包括基准评估、硬件要求和推理性能,请参阅千问的
[博客] https://qwen.ai/blog?id=qwen3-coder-next
[GitHub] https://github.com/QwenLM/Qwen3-Coder
[文档] https://qwen.readthedocs.io/en/latest/。
Qwen3-Coder-Next模型在代码生成和自然语言处理领域展现了强大的能力,为开发者和研究人员提供了新的工具和思路。无论您是想在项目中应用此模型,还是对其技术细节感兴趣,我们都欢迎您在评论区分享您的看法和经验。您认为这种技术在未来会有哪些创新的应用场景呢?请随时与我们交流您的想法,并将这篇文章分享给更多对AI技术感兴趣的朋友,让我们一起探索更多可能性!
更多内容 欢迎关注~
模型链接: https://huggingface.co/Qwen/Qwen3-Coder-Next