当系统突然OOM崩了、服务卡得没响应,多数人第一反应是查应用日志、看代码有没有内存泄漏。其实很多时候,问题的根源藏在一个容易被忽略的地方——Linux 内核的内存布局。
对Linux系统来说,内核内存怎么分区、地址怎么分配、资源怎么调度,直接决定了系统能不能扛住压力。内核夹在硬件和应用中间,既要跑自身代码,又要管设备映射、进程调度这些杂事,而内存布局就是管这些事的“底层规则”。代码段、数据段、虚拟内存区的划分,不光影响内存访问快不快,更决定了会不会出现资源冲突。
一、先搞懂:Linux内核内存布局
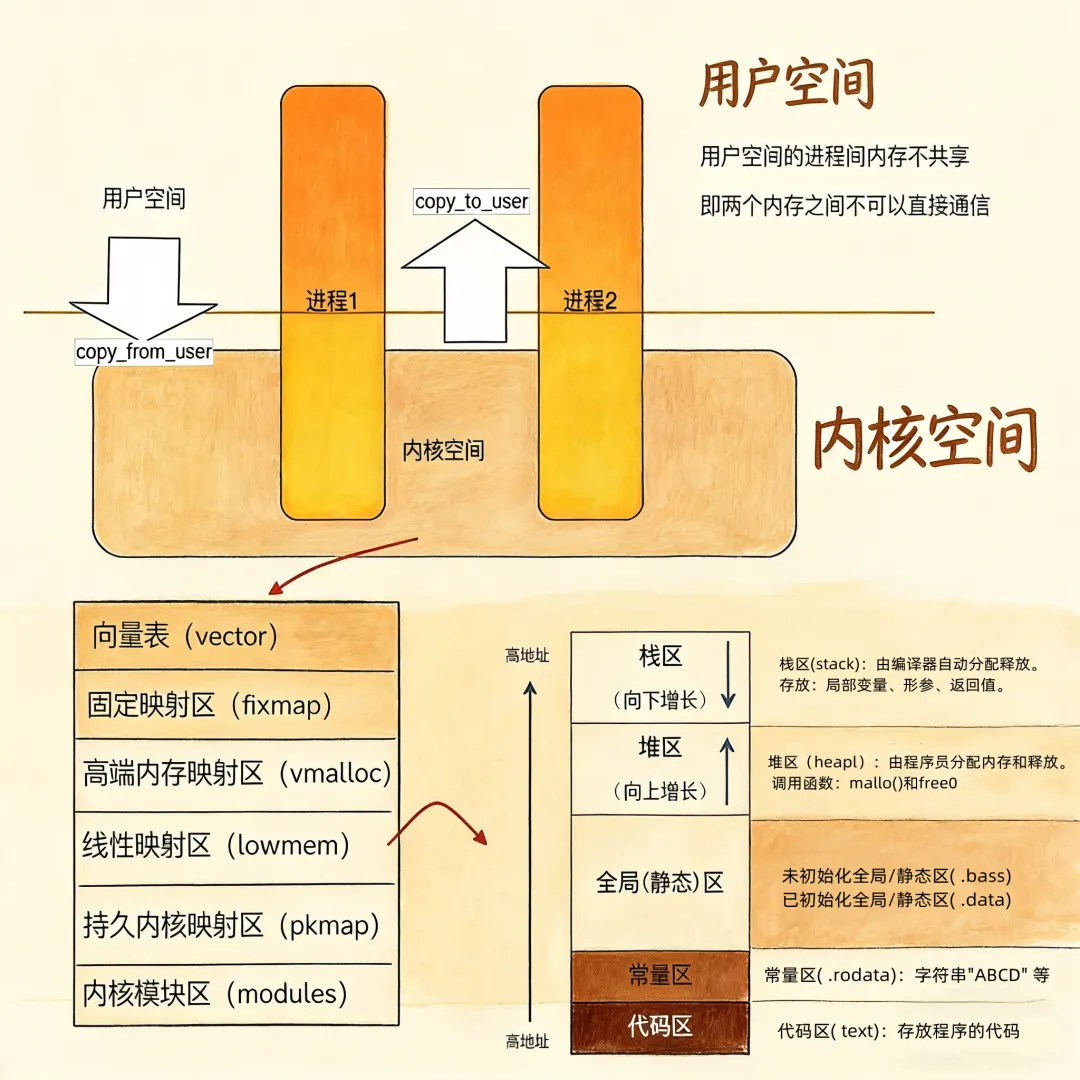
1.1 一张图看懂内核内存布局
先上一张核心布局图,直观感受下内存空间的划分:
从图中可清晰看到,整个虚拟内存空间被划分为用户空间和内核空间两大块。先明确两个核心概念,为后续理解铺路:
再梳理布局中实战易出问题的关键区域:
向量表(vector):存储异常处理程序的入口地址,系统触发中断、出现异常时,会直接跳转到此处执行对应逻辑,相当于企业的应急响应中心。
固定映射区(fixmap):系统启动时确定的映射关系,用于映射硬件相关的物理地址,映射关系不可动态修改,如同公司里固定的设备摆放位置。
高端内存映射区(vmalloc):专用于分配“虚拟地址连续、物理地址不连续”的内存块,例如大文件读入内核内存时常用此区域,如同将分散的储物格整合为对外连续的存储空间。
线性映射区(lowmem):内核最核心的区域,直接映射部分物理内存。内核的代码段(.text)、初始化段(.init)、数据段(.data)、BSS段(.bss)均位于此:
持久内核映射区(pkmap):作为内核访问高端内存的“桥梁”,实现对高端物理内存的稳定映射。
内核模块区(modules):动态加载内核模块(.ko文件)的区域,例如新增硬件驱动时,驱动模块会被加载至此,如同公司的临时办公区域。
1.2 地址空间划分背后的架构设计
64位Linux系统的虚拟地址空间高达256TB,用户空间与内核空间的界限清晰:
这种划分并非随意设定,核心是兼顾安全隔离与访问性能:
安全层面:用户态与内核态严格隔离,用户进程仅能在自身空间活动,无法直接访问内核空间。笔者曾遇到嵌入式设备故障,原因是驱动程序存在逻辑错误,试图越界访问内核空间,直接导致系统panic崩溃——这如同员工闯入机房乱碰设备,必然引发系统故障。
性能层面:内核态代码拥有直接访问物理内存的权限,效率极高。例如ARM64架构中,通过固定偏移量(PAGE_OFFSET = 0xFFFF_8000_0000_0000)可快速转换虚拟地址与物理地址,无需复杂的页表查询;而用户态程序访问内核资源需通过系统调用,虽增加了一层交互,但保障了系统的整体秩序。
这里需重点区分ARM64与ARM32架构的内存布局差异,这在实战选型与配置调优中至关重要:
ARM64架构:布局简洁高效,拥有128TB的线性映射区,可直接覆盖所有物理内存,无需复杂的高端内存映射;同时配备126TB的vmalloc动态映射区,适用于DMA缓冲区分配等需要物理不连续内存的场景,大数据传输时优势显著。
ARM32架构:布局相对复杂,1GB的内核空间中仅768MB用于线性映射低端内存,剩余264MB需通过pkmap持久映射区访问。物理内存较小时问题不明显,一旦超过阈值,易出现映射资源竞争,导致kmalloc分配失败,服务直接中断。笔者曾维护的ARM32工业设备,就因该问题频繁故障,最终只能通过限制内存使用场景缓解。
二、用户空间内存布局
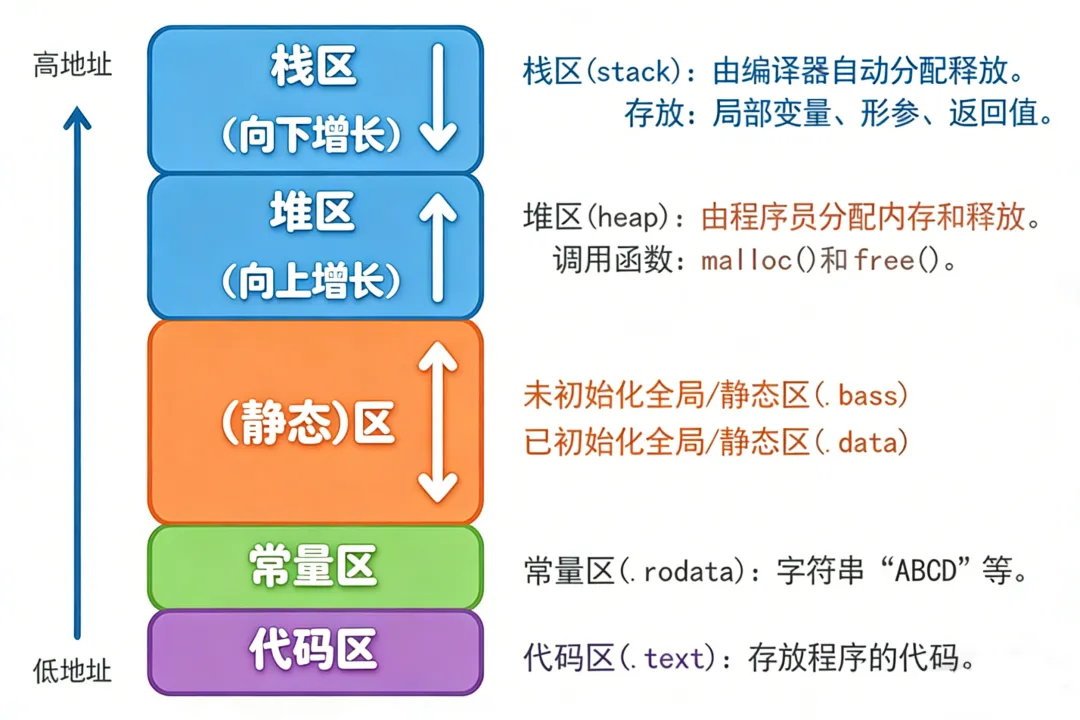
用户空间内存布局是应用程序运行的基础,不同区域各司其职,如同房屋的不同房间,承担着不同功能。先看布局图:
2.1 代码段(.text):
代码段存储编译后的机器指令,是应用的核心逻辑载体,且只读——这一特性可防止程序运行时篡改自身执行逻辑,保障运行稳定性。
例如简单的C程序:
#include<stdio.h>intmain(){ printf("Hello, Linux!\n"); return 0;}
编译后,main函数中的printf调用、return语句等逻辑均存储在代码段。程序启动后,CPU从代码段读取指令并依次执行。实战中若遇到程序执行逻辑异常,除排查代码bug外,还需检查代码段是否被非法篡改(如病毒攻击、内存越界污染)。
2.2 数据段(.data):已初始化数据的“专属仓库”
数据段专门存储已初始化的全局变量和静态变量,程序运行时可读写。例如:
#include<stdio.h>int global_variable = 10; // 已初始化全局变量static int static_variable = 20; // 已初始化静态变量intmain(){ printf("Global variable: %d\n", global_variable); printf("Static variable: %d\n", static_variable); return 0;}
这两个变量在编译时已赋予初始值,会持续存储在数据段直至程序结束。实战中若全局变量值异常,需考虑多线程竞争修改、内存越界覆盖等问题。
