号称“AI 写的 C 编译器能编 Linux 内核”很强?
- 2026-06-28 16:52:28
大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构!
关注、发送C1即可获取JetBrains全家桶激活工具和码!
前阵子,Anthropic 放了个大招:发布了一篇工程博客,宣称用 Claude 从零写出了一个 C 编译器,名叫 CCC(Claude’s C Compiler),并且“能编译 Linux 内核”。更刺激的是:代码 100% 由 Claude Opus 4.6 产出,人类只负责写测试用例和引导流程。
Building a C compiler with a team of parallel Claudes
这事儿听起来真是“赛博爽文”(也让小D惊出一身冷汗,要被替代了[惊恐]):AI 不仅会写业务代码,还能写编译器这种“硬核到发光”的东西?于是有人不信邪,直接拉出来和工业老大哥 GCC 正面 PK——不看营销,看数据。
CCC 源码在这里对比与基准测试仓库
前言:
先絮叨一个小知识:编译一个 C 程序到底发生了啥?
很多人一听“编译器”就以为只有一个工具在干活,其实典型链路是四段式:
预处理器(Preprocessor):处理 #include、#define等,把源码展开成“更长的源码”。编译器(Compiler):把 C 代码翻译成汇编,并做(可选的)优化。 汇编器(Assembler):把汇编变成目标文件(机器码)。 链接器(Linker):把多个目标文件拼成最终可执行文件,处理符号、重定位、段布局等“玄学细节”。
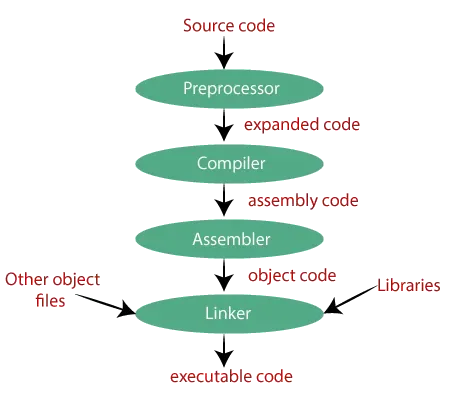
顺带一提:编译器这玩意儿为啥难?因为 GCC 从 1987 年开始迭代,接近 40 年、无数贡献者、无数坑位修复,优化策略堆得像“学术论文博物馆”。所以 CCC 能跑起来已经挺离谱,但想直接追平 GCC 的产出质量……那属于让新手上来打职业联赛,还要求“先拿个世界冠军”。
为什么说“编译器反而是四段里相对好做的”?
把 C 结构映射到汇编模式,很像规则匹配、模式翻译,AI 擅长。 汇编器要保证每一位指令编码都正确,尤其 x86-64 那种“指令形态多到脑壳痛”的架构,任何一个 bit 错了都可能当场起飞(向错误方向)。 链接器更是地狱难度:重定位、符号解析、TLS、PIC、动态链接、ELF 各种段和脚本指令……Linux 内核的 linker script 还长得像史诗。
所以“能编内核”这句话里,最可能出问题的其实不是“能不能解析 C”,而是能不能在链接阶段把 ELF、重定位和符号表整明白。
为啥拿 SQLite 做测试,而不是直接硬刚 Linux 内核?
