昨天 Anthropic 发了 Claude Opus 4.6。1M token context、自我纠错提升这些大家都在聊。但我觉得最值得单独拿出来说的是一个还在实验阶段的功能:Agent Teams。
不是因为它最成熟,而是因为它指向的方向很明确——让多个 AI 像团队一样协作。
先说它干了什么
Anthropic 自己拿 Agent Teams 做了一个 demo:16个 Claude agent 并行工作,用 Rust 写了一个 C 编译器。
具体数据:2周时间,大约2000个 Claude Code session,花了2万美金 API 费用,产出10万行代码。这个编译器能编译 Linux 6.9 内核(x86、ARM、RISC-V 三个架构),GCC 测试套件通过率99%。还能编译 QEMU、FFmpeg、SQLite、PostgreSQL、Redis,跑 Doom 也没问题。
16个 agent 不是各写各的然后拼起来。它们通过一个 lock 机制协调——每个 agent 想干一个任务,先写一个文件到 current_tasks/ 目录里"占坑",git 同步保证不会两个 agent 抢同一个任务。每个 agent 跑在独立的 Docker 容器里,循环执行:拉代码 → 领任务 → 写代码 → 合并其他 agent 的改动 → 推代码。
Anthropic 自己总结的经验里有一条很实在:验证机制必须接近完美,不然 agent 会"正确地解决错误的问题"。也就是说,如果你的测试告诉 agent 错误的方向,它会非常认真地朝那个错误方向一路狂奔。
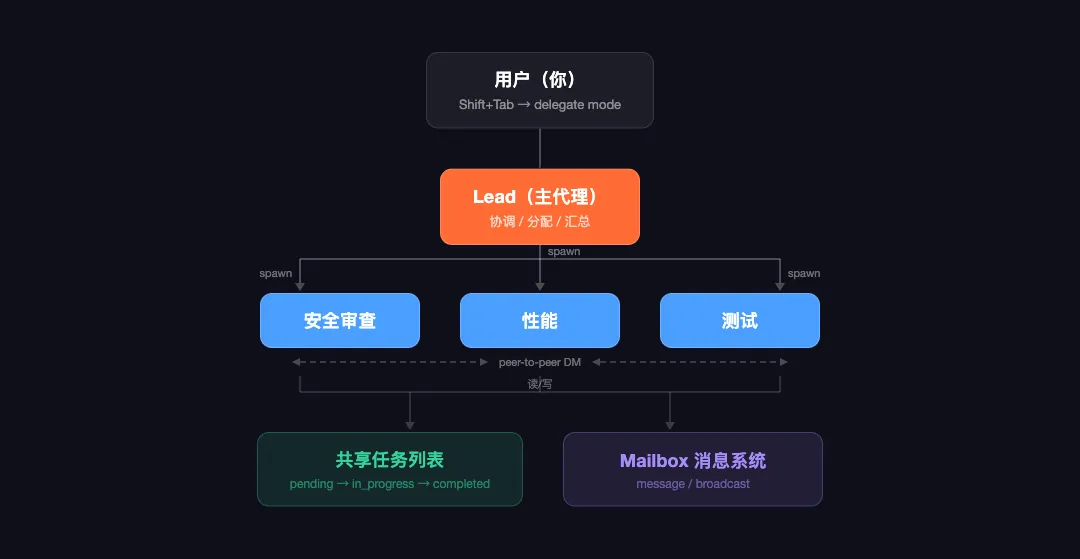
Agent Teams 的架构
技术上,Agent Teams 由四个部分组成:
Lead(主代理):你当前的 Claude Code session。负责创建团队、分配任务、协调工作。可以按 Shift+Tab 进入 delegate mode——只协调不干活,防止 lead 自己忍不住开始写代码。
Teammates(队友):每个队友是一个完全独立的 Claude Code 实例,有自己的 context window。不是子进程,不是线程,是独立的 session。
Task List(共享任务列表):存在 ~/.claude/tasks/{team-name}/ 里,任务有 pending / in_progress / completed 三个状态,支持依赖关系。用文件锁防止两个队友抢同一个任务。
Mailbox(消息系统):队友之间可以直接发消息。两种方式——message(一对一)和 broadcast(群发所有人)。这是跟子代理最大的区别。
跟"并行子代理"有什么不同
这里要澄清一下。Claude Code 里其实有三层"多 agent"能力:
第一层:Task tool(子代理)。 内置功能,随时可用。你可以同时派出多个子代理去做独立的任务,结果汇报给主代理。但子代理之间不能通信——A 不知道 B 在干什么。适合"去查个东西回来告诉我"这种场景。
第二层:自定义子代理。 在 .claude/agents/ 里用 Markdown 定义,可以指定系统提示、工具权限、模型。比 Task tool 更可控,但本质还是"派出去干活回来汇报",没有互相通信。
第三层:Agent Teams。 队友之间能直接对话,有共享任务列表,有 plan approval 流程(队友提交方案,lead 审批后才执行)。不是"我派你去干活",而是"我们一起干活"。
我之前写小红书帖子时用的3个并行 agent,其实是第一层的 Task tool。三个子代理各自搜资料、写初稿,30秒内全部返回。这个功能已经很好用了,但它们之间无法沟通——如果 agent A 搜到的信息对 agent B 有用,没办法实时传递。
Agent Teams 解决的就是这个问题。
怎么用
Agent Teams 目前默认关闭,需要手动开启:
export CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1
然后用自然语言描述你想要的团队结构就行:
创建一个团队来 review 这个 PR。三个 reviewer:一个看安全,一个看性能,一个看测试覆盖。
显示模式有两种:in-process(都在一个终端里,Shift+上下键切换队友)和 split panes(tmux/iTerm2 分屏),默认自动选择。
队友的权限继承 lead——如果 lead 跳过了权限检查,所有队友也会跳过。spawn 之后可以单独调整。
局限性
直说几个问题:
文件冲突。 两个队友同时改同一个文件,后面的会覆盖前面的。所以必须提前规划好每个队友负责哪些文件,不能有重叠。
session 不能恢复。 用 /resume 恢复对话后,之前的队友不会回来。lead 可能会尝试给已经不存在的队友发消息。