2.3 BSS段:未初始化数据的“临时收容所”
BSS段存储未初始化的全局变量和静态变量,程序加载时系统会自动将这些变量初始化为0。例如:
#include<stdio.h>int global_uninit; // 未初始化全局变量static int static_uninit; // 未初始化静态变量intmain(){ printf("Global uninit variable: %d\n", global_uninit); printf("Static uninit variable: %d\n", static_uninit); return 0;}
运行后可见,两个变量的值均为0。这里有个实战知识点:BSS段在磁盘上不占用空间,仅在程序加载到内存时分配空间,因此即使程序中有大量未初始化的全局变量,也不会增加可执行文件的大小。
2.4 堆(Heap):动态内存的“弹性空间”
堆是程序运行时动态分配内存的区域,需通过malloc、calloc等函数申请,用完后需手动用free释放。堆的增长方向为低地址到高地址,大小可动态调整。例如:
#include<stdio.h>#include<stdlib.h>intmain(){ int *ptr = (int *)malloc(10 * sizeof(int)); // 分配10个int大小的内存 if (ptr != NULL) { for (int i = 0; i < 10; i++) { ptr[i] = i; } for (int i = 0; i < 10; i++) { printf("%d ", ptr[i]); } free(ptr); // 释放内存 } return 0;}
现实中堆是内存问题的重灾区:
因此,写代码时需做好堆内存管理,尽量避免频繁的小块内存动态分配,必要时可采用内存池优化。
2.5 栈(Stack):临时数据的“自动回收箱”
栈用于存储局部变量、函数调用参数、返回地址等临时数据,增长方向与堆相反,为高地址到低地址。函数调用时会在栈上创建“栈帧”,存放当前函数的相关数据;函数执行完毕后,栈帧自动销毁,内存随之释放。例如:
#include<stdio.h>voidfunction(int a, int b){ int c = a + b; // 局部变量存在栈上 printf("The result is: %d\n", c);}intmain(){ int x = 5; int y = 3; function(x, y); // 调用函数时创建栈帧 return 0;}
栈的优点是高效、无需手动管理内存,但缺点是空间有限。实战中若遇到栈溢出错误(如递归调用层数过多、局部变量占用空间过大),可通过ulimit -s调整栈大小临时缓解,但根本解决方法是优化代码(如减少递归深度、将大块局部变量改为动态分配)。
2.6 内存映射段:应用与外部资源的“桥梁”
内存映射段通过mmap系统调用创建,主要用于文件映射、加载动态库。其核心原理是将磁盘文件或动态库直接映射到内存,应用可像访问内存一样访问这些资源,效率远高于传统的文件读写。
例如加载动态库时,动态库的代码和数据会被映射到该区域,多个应用可共享同一个动态库的映射,无需重复拷贝,节省内存。以下是动态库加载的实战案例:
① 编写动态库代码(libmath.so):
// math_lib.cppextern "C" { // 避免C++名称修饰,方便C语言调用 intadd(int a, int b) { return a + b; } intmultiply(int a, int b) { return a * b; }}
② 编译动态库:
g++ -fPIC -shared -o libmath.so math_lib.cpp
③ 编写主程序加载动态库:
#include<iostream>#include<dlfcn.h>// 动态库加载头文件intmain(){ // 1. 加载动态库(映射到内存映射段) void* lib_handle = dlopen("./libmath.so", RTLD_LAZY); if (!lib_handle) { std::cerr << "dlopen failed: " << dlerror() << std::endl; return 1; } // 2. 获取函数地址(从内存映射段查找) dlerror(); // 清除之前的错误 typedefint(*AddFunc)(int, int); AddFunc add = reinterpret_cast<AddFunc>(dlsym(lib_handle, "add")); const char* err = dlerror(); if (err) { std::cerr << "dlsym add failed: " << err << std::endl; dlclose(lib_handle); return 1; } typedefint(*MultiplyFunc)(int, int); MultiplyFunc multiply = reinterpret_cast<MultiplyFunc>(dlsym(lib_handle, "multiply")); err = dlerror(); if (err) { std::cerr << "dlsym multiply failed: " << err << std::endl; dlclose(lib_handle); return 1; } // 3. 