Python scrapy模块详细介绍
- 2026-06-30 14:43:26
1. 创始时间与作者
创始时间:Scrapy 项目最初由 Pablo Hoffman 和 Shane Evans 创建,最早发布于 2008年。最初它是作为一个专门用于网站抓取的内部工具而开发的,后来在 2010 年正式开源并发布了 0.7 版本。它是最早的现代 Python 爬虫框架之一。
核心开发者:
Pablo Hoffman:阿根廷软件工程师,Scrapy 的联合创始人和核心架构师。
Shane Evans:Scrapy 的联合创始人。
Ismael Carnales:早期核心贡献者之一。
Scrapy 团队:项目目前由 Zyte(原 Scrapinghub)公司的团队和开源社区共同维护,拥有超过 300 名贡献者。
项目定位:一个用于大规模网页抓取的快速、高层次的 Python 框架。它提供了一套完整的机制,用于定义抓取规则、提取结构化数据、处理请求和响应,并支持中间件、管道、扩展等功能,旨在简化并加速爬虫的开发与部署。
2. 官方资源
GitHub 地址:https://github.com/scrapy/scrapy
官方网站:https://scrapy.org/
官方文档:https://docs.scrapy.org/
PyPI 地址:https://pypi.org/project/Scrapy/
3. 核心功能

4. 应用场景
1. 通用网页抓取与数据提取
# quotes_spider.pyimport scrapyclass QuotesSpider(scrapy.Spider):name = "quotes"start_urls = ['https://quotes.toscrape.com/page/1/','https://quotes.toscrape.com/page/2/', ]def parse(self, response):# 提取当前页面的名言for quote in response.css('div.quote'):yield {'text': quote.css('span.text::text').get(),'author': quote.css('small.author::text').get(),'tags': quote.css('div.tags a.tag::text').getall(), }# 提取下一页链接并继续爬取next_page = response.css('li.next a::attr(href)').get()if next_page is not None:yield response.follow(next_page, callback=self.parse)
2. 大型电商网站商品信息抓取
# products_spider.pyimport scrapyfrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Ruleclass ProductsSpider(CrawlSpider):name = 'products'allowed_domains = ['example-store.com']start_urls = ['https://www.example-store.com/products/']# 定义爬取规则rules = (# 提取所有商品详情页链接Rule(LinkExtractor(allow=r'/item/[\w-]+$'), callback='parse_item'),# 提取下一页链接,继续跟进Rule(LinkExtractor(allow=r'/products/\?page=\d+$'), follow=True), )def parse_item(self, response):yield {'name': response.css('h1.product-title::text').get(),'price': response.css('span.price::text').get(),'description': response.css('div.description::text').get(),'sku': response.css('span.sku::text').get(),'url': response.url,'image_urls': response.css('img.product-image::attr(src)').getall(), }
3. 登录后抓取(处理 Cookies 和 Session)
