基于Python图书借阅推荐系统
✅️基于用户协同过滤算法
✅️参考lun文1w8多字
✅️爬虫可用
采用Django框架进行后端开发,结合MySQL数据库进行数据存储,并使用Vue.js构建前端界面。系统实现了用户注册、登录、图书搜索、借阅、归还等核心功能,同时提供了后台管理模块,包括用户管理、图书管理、借阅管理等,以满足图书馆管理者和读者的需求。通过分层架构设计,系统保证了高内聚、低耦合的特性,使得维护和扩展变得更加容易。此外,系统还经过了全面的测试,包括功能测试、性能测试、兼容性测试和安全性测试,确保了系统的稳定性和可靠性。
功能介绍
平台采用B/S结构,后端采用主流的Python+Django语言进行开发,前端采用主流的Vue.js进行开发。
整个平台包括前台和后台两个部分。
前台功能包括:首页、图书推荐、图书详情页、用户中心模块。
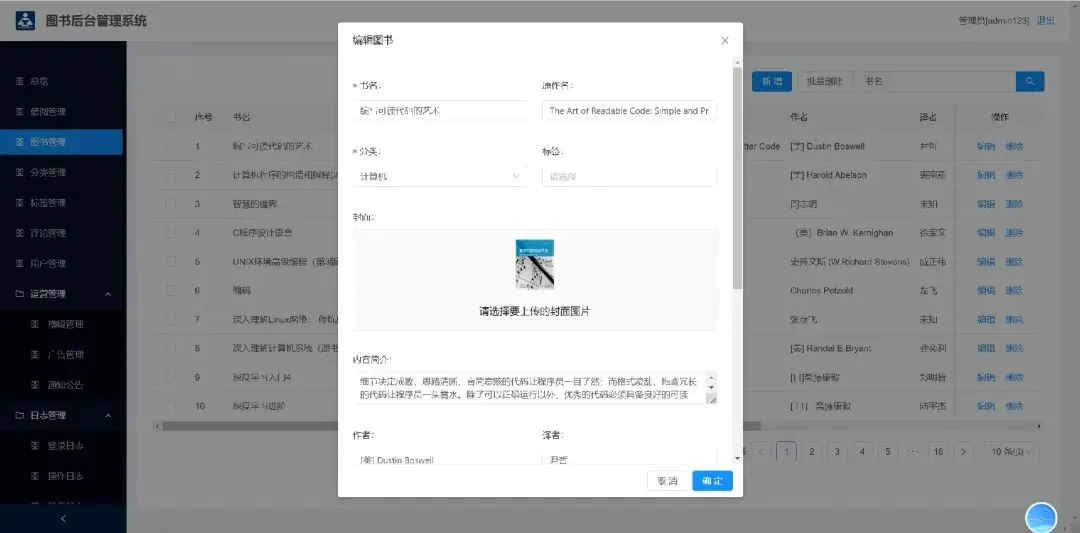
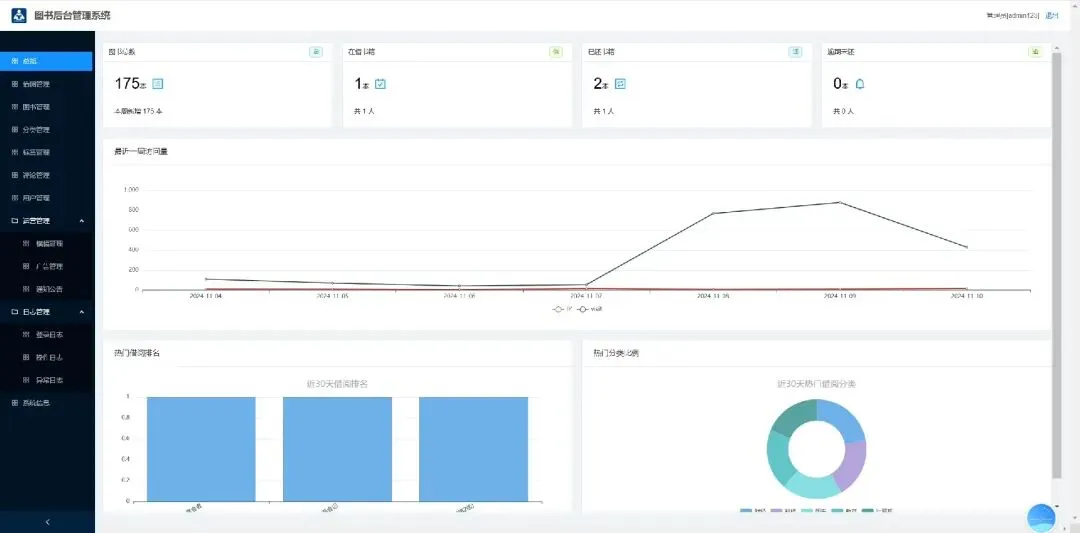
后台功能包括:总览、借阅管理、图书管理、分类管理、标签管理、评论管理、用户管理、运营管理、日志管理、系统信息模块。
用户-图书评分矩阵构建:
通过 build_user_item_matrix() 函数构建了一个用户-图书评分矩阵,其中每个用户对图书的评分是根据用户的行为来设定的:收藏书籍的评分为 1。
心愿书籍的评分为 0.5。
其他书籍的评分默认为 0。
该矩阵的行表示用户,列表示图书,矩阵中的值表示该用户对该图书的评分。
计算用户相似度:
使用 余弦相似度 (cosine_similarity) 来计算所有用户之间的相似度。余弦相似度是衡量两个向量之间夹角的余弦值,常用于计算文本或行为数据之间的相似度。在这里,用户的行为矩阵(即评分矩阵)被视为用户的特征向量。
推荐逻辑:
根据计算得到的用户相似度矩阵,为目标用户推荐与其行为相似的其他用户所喜欢的书籍。推荐的书籍是那些目标用户未曾收藏或添加到心愿单中的书籍,并且这些书籍是与目标用户相似的用户所收藏或加入心愿单的。
推荐书籍的数量限制为最多 12 本。
协同过滤:
基于用户的协同过滤:通过计算用户之间的相似度,推荐与目标用户相似的其他用户喜好的图书。
总结:此推荐系统通过构建用户-图书评分矩阵,利用余弦相似度计算用户之间的相似度,并根据相似用户的行为(收藏和心愿书籍)推荐用户可能感兴趣的图书。