调用动态库函数 int a = 10, b = 20; std::cout << a << " + " << b << " = " << add(a, b) << std::endl; std::cout << a << " * " << b << " = " << multiply(a, b) << std::endl; // 4. 关闭动态库(解除映射) dlclose(lib_handle); return 0;}
④ 编译运行:
g++ -o main main.cpp -ldl # -ldl 链接动态库加载库./main
实战注意点:
mmap的权限不能超过文件本身的打开权限(如只读文件不能映射为可写);
区分MAP_SHARED和MAP_PRIVATE:MAP_SHARED的修改会同步回原文件,适用于多进程共享;MAP_PRIVATE的修改仅对当前进程有效,采用写时复制机制;
编译动态库必须加-fPIC(生成位置无关代码)和-shared,否则加载失败;
用完后需及时用munmap释放映射、dlclose关闭动态库,避免内存泄漏。
三、32位系统内核空间内存布局
32位Linux系统的内核空间占虚拟地址空间的最高1GB,地址范围为0xC0000000 ~ 0xFFFFFFFF。尽管当前64位系统已成为主流,但大量嵌入式、工业控制设备仍在使用32位系统,其内存布局的风险点需重点掌握。
3.1 线性映射区(lowmem):内核的“高速通道”
线性映射区从0xC0000000开始,默认延伸至0xC0000000+768MB的位置(high_memory)。此处虚拟地址与物理地址为1:1映射(虚拟地址=物理地址+0xC0000000,即PAGE_OFFSET),无需复杂的页表查询,访问速度最快。
内核的代码段、数据段、BSS段,以及task_struct(进程控制块)、mm_struct(进程内存管理结构体)等核心结构体均存储于此。实战中若该区域被占满,内核将无法正常运行,因此需重点监控其占用情况。
3.2 vmalloc动态映射区:灵活但低效的“补充空间”
vmalloc区位于线性映射区末尾至0xEF800000之间,约240MB。其特点是可分配虚拟地址连续、物理地址不连续的内存,通过vmalloc接口申请,适用于DMA缓冲区分配、加载大内核模块、内存碎片化严重时的大内存分配场景。
但需注意,vmalloc的访问速度远低于线性映射区——由于物理地址不连续,需遍历页表查找物理地址,且TLB命中率较低。实战中应尽量少用vmalloc,尤其是对性能要求高的场景,避免拖慢系统。
3.3 高端内存映射区:超过896MB内存的“访问桥梁”
32位系统若物理内存超过896MB,超出部分为高端内存,无法直接映射到线性映射区,需通过高端内存映射区访问。内核通过alloc_pages函数加__GFP_HIGHMEM标志分配高端内存页,再用kmap函数映射到高端内存映射区,访问完毕后用kunmap释放。
例如科学计算、大数据处理等需要大内存的场景,可能会用到高端内存。实战中需注意:kmap映射后必须及时kunmap,否则会导致高端内存被长期占用,其他进程无法访问。
3.4 Fixmap固定映射区:系统启动期的“临时工具”
Fixmap区位于0xFFF00000 ~ 0xFFFE0000,共896KB。此处虚拟地址在编译时固定,运行时绑定物理地址,主要用于系统启动早期(MMU未初始化时)、设备I/O内存映射(如PCI设备寄存器)、CPU间通信缓冲区等场景。
实战中需注意,该区域地址固定,绑定物理地址时需避免冲突,且空间有限,不可滥用。
3.5 持久内核映射区(PKMap):高端内存的“长期访问通道”
PKMap区专用于映射高端内存,方便内核长期访问。内核会维护一张映射表,记录高端内存页与虚拟地址的对应关系,访问时先查映射表,存在则直接使用,不存在则分配虚拟地址建立映射。
例如数据库应用需要长期访问高端内存中的数据时,会用到该区域。实战中需监控映射表的使用情况,避免映射过多导致资源耗尽。
四、内核内存管理的核心机制
4.1 页表与地址转换:虚拟内存的“翻译官”
CPU访问的是虚拟地址,而数据实际存储在物理内存中,页表就是负责将虚拟地址翻译为物理地址的核心组件。x86架构采用四级页表:PGD(页全局目录)、PUD(页上级目录)、PMD(页中间目录)、PT(页表)。
地址转换流程:
CPU用虚拟地址的高位索引查找PGD表项;
PGD表项指向PUD,用次高位索引查找PUD表项;
依次查找PMD、PT表项,最终在PT中找到物理页帧号;
物理页帧号加上页内偏移,即为最终的物理地址。
实战要点:
每个进程拥有独立的页表,因此不同进程的虚拟地址可重叠,但映射到不同的物理内存,实现进程隔离;
页表可设置权限(只读、可写、可执行),例如内核代码段设为只读可执行,防止被篡改;
若遇到权限错误、地址访问错误,大概率是页表配置错误或内存越界导致。
4.2 内存分配与回收:系统稳定的“调节器”
