AI学术圈和Linux内核工程圈的gap是非常大的!
- 2026-06-23 17:02:20
首先,并不是说 AI 来了,内核就无事可做了。有没有 AI,内核本身依然有大量痛点需要解决。比如在调度器里,功耗与性能的最优平衡、调度延迟造成UI 卡顿、优先级翻转、用户态锁导致的优先级翻转等问题,都还有很多工作要做。
在内存管理方面,同样挑战重重:内存申请延迟、回收延迟与开销、内存碎片化、LRU 回收精准度(如何降低 refault)、large folios 如何真正稳定发挥作用、readahead(file 与 swap-in)的命中率提升、swap-out / swap-in 的性能优化等等。
此外,文件系统性能提升、多种混合存储介质的协同利用、large folios 的文件系统支持等方向,也都有大量可以深挖和优化的空间。
可以说,可“卷”的地方依然无穷无尽。尤其是在当下内存与存储成本持续上涨的背景下,内核工程师能做、也值得做的事情,仍然非常多。
现在既然 AI 来了,各种相关论文也就随之而来——用 AI 优化内核的、用 AI 自己写调度器的、做 I/O 算法的、用 AI 调 Linux 系统参数的。假设我们把这些统称为 “AI 改造 kernel”,可以说是雨后春笋般冒出来,各类 paper 漫天飞舞。
这一点首先要理解:学术圈本身就需要通过不断提出新概念、发表论文来推动研究与评价体系运转——不然那么多硕士、博士怎么毕业呢?
但问题来了:每天看到这么多论文飞来飞去,我们是不是也要跟着它们像无头苍蝇一样到处乱撞、四处追逐?
其实大可不必。Linux 内核社区的工程实践有它自身非常稳定的演进规律。总体来说,这些论文对内核社区的实际影响是相当有限的。我感觉主要有两个原因:
写论文的人,通常并不是长期深度参与内核社区的一线工程师;
内核社区整体是一种相对稳态、保守、工程优先的推进方式——不会因为某篇论文在某个 workload、某个 benchmark 上取得了提升,就立刻大幅转向、到处铺开尝试。
换句话说,论文可以提供思路和启发,但距离进入主线、影响真实系统,还有非常长的一段工程与验证路径要走。可以说,99%的论文都是进入不了内核社区成为mainline的一部分的。
笔者前几天摘要Paper摘要:Linux内核调度器的LLM Agent框架这篇paper的时候,也有童鞋在留言区抱怨这里面的工作都是KPI工程。这个抱怨我不太认可,因为学术圈和工程圈比较评价和价值体系都一样。但是我认可学术圈和内核社区工程圈在这块的GAP真地是非常大的。
比如说,2021年,学术界诞生了一篇非常有影响力的paper:
https://arxiv.org/abs/2111.11554
KML: Using Machine Learning to Improve Storage Systems
它提出了一种kernel space的机器学习框架,在内核态做推理,用于改善I/O预读、NFS rsize等。
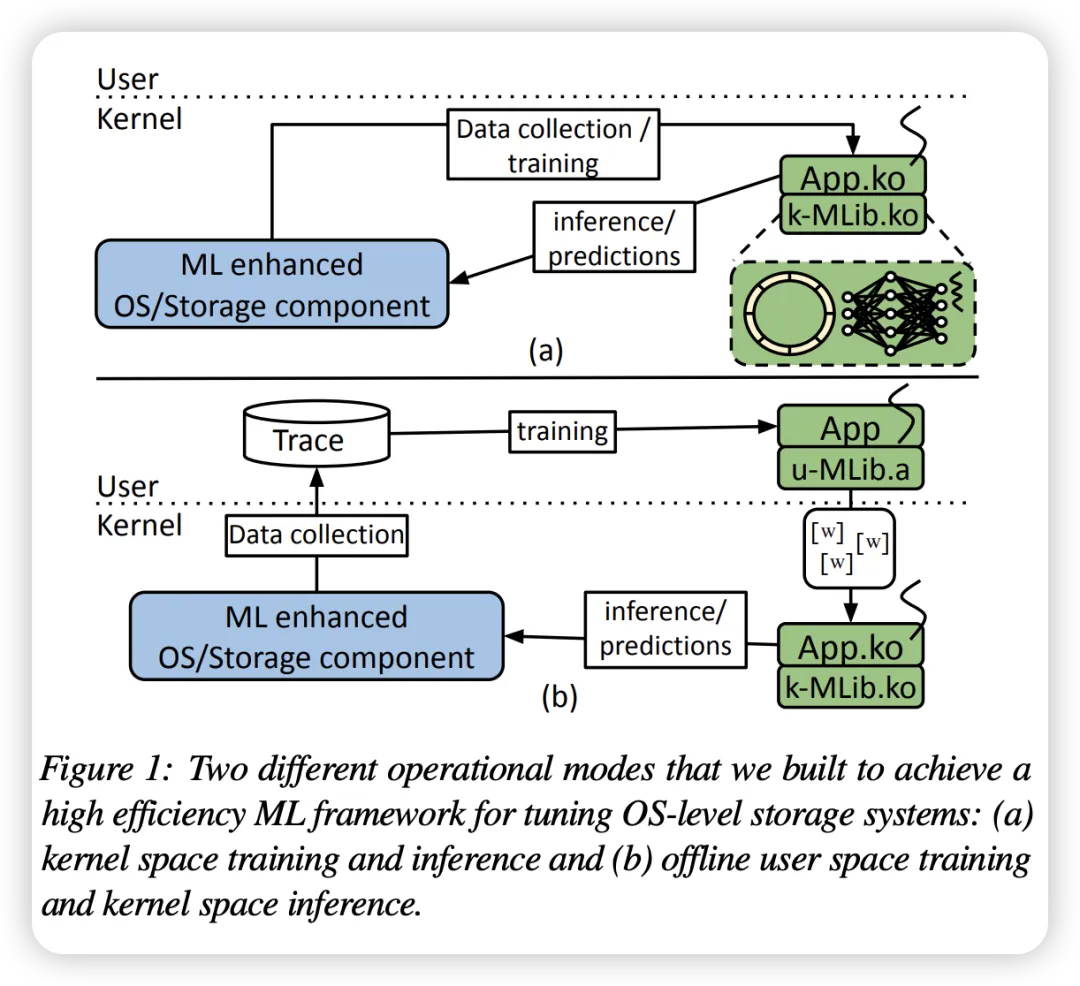
那么五年过去了,它仍然是一篇好paper而不是一个主线工程。主线合入通常需要:
长期 patch review
子系统接收
社区共识(性能 + 安全 + 可维护性)
社区共识有时候是非常难的,比如社区会质疑,为嘛不直接对现在的启发式预读算法进行优化而是引入machine learning到内核?真实的意义究竟有多大?各种开销多大?通用性如何?可维护性如何?