因为 Linux 内核太变态了:GCC 扩展、内联汇编、奇奇怪怪的链接脚本、各种极限写法,属于编译器的“综合地狱副本”。 SQLite 则很适合当“现实但可控”的试金石:它有单文件 amalgamation(一个巨大的 .c),偏标准 C、测试成熟、闭环强。能把 SQLite 编对、跑对,说明基础能力很实在;跑不动 SQLite,就别碰内核这种深渊。
测试环境怎么搞?✅
测试者准备了两台 Debian 系 VM(同规格、同硬件条件),关键配置大概是:
2 台 VM,6 vCPU、16GB RAM、NVMe GCC:14.2.0 Kernel:Linux 6.9(x86_64 defconfig) SQLite:3.46.0 amalgamation 监控: /usr/bin/time -v+ 自定义采样 CPU/RSS
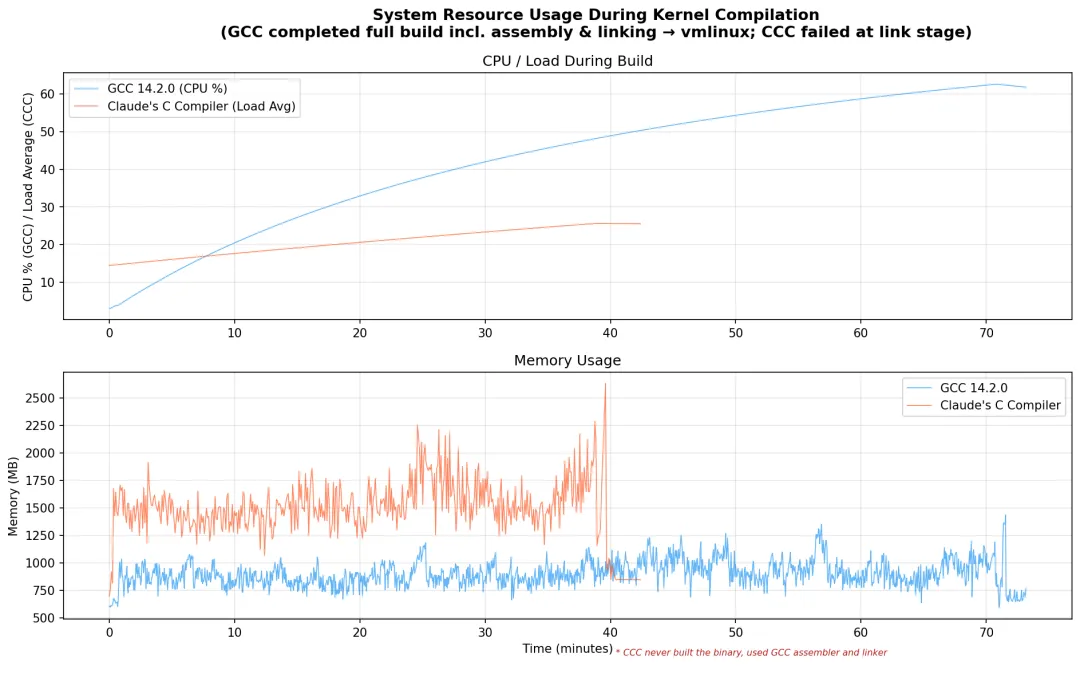
还有个很“务实”的补丁:CCC 对 16-bit real-mode 启动代码(-m16)搞不定,所以开启 gcc_m16 特性,把这段交给 GCC 处理;另外 .S 汇编文件也交给 GCC,CCC 专注编 .c。
结果来了:CCC 的“优点”很硬核,“缺点”也很致命 😅
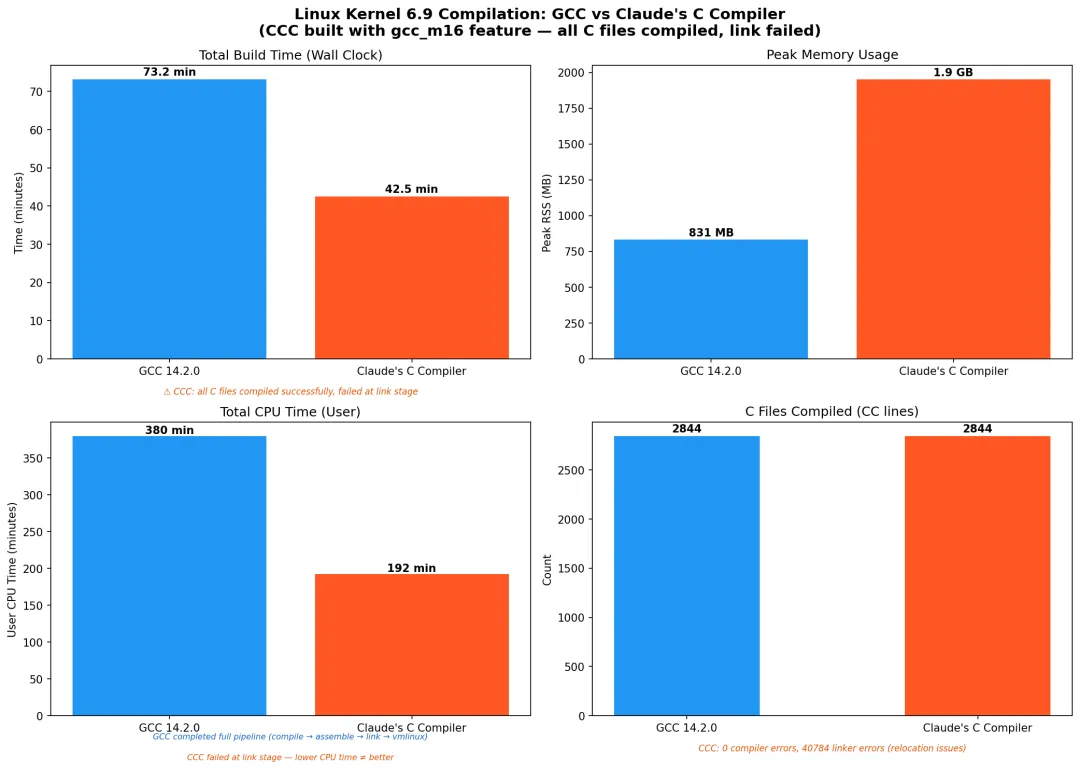
1)编 Linux 内核:C 文件能全过,但最终链接炸了
这部分属于“震撼但不意外”:
CCC 把 Linux 6.9 的 2,844 个 C 文件全部编译通过,0 个编译错误(只有警告)。这对于一个“AI 从零写的编译器”来说,确实很能打。 但最后在链接阶段,出现了 约 40,784 个 undefined reference,导致 vmlinux无法产出。
问题模式集中在两类:
__jump_table相关重定位不对(内核 jump labels / static keys 等机制很依赖它)__ksymtab相关符号表条目异常(模块导出符号那一套)
换句话说:编译器前端/中端没翻车,翻在“链接器与重定位/符号生成”这种细节地狱。这也刚好印证了“链接器是最难的那一段”。
2)编 SQLite:能编、能跑、结果还对,但速度直接“跑成天荒地老”🏃♂️💨
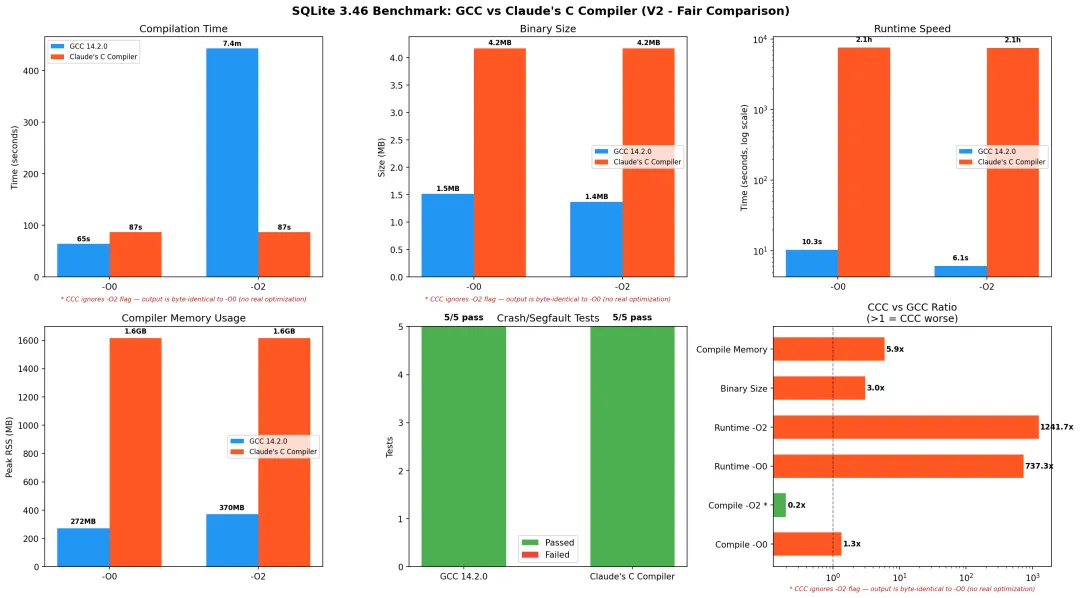
编译时间方面,公平比较只能看 -O0(因为 CCC 的 -O 基本是装饰品,后面会说):