内核提供了多种内存分配函数,其中kmalloc和vmalloc是最常用的两个,两者的区别需重点掌握:
| 特性 | kmalloc | vmalloc |
|---|
| 物理地址 | 连续 | 不连续 |
| 虚拟地址 | 连续 | 连续 |
| 分配效率 | 高(基于Slab分配器) | 低(需修改页表) |
| 适用场景 | 小型缓冲区(如设备驱动) | 大内存块(如加载内核模块) |
kmalloc示例(分配1024字节的网络设备接收缓冲区):
#include<linux/module.h>#include<linux/kernel.h>#include<linux/slab.h>intinit_module(void){ char *buffer; buffer = kmalloc(1024, GFP_KERNEL); if (buffer == NULL) { printk(KERN_ERR "Failed to allocate memory via kmalloc\n"); return -ENOMEM; } // 使用缓冲区 snprintf(buffer, 1024, "Hello, kernel memory!"); printk(KERN_INFO "Buffer content: %s\n", buffer); kfree(buffer); return 0;}voidcleanup_module(void){ printk(KERN_INFO "Module cleaned up\n");}MODULE_LICENSE("GPL");MODULE_DESCRIPTION("kmalloc Example Module");
vmalloc示例(分配1MB内存):
#include<linux/module.h>#include<linux/kernel.h>#include<linux/vmalloc.h>intinit_module(void){ void *large_buffer; large_buffer = vmalloc(1024 * 1024); // 分配1MB内存 if (large_buffer == NULL) { printk(KERN_ERR "Failed to allocate memory via vmalloc\n"); return -ENOMEM; } // 使用缓冲区 memset(large_buffer, 0xAA, 1024 * 1024); printk(KERN_INFO "1MB memory allocated via vmalloc\n"); vfree(large_buffer); return 0;}voidcleanup_module(void){ printk(KERN_INFO "Module cleaned up\n");}MODULE_LICENSE("GPL");MODULE_DESCRIPTION("vmalloc Example Module");
内存回收机制:当系统内存紧张时,内核会启动内存回收,主要回收两类页面:
实战中若系统频繁回收内存,需检查是否存在内存泄漏、应用内存使用过度等问题。
五、内存布局失衡的坑
5.1 内存碎片:系统的“隐形杀手”
内存碎片分为外部碎片和内部碎片,是实战中常见的性能与稳定性问题。
(1)外部碎片
空闲内存总量充足,但均为分散的小块,无法分配连续的大内存。例如系统有1024个连续页块,频繁分配释放不同大小的内存后,会出现大量不连续的空闲块,总和虽满足分配需求,但单个块无法满足,导致分配失败。
内核通过伙伴系统解决该问题:按2的幂次分割合并内存块。例如需分配4KB内存,若无则将8KB块拆分为两个4KB,一个分配、一个保留;释放时若相邻有相同大小的空闲块,则合并为大块。但频繁分配释放小内存仍会导致碎片累积,最终触发OOM杀手,强制杀死进程释放内存,可能误杀关键进程导致服务中断。
(2)内部碎片
分配的内存块比实际需要的大,浪费的空间即为内部碎片。例如Slab分配器预分配16字节的内存块,存储8字节的对象,就会浪费8字节。内部碎片虽不直接导致分配失败,但累积后会占用大量内存,拖慢内核运行速度。例如处理大量文件操作时,文件描述符的频繁创建销毁会产生大量内部碎片,导致文件操作效率下降。
5.2 地址空间隔离失效:安全和稳定的“双重崩塌”
(1)用户态越界访问
用户态程序通过缓冲区溢出等漏洞篡改内核数据,例如修改进程调度队列导致调度混乱、篡改文件系统元数据导致数据损坏、植入rootkit获取系统最高权限。笔者曾遇到的嵌入式设备故障,就是驱动程序错误导致用户态程序越界访问内核空间,直接触发系统panic。
(2)内核模块地址冲突
加载内核模块时,模块代码段与现有内核数据区重叠,会导致内存访问错误,轻则模块失效,重则系统重启。此外,符号表解析错误、函数指针指向非法地址,也会触发页面错误。实战中加载内核模块失败时,需检查是否存在地址冲突、符号表错误等问题。
六、真实案例复盘
6.1 案例1:dentry泄漏导致LB集群内存暴涨
(1)故障场景