所以,什么东西能进入社区,怎么能进入社区,有多大的难度,作为一个工作了很多年的内核码农,我们需要有一些基本的直觉。不能看到一篇paper就好兴奋,毕竟“花繁柳密处拨得开方见手段”。
我的感觉是,如果长远无法进入mainline的东西,就不要花太多精力去折腾了,因为折腾完的结果,它长远也是死。out-of-tree的维护成本都能直接杀死进不了mainline的东西,未来进入mainline的你的代码的替代品也能杀死你的代码。内核码农写出来的代码的寿命是与能进mainline的可能性成正比的。
但是不能说,“AI改造kernel”这个方向它就错了,目前这个方向它可以说还是有成果的,比如用AI自适应调Linux的参数,或者我们可以进一步研究强化学习来提升文件readahead、swap-in readahead的准确度等,这个还是需要探索的,也需要强有力的社区投入才可能看到未来。
对于内核工程师来说,现阶段更紧迫、也更容易产生成果的方向,或许不是“用 AI 改造 kernel”,而是“为 AI 改造 kernel”。
因为大模型要真正跑起来,就必然会对系统资源提出全新的要求:CPU、GPU、NPU 之间如何更合理地调配;在大模型负载下,怎样降低内存占用、减少内存拷贝;I/O 的加载路径如何加速——这些地方都蕴含着大量优化机会。
内核工程师完全可以和 AI framework 以及应用侧工程师协同起来,在端到端链路中挖掘优化点。一方面类似豆包搞agent、Google搞Gemini、各种手机厂商搞各种智能助手搞地如火如荼,上层的工程师每天都在卷,我们内核码农也不能闲着。要跟他们打成一片,上下左右都打通。比如 agent /LLM运行时,在整条 AI pipeline 上,不同大模型与 camera、屏幕、GPU、NPU、DMA 引擎等多类硬件资源如何协同运转,怎么合理地使用内存带宽,进行零拷贝,进行存储I/O优化等,才能既更快、又更省电——这里面其实大有可为。
所以总结起来就是说:
1. 抛开AI不谈,kernel仍有无数工作可以卷,不能放弃了对基本功的持续追求,毕竟“风狂雨骤时立得定才是脚跟”;
2. 引入AI后,创造了kernel很多新机会——打造一个更适合AI跑的kernel,这个里面可以大胆地冲了;
3. AI优化kernel,有机会,但是别太兴奋乱冲,看准了再冲。
一会我要去bay里面搞烧烤,今天就随便聊到这里了。观点浅薄之处,还望读者朋友们海涵。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 我用 Python 写了个交易机器人,亏了 7 万块
- 「自研工具开源」基于Python+Playwright的AI聚合工具开发实践-集成操控DeepSeek、豆包、千问Web版,文件批量上传效率倍增
- 强烈推荐:一文洞悉Python常考5种排序算法
- 限时优惠最后3天|GEE Python版深度学习与全球尺度制图实战特训营
- AutoCAD | Python 高级应用 多开·多版本·多文档
- Python的re模块
- Python 与 Java 项目依赖管理
- Linux嵌入式以太网硬件接口详解
- 【操作系统】linux安装minio并使用
- Linux 命令大全汇总 新手老手都能吃透