GCC -O0:约 64.6sCCC:约 87.0s(大概慢 1.3倍) CCC 编译时峰值内存:约 1.6GB(GCC -O0约 272MB)
二进制体积更夸张:
GCC:约 1.4~1.55MB CCC:约 4.27MB(2.7~3.0倍 膨胀)
真正让人“笑不出来”的是运行性能:
SQLite 基准(GCC -O0)大概 10.3sSQLite 基准(GCC -O2)大概 6.1sSQLite 基准(CCC)直接跑到 2 小时 06 分钟……
没错,秒表变成了时钟,时钟变成了人生。😵💫
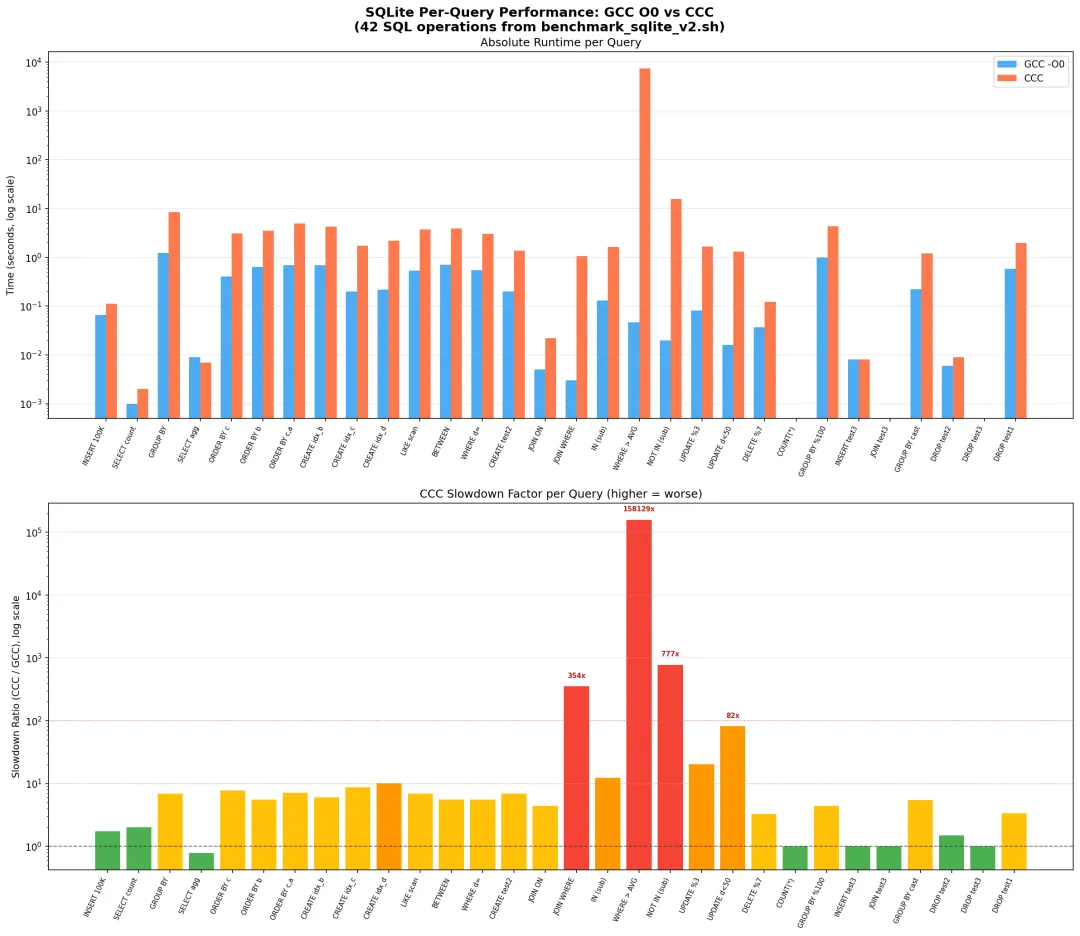
更有意思的是:CCC 的慢不是均匀慢。简单操作可能只慢 1~7 倍,但遇到 JOIN / 子查询这种“嵌套循环”结构,能慢到五位数、六位数倍。比如 NOT IN (subquery) 这种模式,某些查询直接慢出天际。
为啥 CCC 会慢成这样?核心不是“AI 不行”,而是“编译器后端太现实”🔧
1)寄存器分配太弱 → 大量 spill 到栈 → 每一步都在搬砖
SQLite 的执行引擎里有个超级大函数(局部变量多、switch 巨大),GCC 即便 -O0 也能相对克制地用寄存器/栈配合;CCC 则更像“只有一个小推车(某个寄存器)”,不停把数据从栈搬到寄存器,再从寄存器搬回栈,循环往复。
GCC 的风格:
movl -8(%rbp), %eax ; load loop counter
cmpl -36(%rbp), %eax ; compare against n
jl .L6 ; branch
movl(%rax), %edx ; load a[i] directly
cmpl %eax, %edx ; compare in registers
CCC 的风格:
movq -0x1580(%rbp), %rax ; load from deep stack offset
movq %rax, -0x2ae8(%rbp) ; store to another deep stack offset
movq -0x1588(%rbp), %rax ; load next value
movq %rax, -0x2af0(%rbp) ; store to next offset
; ... dozens more memory-to-memory copies
这种“内存 ↔ 寄存器 ↔ 内存”的搬运工模式,一旦进入 SQLite 那种高频循环,性能就会指数级爆炸。