某电商LB集群承接上万个服务的流量转发,突发内存暴涨,部分机器内存使用率超90%且持续上升。紧急下线高内存机器后,通过slabtop发现dentry对象占比异常高,排查后定位到LB服务的curl HTTPS探测脚本——使用的curl 7.19.7版本依赖的NSS库存在dentry泄漏bug。
(2)根本原因
dentry对象用于缓存文件路径名,正常情况下文件关闭后会调用dput()释放引用计数。但NSS库使用dentry后未调用dput(),导致dentry长期驻留在Slab分配器中,不断累积后Slab占用超39GB(占总内存60%),阻塞文件描述符释放,最终触发OOM,服务节点批量下线。
(3)修复方案
升级curl和NSS库至无bug版本,手动释放累积的dentry对象。该案例提醒我们,需关注动态库与内核内存管理的兼容性,加强应用层对底层资源释放的监控。
附:dentry资源管理核心代码示例
#include<iostream>#include<unordered_map>#include<string>#include<vector>// 模拟内核dentry对象class Dentry {private: std::string file_path; int ref_count; static std::unordered_map<std::string, Dentry*> dentry_cache; // 私有构造函数,仅通过dget创建 Dentry(const std::string& path) : file_path(path), ref_count(1) {}public: // 增加引用计数(模拟内核dget()) static Dentry* dget(const std::string& path){ if (dentry_cache.find(path) != dentry_cache.end()) { dentry_cache[path]->ref_count++; return dentry_cache[path]; } else { Dentry* new_dentry = new Dentry(path); dentry_cache[path] = new_dentry; std::cout << "[Dentry] 新建目录项: " << path << ",引用计数: " << new_dentry->ref_count << std::endl; return new_dentry; } } // 减少引用计数(模拟内核dput()) staticvoiddput(const std::string& path){ if (dentry_cache.find(path) == dentry_cache.end()) { std::cerr << "[Dentry] 错误:目录项 " << path << " 不存在" << std::endl; return; } Dentry* dentry = dentry_cache[path]; dentry->ref_count--; std::cout << "[Dentry] 释放目录项: " << path << ",引用计数: " << dentry->ref_count << std::endl; // 引用计数为0时销毁对象 if (dentry->ref_count == 0) { dentry_cache.erase(path); delete dentry; std::cout << "[Dentry] 销毁目录项: " << path << std::endl; } } // 获取缓存大小 staticsize_tget_cache_size(){ return dentry_cache.size(); } ~Dentry() { std::cout << "[Dentry] " << file_path << " 析构" << std::endl; }};// 初始化静态成员std::unordered_map<std::string, Dentry*> Dentry::dentry_cache;// 模拟NSS库缺陷:未调用dput()class NSSLibrary {public: voidaccess_cert_file(const std::string& cert_path){ // 仅获取dentry,不释放(模拟泄漏) Dentry::dget(cert_path); std::cout << "[NSS库] 访问证书文件 " << cert_path << ",未释放dentry" << std::endl; }};// 模拟curl HTTPS请求class CurlHTTPS {private: NSSLibrary nss;public: voidsend_health_probe(const std::string& service_url){ std::cout << "\n[curl] 发送HTTPS探测: " << service_url << std::endl; std::string cert_path = "/etc/ssl/certs/" + service_url.substr(8) + ".pem"; nss.access_cert_file(cert_path); }};// 