用Python进行12种回归分析实战:Scikit-learn库(2000字简析)
在表格数据预测和变量关系分析中,回归分析是核心方法。虽然深度学习擅长处理图像、文本等非结构化数据,但面对结构化数据预测,传统机器学习方法仍是可靠选择。本文将基于Scikit-learn库,介绍12种实用回归分析方法。使用Scikit-learn进行回归分析遵循四步流程:1. 数据准备
清洗数据,处理缺失值,完成特征工程,划分训练集与测试集。2. 模型构建与训练
3. 模型评估
4. 结果可视化
一、 经典回归 (Classics Regression)
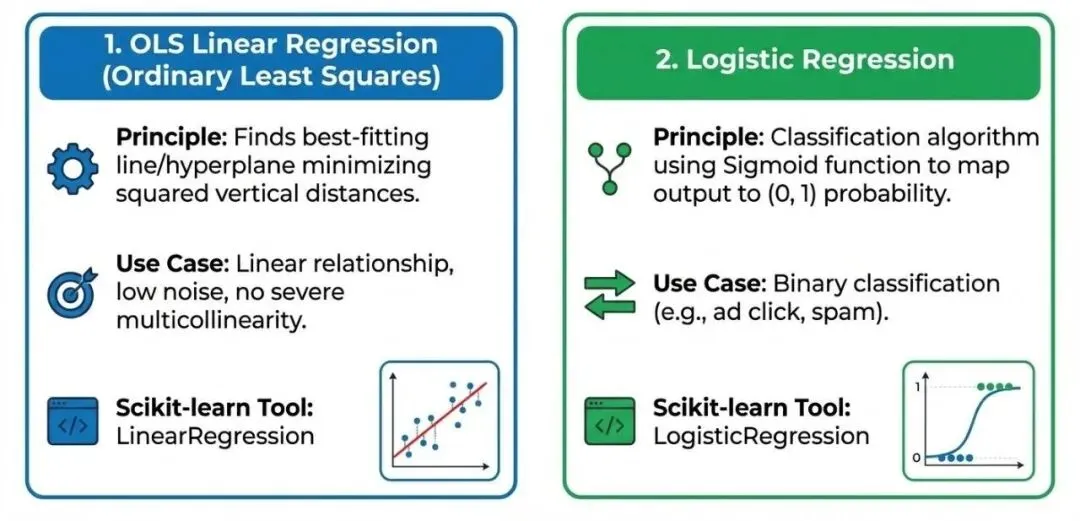
这些是回归分析的起点,适用于变量间存在明显线性关系的数据。1. 普通最小二乘法线性回归 (Ordinary Least Squares - OLS Linear Regression)
最基本的回归形式,旨在找到一条直线(或超平面),使得所有数据点到这条直线的垂直距离平方和最小。特征与目标变量呈线性关系,数据噪声较小,无严重多重共线性。Scikit-learn工具:LinearRegression2. 逻辑回归 (Logistic Regression)
虽然名字里有“回归”,但它实际上是一种分类算法。它通过 Sigmoid 函数将线性回归的输出映射到 (0, 1) 区间,用于估计概率。二分类问题(如:用户是否点击广告,邮件是否为垃圾邮件)。Scikit-learn工具:LogisticRegression二、 正则化回归 (Regularized Regression):应对过拟合
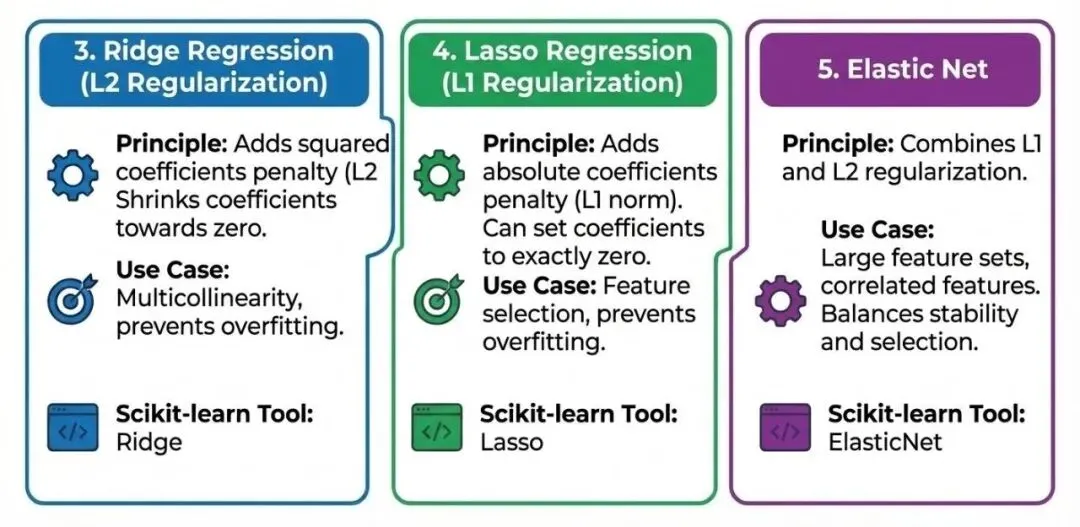
当模型在训练集上表现太好,但在测试集上表现很差时(过拟合),我们需要引入“惩罚项”(正则化)来限制模型的复杂度。3. 岭回归 (Ridge Regression - L2正则化)