2)CCC 的 -O2 基本不生效
非常直观的对比:-O0 和 -O2 生成的汇编/二进制基本没有差异。 这意味着 CCC 没有像 GCC 那样的多层级优化:指令选择、寄存器分配、循环优化、内联、DCE、向量化……这些“GCC 几十年家底”带来的东西,CCC 还没跟上。
3)调试体验也不友好:符号/栈帧链条等信息缺失或异常
这会导致 GDB 回溯像“迷雾森林”,定位问题很痛苦;同时也让 profiling 这类工作基本没法正常做。
“Hello World 都编不出来?”这梗还真不是段子😅
发布没多久就有人提了一个非常经典的 issue:README 的 hello world 在新环境直接失败,报系统头文件找不到(例如 stddef.h / stdarg.h)。 根因是 CCC 的预处理器没有正确搜到系统 include 路径——这些头往往来自编译器/工具链配置,而不是单纯 libc。
$ ./target/release/ccc -o hello hello.c
/usr/include/stdio.h:34:10: error: stddef.h: No such file or directory
/usr/include/stdio.h:37:10: error: stdarg.h: No such file or directory
ccc: error: 2preprocessor error(s) in hello.c
这事儿也说明:“能跑大工程”不代表“新手体验就丝滑”。工具链细节是生产级软件最容易被忽略、却最影响推广的部分。
最终结论:CCC 是“技术演示的成功”,但不是“生产可用的替代品”✅
从工程成就角度看,CCC 确实很惊艳:
能把 Linux 内核的大量 C 文件编过去(0 编译错误) SQLite 结果正确,稳定性测试也没翻车 命令行参数还努力兼容 GCC,想做 drop-in replacement 的姿势挺标准
但从“拿来干活”的角度看,它目前还差几个关键台阶:
链接器/重定位/符号表:内核级项目会把这些细节放大到灾难级 性能与优化:寄存器分配和优化层级不够,导致复杂 workload 直接爆炸 调试与可观测性:没有像样的符号、栈帧链条等信息,定位问题难 资源消耗:编译内存占用显著高于 GCC
结语
如果目标是证明“AI 能写出复杂软件体系”,CCC 很成功; 如果目标是“替代 GCC 编译并高性能运行”,那现在还远远不够。
