其实原本写了一些通信信道仿真的内容,但ToolBox出了点问题,除夕辞旧迎新把原本的卸载了,但新的又有问题没装上(北太天元暂缓)。故改用Python.这一系列的内容编排是基于阅读刘海英老师的《数字音频处理教程》的第三章和第五章。之前24年读了一遍,这次挑出一些可以编程实操的内容撰写文章。看似是音频处理,其实还是DSP那一套,只是推广到了音频处理领域。在数字信号处理(DSP)课本里,我们学过很多看起来很“抽象”的东西:采样、量化、滤波、频谱分析、线性预测、随机过程……我们日常用的很多音频编码方法,其实就是把这些 DSP 工具按需拼装起来,变成一个可以“压缩”声音的系统。这一类编码有很多种,其中在尽量少占用比特率的前提下,让重建出来的声音波形,尽量长得和原始波形一模一样。叫做 波形编码(waveform coding)。我希望用几组 Python 小实验,讨论三种压缩方式PCM、µ-law和DPCM,顺便讨论一下如何比较压缩前后音质的差异。为了简单直观,我选的是一小段弦乐声音(其实是从老师学习通资料里下载的),并且转换为单声道,把幅度归一化到 [-1, 1] 的范围。
接下来,我们对这同一段语音,分别做三类波形压缩操作:
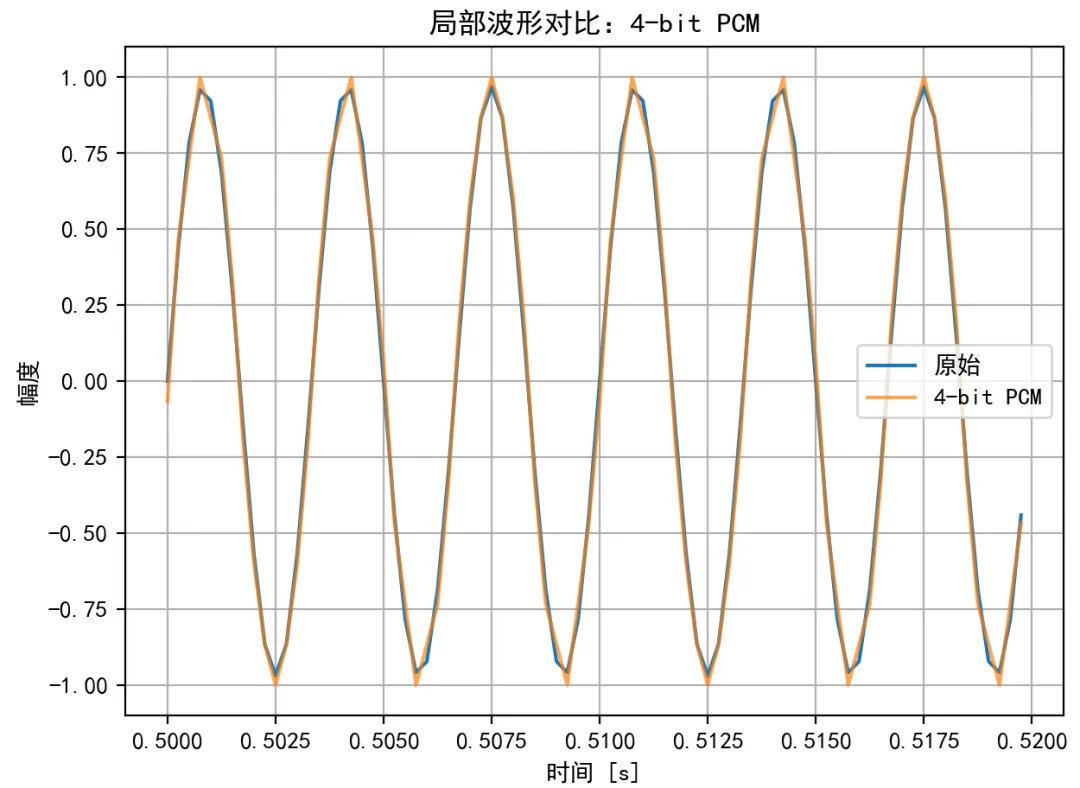
用最普通的 PCM 量化,先用足够高的采样率把连续时间的声音变成离散采样点。比如 16 kHz 或 44.1 kHz,这部分满足奈奎斯特定律就不展开了。再把每一个采样点的幅度,从连续值变成有限个等级。局部波形对比如下:
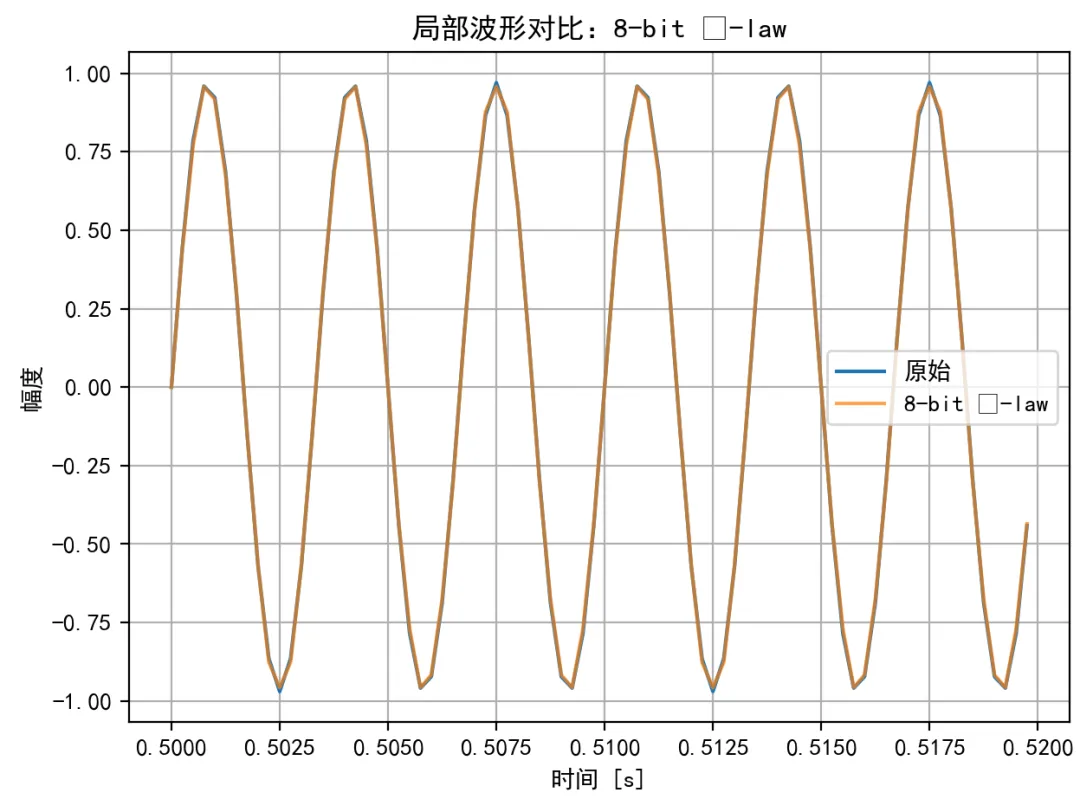
换成 µ-law 非线性压缩再量化,把靠近 0 的小幅度放大,把大的幅度缩小,整体再做一次均匀量化。波形结果如下:
小结一下,我们从采样定理、量化噪声理论出发,是最朴素的PCM;考虑信号的统计分布和人耳对小信号更敏感的特点,发展出了µ-law/A-law 这类非均匀量化。但这个音频貌似效果不太显著,我再找找有没有其他音频的资料。