模拟LB服务class LBServices {private: CurlHTTPS curl;public: voidrun_probe_loop(int service_count){ std::cout << "===== LB服务启动:批量探测 =====" << std::endl; for (int i = 0; i < service_count; ++i) { std::string service_url = "https://service" + std::to_string(i) + ".example.com"; curl.send_health_probe(service_url); } }};intmain(){ LBServices lb; // 模拟探测10个服务,产生dentry泄漏 lb.run_probe_loop(10); std::cout << "\n===== 故障状态 =====" << std::endl; std::cout << "[系统] dentry缓存大小: " << Dentry::get_cache_size() << std::endl; std::cout << "[系统] Slab内存暴涨,占比超60%" << std::endl; // 模拟修复:手动释放第一个服务的dentry std::string fix_path = "/etc/ssl/certs/service0.example.com.pem"; Dentry::dput(fix_path); std::cout << "\n[系统] 修复后dentry缓存大小: " << Dentry::get_cache_size() << std::endl; return 0;}
编译运行:
g++ -o dentry_leak dentry_leak.cpp -std=c++11./dentry_leak
运行后可清晰看到dentry缓存持续增长,模拟了故障场景中的内存泄漏问题。
6.2 案例2:内存碎片导致嵌入式设备频繁重启
(1)故障场景
某ARM32嵌入式工业控制设备,频繁调用vmalloc分配非连续内存(用于网络协议栈缓冲区),导致动态映射区碎片率超80%。当需要分配128KB连续内存时,尽管物理内存还有20%空闲,但均为分散小块,伙伴系统拆分1MB块也无法满足需求,最终触发内核panic,日志显示“out of memory”,设备定时崩溃。
(2)根本原因
嵌入式设备内存资源有限,且未针对场景优化分配策略:
(3)修复方案
该案例提醒我们,嵌入式小内存场景必须精细化管理内存,避免动态分配滥用。
附:内存碎片模拟核心代码
#include<iostream>#include<vector>#include<cstdlib>#include<ctime>#include<cmath>// 模拟伙伴系统的内存块结构struct MemoryBlock { size_t size; // 块大小(2的幂次) size_t address; // 虚拟地址 bool is_used; // 是否被占用 MemoryBlock* next; // 链表指针 MemoryBlock(size_t s, size_t a) : size(s), address(a), is_used(false), next(nullptr) {}};// 模拟ARM32内核的vmalloc区(240MB)class VmallocArea {private: static const size_t TOTAL_SIZE = 240 * 1024 * 1024; // 240MB static const size_t MIN_BLOCK_SIZE = 4 * 1024; // 4KB最小块 std::vector<MemoryBlock*> free_lists; // 伙伴系统空闲链表(按2的幂次分类) size_t current_address; // 当前分配的虚拟地址 // 计算2的幂次大小 size_tround_up(size_t size){ if (size <= MIN_BLOCK_SIZE) return MIN_BLOCK_SIZE; size_t pow2 = 1; while (pow2 < size) pow2 <<= 1; return pow2; } // 获取空闲链表的索引 intget_list_index(size_t size){ return log2(size / MIN_BLOCK_SIZE); }public: VmallocArea() { // 初始化伙伴系统:创建最大块(240MB按2的幂次取128MB) size_t max_block_size = 128 * 1024 * 1024; int max_index = get_list_index(max_block_size); free_lists.resize(max_index + 1, nullptr); // 初始化第一个空闲块 MemoryBlock* root = new MemoryBlock(max_block_size, 