在损失函数中增加系数的平方和作为惩罚项(L2范数)。这会迫使系数趋向于0,但不会等于0。处理多重共线性(特征间高度相关)数据,防止过拟合。4. 套索回归 (Lasso Regression - L1正则化)
在损失函数中增加系数的绝对值之和作为惩罚项(L1范数)。其重要特性是可以将不重要的特征系数压缩为绝对的0。不仅需要防止过拟合,还需要进行特征选择(自动剔除无用特征)时。5. 弹性网络 (Elastic Net)
岭回归和套索回归的结合体,同时使用 L1 和 L2 正则化。当特征数量庞大,且存在多组相关特征时,它结合了 Lasso 的特征选择能力和 Ridge 的稳定性。Scikit-learn工具:ElasticNet三、 鲁棒回归 (Robust Regression):应对异常值
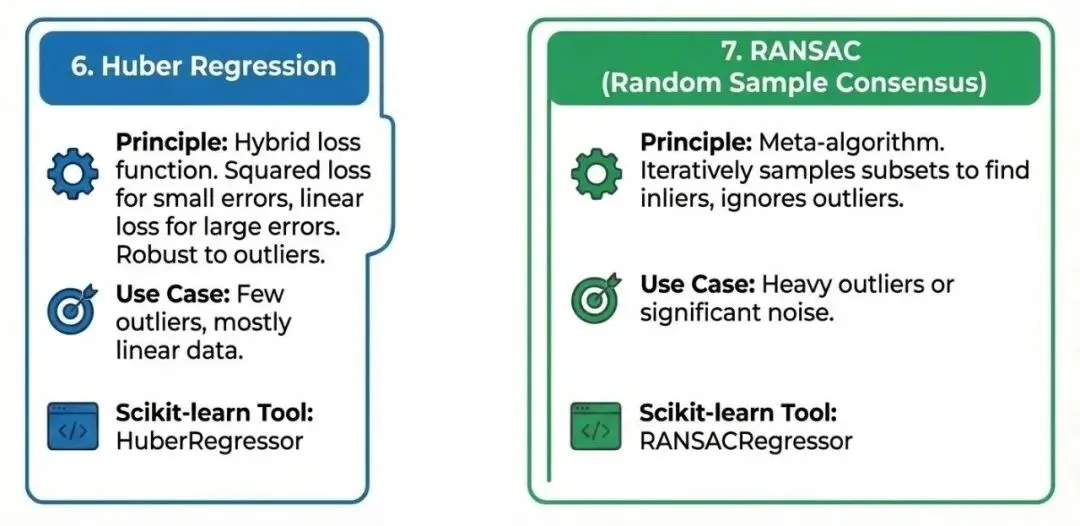
现实数据往往不干净,包含离群点(Outliers)。普通的线性回归很容易被这些极端值“带偏”。6. Huber 回归 (Huber Regression)
使用一种混合损失函数。对于小误差使用平方损失(类似 OLS),对于大误差使用线性损失(类似绝对值误差)。这使得它对离群点不那么敏感。数据中存在少量离群点,但大部分数据仍符合线性趋势。Scikit-learn工具:HuberRegressor7. RANSAC (随机抽样一致性算法)
这不是一种单一的回归模型,而是一种元算法。它反复随机抽取数据子集来训练模型,并将不能被模型很好拟合的点标记为离群点,最终仅使用“局内点”进行拟合。Scikit-learn工具:RANSACRegressor四、 处理非线性与复杂(Nonlinear and Complex)关系
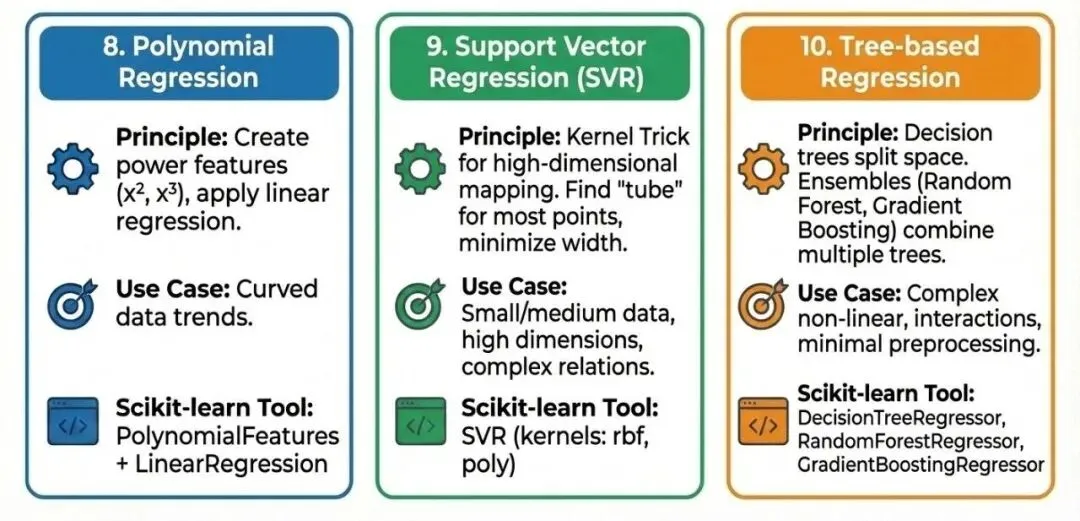
当特征与目标之间不再是简单的直线关系时,我们需要更强大的模型。8. 多项式回归 (Polynomial Regression)