# login_spider.pyimport scrapyclass LoginSpider(scrapy.Spider):name = 'login'login_url = 'https://example.com/login'start_urls = ['https://example.com/secure/dashboard']def parse(self, response):# 检查是否已登录(通过页面特征判断)if "登录" in response.text:# 未登录,提取登录表单的 CSRF tokentoken = response.css('input[name="csrf_token"]::attr(value)').get()yield scrapy.FormRequest(url=self.login_url,formdata={'username': 'myuser','password': 'mypassword','csrf_token': token, },callback=self.after_login )else:# 已登录,直接处理页面yield from self.parse_dashboard(response)def after_login(self, response):# 登录成功后,继续访问目标页面if "登录成功" in response.text:yield scrapy.Request(self.start_urls[0], callback=self.parse_dashboard)else:self.logger.error("登录失败")def parse_dashboard(self, response):# 处理登录后的页面for row in response.css('table.data tr'):yield {'id': row.css('td.id::text').get(),'value': row.css('td.value::text').get(), }
4. 使用 Pipeline 将数据存入数据库
# pipelines.pyimport sqlite3class SQLitePipeline:"""将抓取的数据存入 SQLite 数据库"""def open_spider(self, spider):"""爬虫启动时打开数据库连接"""self.connection = sqlite3.connect('data.db')self.cursor = self.connection.cursor()self.cursor.execute(''' CREATE TABLE IF NOT EXISTS quotes ( id INTEGER PRIMARY KEY AUTOINCREMENT, text TEXT, author TEXT, tags TEXT ) ''')self.connection.commit()def process_item(self, item, spider):"""处理每个 item,插入数据库"""self.cursor.execute('INSERT INTO quotes (text, author, tags) VALUES (?, ?, ?)', (item['text'], item['author'], ','.join(item['tags'])) )self.connection.commit()return itemdef close_spider(self, spider):"""爬虫关闭时关闭连接"""self.connection.close()
5. 底层逻辑与技术原理
核心架构
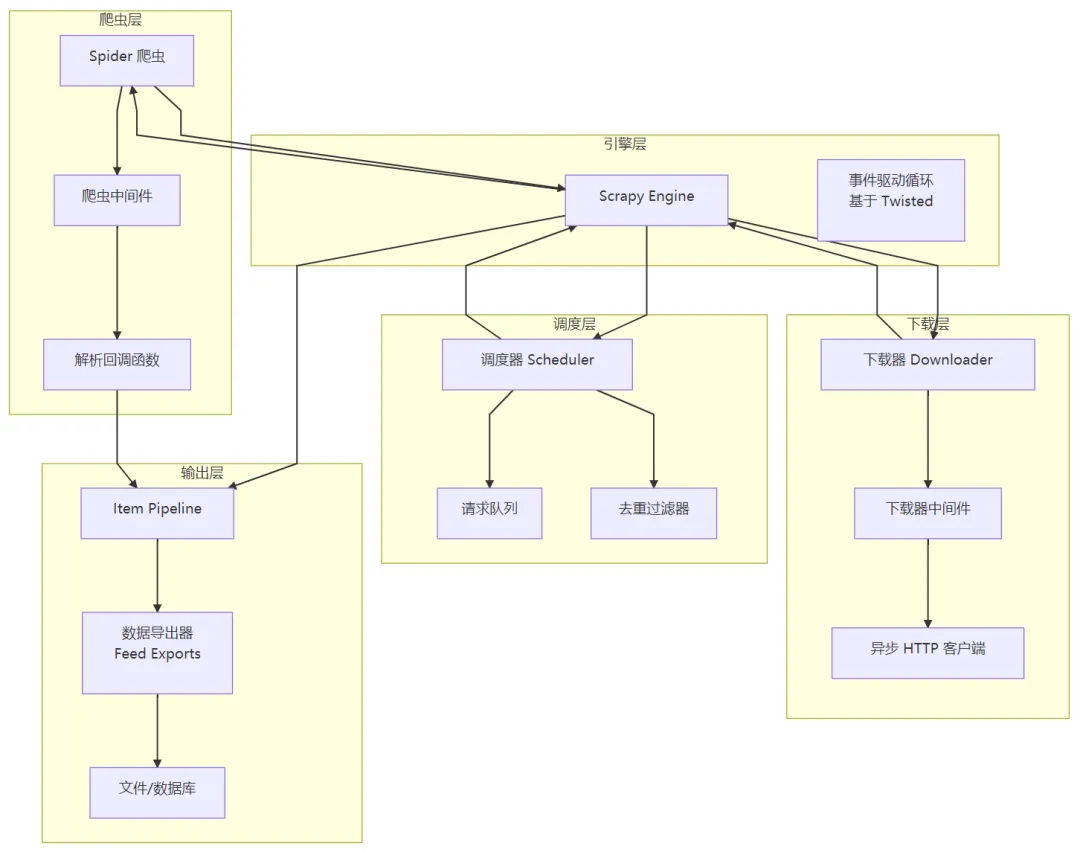
关键技术
基于 Twisted 的异步网络框架:
Scrapy 的核心是一个由 Twisted 驱动的事件循环,允许在等待网络响应时处理其他请求,从而实现高并发。
无需编写多线程代码即可获得高性能。
请求/响应模型:
爬虫生成
Request对象,引擎将其传递给调度器。调度器按优先级出队,交给下载器执行。
下载器返回
Response对象,引擎将其送回对应的爬虫回调函数。中间件机制:
下载器中间件:在请求发送前或响应返回后进行处理(如添加 Headers、处理代理、重试等)。
爬虫中间件:在爬虫处理响应前后或生成 Item 前后进行干预。
这种设计使得功能扩展非常灵活。
选择器系统:
内置基于
lxml的高效选择器,支持 CSS 和 XPath。可选择性地使用
parsel库(从 Scrapy 中分离出的选择器库)。Item Pipeline:
爬虫提取的数据(Item)会流经一系列管道组件。
每个组件可以对数据进行清洗、验证、去重,并最终存入数据库或文件。
扩展和统计收集:
提供 API 让开发者编写自定义扩展,监控或修改爬虫行为。
内置统计收集器,可记录请求次数、响应码、Item 数量等。
6. 安装与配置
基础安装
