Python爬虫技术实战:如何合规获取和风天气数据?
一、学前花絮
之前输出了几篇关于爬虫的文章,侧重于介绍python爬虫的技术实现。对于爬虫来说,我们一定要明确一个概念:不是所有网站都免费爬取信息!或者说,我们作为个人学习者,应该找那些没有法律风险的、免费使用的数据信息网站去练习。本文以和风天气举例,详细介绍如何合规使用python爬取天气数据。二、Python 爬取和风天气数据
2.1 网络爬虫的基础认知
1. 爬虫的定义
网络爬虫(Web Crawler)也被称为网络蜘蛛、网络机器人,是一种按照既定规则自动抓取互联网信息的程序 / 脚本。其核心原理是模拟浏览器向目标网站发送 HTTP/HTTPS 请求,获取网页 / 接口返回的数据后,进行解析、提取和存储,广泛应用于数据采集、搜索引擎索引、舆情分析等场景。2. 爬虫的合规规则(Robots 协议)
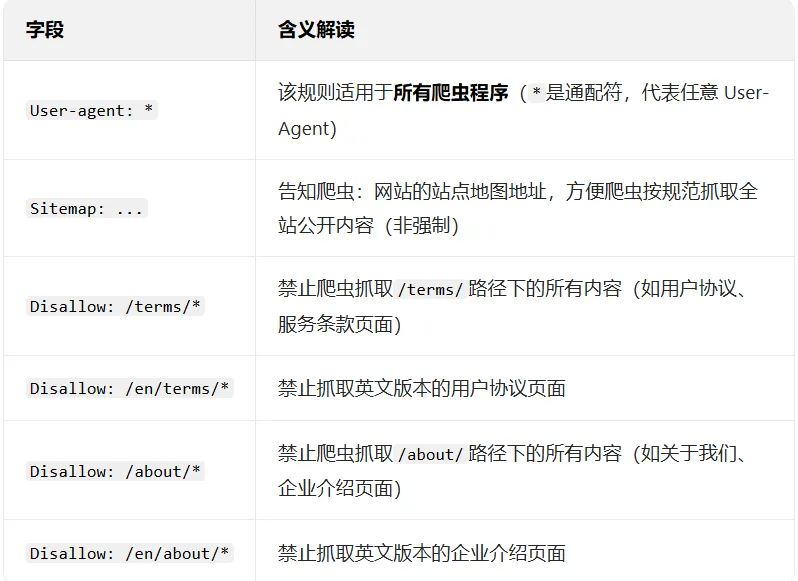
Robots 协议(也叫 robots.txt)是网站通过文本文件告知爬虫哪些内容可抓取、哪些不可抓取的约定,本质是 “君子协定”,虽无强制法律约束力,但却是爬虫合规的基础准则。示例:访问https://www.qweather.com/robots.txt可查看和风天气的 Robots 协议,确认其开放了 API 相关路径的抓取权限:Sitemap: https://www.qweather.com/sitemap_index.xml以上就是和风天气robots.txt文件内容,解释如下:除了/terms/、/about/及其英文版本路径外,网站其他公开路径均允许爬虫访问;核心的API 接口(如/v7/weather/)不在禁止列表中,且和风天气开发者平台明确开放 API 调用权限,因此通过官方 API 采集天气数据完全符合 Robots 协议。仅限制了 “用户协议”“关于我们” 等静态页面的抓取,这类页面本身无气象数据,对我们的天气爬虫无影响;禁止抓取的目的是保护网站的静态合规文档,避免被恶意爬取 / 篡改。3. 爬虫的法律风险