代码世界里,真正的差距往往不在“能不能跑起来”,而在“能不能在极限场景稳定、可调试、可优化、可维护”。
就像平常我们写业务代码不能只对着正常场景来测试,因为你永远不知道用户或者攻击者会发出怎样不可思议的请求!!!
GCC/Clang 的优势,就是把这些“脏活累活”做了几十年。
话说回来,CCC 的出现至少证明了一件事:AI 写代码的上限,已经开始摸到“系统级基础设施”的边了。只是距离“工程师可以安心躺平”——还早得很。别急,先把 CI 过了再说🤣
喜欢就奖励一个“👍”和“在看”呗~

专属付费版全家桶
如果你只是激活JetBrains全家桶IDE,那这个应该是目前最经济、最实惠的方法了!
专属付费版全家桶除了支持IDE的正常激活外,还支持常用的付费插件和付费主题!
100%保障激活,100%稳定使用,100%售后兜底!
为什么说专属付费版全家桶最经济、最实惠?
因为专属付费版全家桶支持常用付费插件和付费主题。而任意一款或两款付费插件或付费主题,其激活费用就远高于我提供的专属付费版全家桶。
比如,最方便的彩虹括号符Rainbow Brackets,124/年。
再如,MyBatis最佳辅助框架MyBatisCodeHelperPro的官方版本MyBatisCodeHelperPro (Marketplace Edition),157/年。
还有最牛的Fast Request,集API调试工具 + API管理工具 + API搜索工具一体!157/年。
`专属付费版全家桶`包含上述这些付费插件,但不限于上述这些付费插件!
需要的小伙伴,可以扫码二维码,回复付费,了解优惠详情~

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- GESP Python 编程探索之路(二级)
- 50个Linux命令就可以吃透Linux系统吗?
- Linux 最新资讯 20260211——Linux 7.0 在UDP接收网络压力测试中性能提升 12%;Google Chrome 145 发布并支持 JPEG-XL 图像格式
- uv完全指南:从入门到精通的Python项目与依赖管理实战
- 3分钟学会使用Python音乐下载神器:musicdl完整指南
- 找疯了!终于凑齐 100 个 Python 常用语法,新手直接封神!
- 【开源】XSAST-Python:AI代码审计工具
- Python索引与切片
- 每天学习一点Python——掌握pathlib模块
- Python速成——print常用知识点