一次只能一个团队。 必须把当前团队关掉才能开新的。
token 消耗大。 每个队友是独立的 Claude 实例,各自有 context window。5个队友大概就是5倍的 token 费用。C 编译器那个 demo 花了2万美金——当然那是16个 agent 跑两周的极端情况。
任务状态有时会卡。 队友偶尔忘记把任务标记为完成,导致依赖它的任务一直阻塞。需要人工干预。
实测体验:用 Agent Teams 写这篇文章
为了不光讲理论,我直接用 Agent Teams 来完成这篇文章的终稿。也就是说,你正在读的这篇文章,本身就是 Agent Teams 的产出。
我怎么搭的这个团队
我跟 Claude Code 说想用 Agent Teams 来完成这篇文章。它创建了一个叫 article-agent-teams 的团队,把工作拆成 5 个任务、设好依赖关系,然后 spawn 了 5 个 agent:
- fact-checker:核查文章里所有技术数据,"16个agent""2万美金""99%通过率"这些数字对不对- source-collector:搜集原始资料和可引用的链接- image-planner:规划配图方案- experience-writer:写这个"实测体验"章节- editor:等前面四个都完成后,整合润色出终稿
整个过程大概 2 分钟把团队搭好,不用写代码,不用配 YAML,自然语言描述完就行。
底层长什么样
搭完团队后去看了一眼底层文件。团队配置存在 ~/.claude/teams/article-agent-teams/config.json 里,记录了每个成员的名字、角色、模型(都是 Opus 4.6)、加入时间。任务列表存在 ~/.claude/tasks/ 目录下,每个任务有状态和依赖关系。
比如"撰写实测体验"这个任务被设置为 blocked by fact-checker、source-collector、image-planner 三个任务——也就是说,这三个人没做完,experience-writer 就不能开始。这个依赖关系是 team lead 在创建任务时设定的。
实际协作过程
前 3 个 agent(fact-checker、source-collector、image-planner)并行开跑,各干各的。source-collector 最先交活,fact-checker 紧跟着完成,image-planner 最后。
有意思的是 experience-writer。它的任务被设置为 blocked by 前面三个——按设计应该等它们都完成才开始。但实际上,experience-writer 没等 image-planner 做完就开始写了。任务依赖没有被强制执行,agent 可以选择无视 blockedBy 约束。这算是一个 bug,但某种程度上也像真实团队——总有人不等排期就动手了。
另一个体感:等待是真实存在的。不像子代理那样派出去几十秒就回来。Agent Teams 里每个 agent 是独立实例,各自在干自己的活,lead 能做的就是等消息。
什么时候该用
用完一次之后的真实感受:
有依赖关系、需要多步协调、各步骤的产出会影响后续步骤的任务,适合 Agent Teams。比如这次的文章流程——先核查事实、收集资料,再写体验章节,最后统一编辑。这种"流水线"式的任务编排,用子代理很难做到。
几个独立的任务,各做各的不需要互相参考,用 Task tool 并行派出去就行,更快更省 token。
关于成本:HN 上有人分享了实测数据——4 个 agent 处理一个 5 万行的 FastAPI 项目,6 分钟跑完,单 agent 要 18 分钟。速度快了 3 倍,token 也花了约 4 倍。写一篇公众号文章用 5 个 agent 有点"杀鸡用牛刀",但大型代码重构、多模块并行开发这种场景,这个投入产出比就合理了。
这东西指向哪里
Agent Teams 现在还是实验功能,有 bug,有限制,token 费用高。对大多数日常任务来说,第一层的 Task tool(并行子代理)已经够用了。
但 Anthropic 用16个 agent 写出能编译 Linux 的 C 编译器这件事,说明了一个方向:AI 协作不再是"你问我答",而是多个 AI 像团队一样分工、沟通、协调。
对独立开发者和小团队来说,这意味着"人手不够"这个问题的解法可能正在从"招人"变成"开 agent"。
不是今天就能替代,但方向已经很清楚了。
如果你想自己试试:export CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1,然后告诉 Claude 你想要什么团队就行。不需要写代码,不需要配 YAML。遇到 bug 别意外——毕竟还是实验功能。