0); free_lists[max_index] = root; current_address = max_block_size; } // 模拟vmalloc分配 void* vmalloc(size_t size){ size_t alloc_size = round_up(size); int index = get_list_index(alloc_size); // 查找可用的块 for (int i = index; i < free_lists.size(); ++i) { if (free_lists[i] != nullptr) { // 取出块 MemoryBlock* block = free_lists[i]; free_lists[i] = block->next; // 如果块大小大于需要的大小,拆分 while (block->size > alloc_size) { size_t half_size = block->size / 2; MemoryBlock* new_block = new MemoryBlock(half_size, block->address + half_size); int new_index = get_list_index(half_size); // 将新块加入空闲链表 new_block->next = free_lists[new_index]; free_lists[new_index] = new_block; block->size = half_size; } block->is_used = true; std::cout << "[vmalloc] 分配 " << alloc_size / 1024 << "KB 内存,地址: 0x" << std::hex << block->address << std::dec << std::endl; return (void*)(block->address); } } // 分配失败 std::cerr << "[vmalloc] 分配失败:内存碎片过多,无法找到 " << alloc_size / 1024 << "KB 连续块" << std::endl; return nullptr; } // 模拟vfree释放 voidvfree(void* ptr){ if (ptr == nullptr) return; size_t addr = (size_t)ptr; // 简化处理:找到对应的块(实际内核中通过页表查找) // 此处省略块查找逻辑,直接模拟释放后的碎片 std::cout << "[vfree] 释放内存,地址: 0x" << std::hex << addr << std::dec << std::endl; } // 模拟碎片率计算 floatget_fragmentation_rate(){ // 简化计算:统计已分配的小块数量占比 static int small_alloc_count = 0; static int total_alloc_count = 0; return (float)small_alloc_count / (total_alloc_count + 1) * 100; } ~VmallocArea() { // 释放所有块 for (auto& list : free_lists) { MemoryBlock* curr = list; while (curr != nullptr) { MemoryBlock* next = curr->next; delete curr; curr = next; } } }};// 模拟ARM32嵌入式设备的网络协议栈class NetworkStack {private: VmallocArea* vmalloc_area; std::vector<void*> buffers;public: NetworkStack(VmallocArea* va) : vmalloc_area(va) {} // 分配网络缓冲区(模拟频繁分配不同大小的内存) voidalloc_buffer(size_t size){ void* buf = vmalloc_area->vmalloc(size); if (buf != nullptr) { buffers.push_back(buf); } } // 释放部分缓冲区(模拟随机释放,加剧碎片) voidfree_random_buffers(int count){ for (int i = 0; i < count && !buffers.empty(); ++i) { int idx = rand() % buffers.size(); vmalloc_area->vfree(buffers[idx]); buffers.erase(buffers.begin() + idx); } } // 尝试分配大缓冲区(128KB) boolalloc_large_buffer(){ std::cout << "\n[NetworkStack] 尝试分配128KB连续内存..." << std::endl; void* buf = vmalloc_area->vmalloc(128 * 1024); if (buf == nullptr) { std::cerr << "[NetworkStack] 128KB内存分配失败,设备即将重启!" << std::endl; return false; } vmalloc_area->vfree(buf); return true; }};intmain(){ srand(time(nullptr)); VmallocArea vmalloc_area; NetworkStack net_stack(&vmalloc_area); // 模拟频繁分配释放网络缓冲区,产生碎片 std::cout << "===== ARM32设备运行:频繁分配网络缓冲区 =====" << std::endl; for (int i = 0; i < 1000; ++i) { // 随机分配4KB~64KB的缓冲区 size_t size = (rand() % 16 + 1) * 4 * 1024; net_stack.alloc_buffer(size); // 每10次分配释放2个缓冲区 if (i % 10 == 0) { net_stack.free_random_buffers(2); } } // 查看碎片率 std::cout << "\n[系统] 内存碎片率:" << net_stack.get_fragmentation_rate() << "%" << std::endl; // 尝试分配128KB大缓冲区(模拟故障场景) net_stack.alloc_large_buffer(); return 0;}
编译运行:
g++ -o mem_fragment mem_fragment.cpp -std=c++11./mem_fragment
运行后可模拟出ARM32设备中频繁动态分配导致的内存碎片问题,以及最终大内存分配失败的故障场景。
七、实战优化
7.1 预防优先:构建健壮的内存布局
(1)碎片控制三大原则
减少动态分配:优先使用栈空间(局部变量)或静态内存,避免频繁的malloc/free。例如实时系统的网络驱动,可预分配固定大小的接收缓冲区,避免动态分配产生碎片。
匹配分配释放作用域:函数申请的内存尽量在函数内释放,避免跨函数长期持有小块内存,防止内存长期占用无法回收。
对齐分配尺寸:按2的幂次申请内存(4KB、8KB、16KB),适配伙伴系统的合并机制,减少碎片产生。
(2)内核参数调校
/proc/sys/vm/max_map_count:限制单个进程的虚拟内存区域数量,防止用户态进程过度消耗地址空间。
vm.overcommit_memory=2:严格限制内存超额分配,避免内核动态映射区被无节制占用。
vm.swappiness=10:降低交换分区的使用频率,减少磁盘I/O对性能的影响(适用于内存充足的场景)。
7.2 动态监控:及时捕捉异常信号
(1)三大核心工具
slabtop:实时查看Slab分配器各对象缓存情况,定位异常增长的内核对象(如dentry、buffer_head),排查内存泄漏。
cat /proc/iomem:查看内核空间各区域的占用情况,识别模块加载区、固定映射区的地址冲突。
perf mem:追踪页错误和TLB失效,量化内存布局缺陷对性能的影响,例如频繁页错误可能是内存布局不合理导致。
(2)深度调试工具
ftrace:跟踪__alloc_pages调用栈,定位高频内存分配热点,优化分配策略。
crash:系统崩溃后分析mm_struct和page结构,查看页标志(脏页、不可回收页),定位崩溃原因。
KASAN:编译内核时启用,检测内存越界、使用后释放等错误,精准定位内核空间非法访问。
7.3 架构优化:复杂场景的进阶方案
(1)NUMA架构本地化分配
多处理器NUMA架构中,处理器访问本地内存的速度远快于远程内存。可通过以下方式优化:
例如数据库服务器的优化命令:
numactl --cpunodebind=0 --membind=0 ./mysql-server
(2)大页技术优化
采用2MB或1GB大页映射数据库缓冲区、Java堆等大块内存,可减少页表项数量,降低TLB压力,避免小块分配产生的碎片。例如Redis启用大页的配置步骤:
配置大页数量:
echo 1024 > /proc/sys/vm/nr_hugepages
绑定大页启动Redis:
numactl --cpunodebind=0 --membind=0 ./redis-server --hugepages /mnt/huge
实战中,Redis启用大页后,内存分配延迟可降低40%,碎片率从35%降至5%。
总结
Linux内核内存布局并非抽象的理论,而是与系统稳定性、业务性能直接相关的底层基础。搞懂各区域的作用、地址范围和访问规则,结合实战工具进行监控与调优,才能有效规避内存泄漏、碎片积累等问题,让系统在高压力下依然保持稳定高效的运行状态。从用户空间到内核空间,从地址转换到内存分配,每一个细节的优化,都能为系统的可靠性与性能带来质的提升。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