未经许可的爬虫行为可能触犯《网络安全法》《反不正当竞争法》等法律法规,核心风险点包括:l高频请求导致目标服务器瘫痪(涉嫌 “破坏计算机信息系统罪”);l抓取个人信息(如用户手机号、身份证等),涉嫌侵犯公民个人信息权。2.2 免费开源数据与合规采集
1.免费开源数据的定义
l免费开源数据指由平台 / 机构主动开放、允许非商用 / 商用使用的公开数据,通常以 API 接口、数据集下载等形式提供,这类数据的采集无需额外授权,是爬虫学习的最佳实践场景:l特点:有明确的使用规范、接口文档,数据获取方式标准化,无法律风险;l常见场景:气象数据、公共交通数据、政府公开数据等。2.和风天气数据的合规性
和风天气(QWeather)是国内正规的气象数据服务平台,其提供的免费版 API完全符合合规采集要求:l合法性:数据来源为官方气象机构,平台具备合法的数据分发资质;l免费性:个人开发者版 API 提供每日一定额度的免费调用次数,满足学习 / 小型项目需求;l无风险:通过平台注册后获取合法凭证调用 API,而非爬取非公开页面,完全规避法律风险。2.3 和风天气平台注册与开发凭证获取
1. 注册流程(简要)
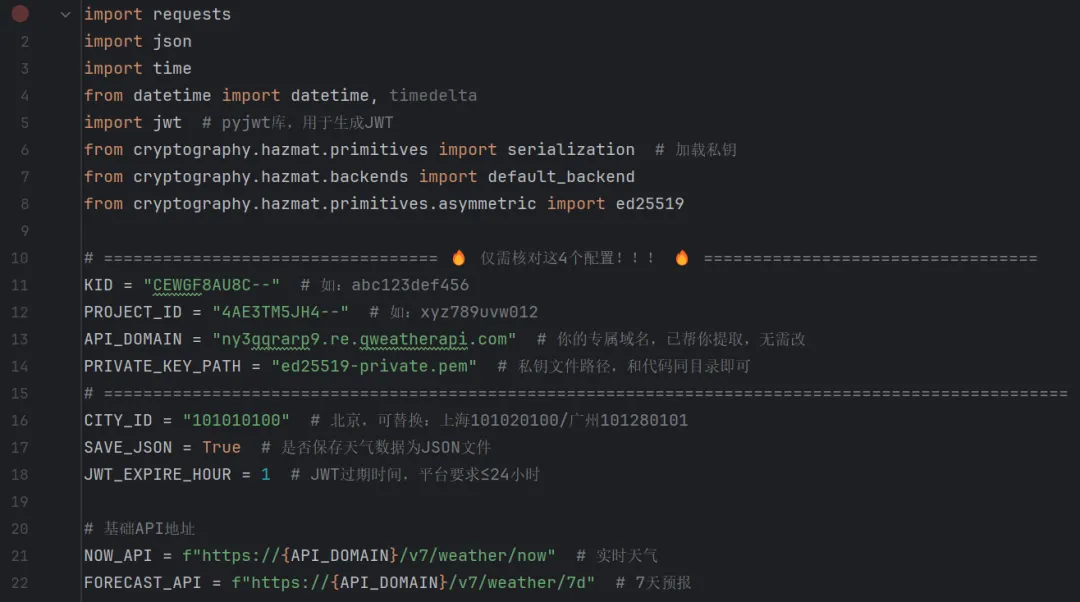
①访问和风天气开发者平台:https://dev.qweather.com/;③进入 “控制台 - 项目管理”,点击 “创建项目”,选择 “个人版”(免费);④项目创建后,在 “配置管理” 中开启 “天气 API” 权限(实时天气、7 天预报等)。2.获取 4 个核心开发凭证
创建项目后,在项目详情页提取以下 4 个关键信息(爬虫开发必备):补充:ED25519 私钥需手动下载(项目详情页→“认证配置”→“生成 / 下载私钥”),保存为ed25519-private.pem文件,与 Python 代码放在同一目录。2.4 Python 爬取和风天气数据示例程序