通过将原始特征进行幂次组合(如 x2,x3,x1⋅x2x2,x3,x1⋅x2)创建新特征,然后在新特征上应用线性回归。Scikit-learn实现:使用PolynomialFeatures进行特征转换,再接入LinearRegression。9. 支持向量机回归 (Support Vector Regression - SVR)
利用核函数(Kernel Trick)将数据映射到高维空间,试图找到一个“管道”,使得大部分数据点都包含在管道内,并最小化管道的宽度。Scikit-learn工具:SVR (常用核函数如 rbf, poly)10. 基于树的回归 (决策树/随机森林/梯度提升)
决策树通过不断分裂数据空间来进行预测。随机森林和梯度提升(如 GBDT, XGBoost, LightGBM)则是集成多个决策树的强大方法。处理复杂的非线性关系、交互作用,且不需要对数据进行过多的预处理(如特征缩放)。Scikit-learn工具:DecisionTreeRegressor, RandomForestRegressor, GradientBoostingRegressor五、 广义线性模型 (GLM):应对特殊数据类型
有时候目标变量 Y 并不服从正态分布,比如它可能是计数或者概率。11. 泊松回归 (Poisson Regression)
目标变量服从泊松分布,即非负整数值(计数数据),且满足"均值=方差"的特性。通过对数连接函数将线性预测值与均值连接,确保预测值始终为正。目标变量是计数数据(例如:某路口一小时内的车流量、网站一天的点击量)。Scikit-learn工具:PoissonRegressor12. Gamma 回归 (Gamma Regression)
目标变量服从Gamma分布,即连续正值数据(如金额、时间、尺寸等)。通过对数连接函数或倒数连接函数建立关系。目标变量方差随均值的增加而增加(例如:保险索赔金额、特定事件的等待时间)。Scikit-learn工具:GammaRegressor总结
回归分析远非“画一条直线”那样简单。数据分析时需要根据数据特征,从Scikit-learn等工具箱中挑选匹配的回归模型。
基于对这些问题的回答,选出适合的模型,让分析结果贴合数据本质!