1.环境准备
pip install requests pyjwt cryptography |
2.python示例代码
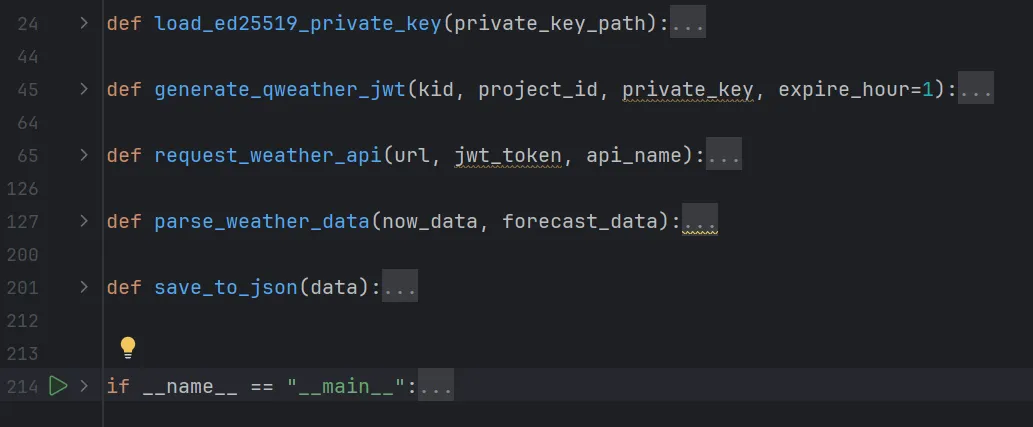
3.代码说明
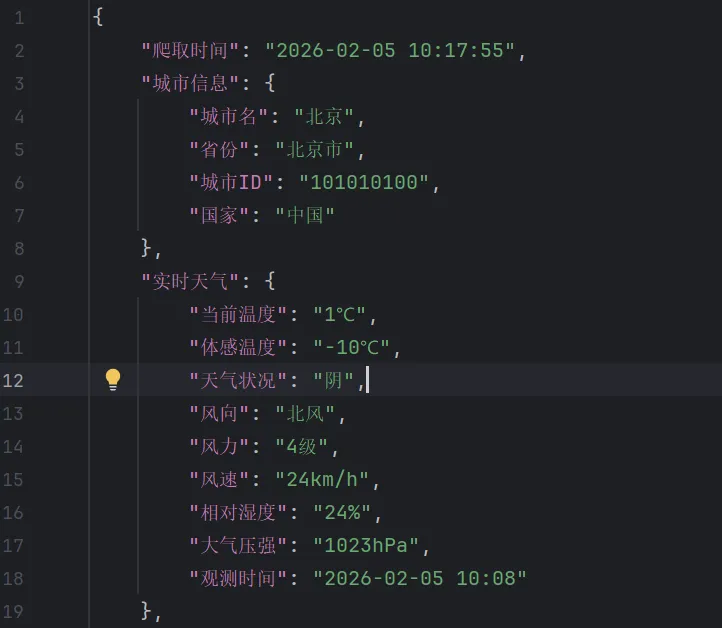
①核心流程:私钥加载 → JWT 令牌生成 → API 请求 → 数据解析 → 保存文件;l移除lang参数,避免 400 参数错误(和风天气免费版默认返回简体中文);l使用dict.get()替代直接取值,避免 KeyError,提升代码健壮性;l严格遵循和风天气 JWT 认证规范,确保请求合法;l替换代码中 4 个核心凭证为自己的信息,否则无法运行;l私钥文件需与代码放在同一目录,命名为ed25519-private.pem;l免费版 API 有每日调用次数限制,避免高频请求。2.5 以上内容的总结
1.爬虫开发的核心是 “合规”:优先遵循 Robots 协议,选择官方开放的 API 而非爬取非公开页面,可完全规避法律风险;2.和风天气是学习爬虫的优质场景:免费、合规、文档完善,其 JWT 认证机制也是企业级 API 调用的典型实践;3.代码设计需注重健壮性:处理参数错误、字段缺失等异常,确保程序稳定运行。本示例仅用于学习目的,请勿将采集的数据用于商用,如需商用请联系和风天气开通商业版权限。三、小结
对于python的爬虫技术,我们在学习的时候一定要注意合规性。所谓的合规,本质上是对知识产权及商业价值的保护,比如很多网站就是靠信息数据获取商业价值,那么人家肯定会对不劳而获的爬取信息予以谴责。也正因如此,为了个人学习的方便,也有很多可以供开发者免费使用的数据信息网站,比如本文提到的和风天气。让我们保持学习热情,多做练习。我们下期再见!


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