# 使用 pip 安装pip install scrapy# 验证安装scrapy version
创建新项目
# 创建一个新的 Scrapy 项目scrapy startproject myprojectcd myproject
环境要求
| 组件 | 最低要求 | 推荐配置 |
|---|---|---|
| Python | 3.8+ | 3.10+ |
| 操作系统 | Windows, macOS, Linux | Linux(生产环境最佳) |
| 依赖库 | Twisted, lxml, pyOpenSSL, cryptography | - |
| 内存 | 256MB | 1GB+(取决于并发量) |
可选依赖
# 安装用于处理图片的 Pillowpip install Pillow# 安装用于代理支持的模块pip install scrapy-rotating-proxies# 安装用于分布式爬虫的模块pip install scrapy-redis
7. 性能指标
| 配置/场景 | 请求速率 | 内存占用 | CPU 使用 |
|---|---|---|---|
| 单机默认配置 | 50-200 请求/秒 | 100-300MB | 1-2 核 30-50% |
| 优化并发 (CONCURRENT_REQUESTS=100) | 500-1000 请求/秒 | 500MB-1GB | 多核 70-90% |
| 使用代理池 | 受代理速度限制 | 较高 | 中等 |
| 处理大文件下载 | 较低 | 较高(文件缓冲) | 中等 |
优化建议:
调整
CONCURRENT_REQUESTS和DOWNLOAD_DELAY平衡速度与礼貌性。使用
AutoThrottle扩展自动调整下载延迟。启用
HTTPCACHE避免重复请求。对于大规模抓取,考虑使用
scrapy-redis实现分布式。
8. 高级功能使用
1. 使用代理中间件
# middlewares.pyimport randomclass RandomProxyMiddleware:"""随机代理中间件"""def __init__(self, proxy_list):self.proxies = proxy_list@classmethoddef from_crawler(cls, crawler):proxy_list = crawler.settings.get('PROXY_LIST')return cls(proxy_list)def process_request(self, request, spider):proxy = random.choice(self.proxies)request.meta['proxy'] = proxyspider.logger.debug(f"使用代理: {proxy}")# settings.pyPROXY_LIST = ['http://proxy1.example.com:8080','http://proxy2.example.com:8080',]DOWNLOADER_MIDDLEWARES = {'myproject.middlewares.RandomProxyMiddleware': 543,}
2. 处理 JavaScript 渲染的页面
# 使用 Splash 或 Selenium 集成# 安装 scrapy-splashpip install scrapy-splash# settings.py 配置SPLASH_URL = 'http://localhost:8050'DOWNLOADER_MIDDLEWARES = {'scrapy_splash.SplashCookiesMiddleware': 723,'scrapy_splash.SplashMiddleware': 725,'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,}SPIDER_MIDDLEWARES = {'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,}DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'# spider 中使用import scrapyfrom scrapy_splash import SplashRequestclass JSSpider(scrapy.Spider):name = 'js_spider'def start_requests(self):yield SplashRequest(url='https://example.com',callback=self.parse,args={'wait': 2} # 等待2秒让JS执行 )def parse(self, response):# 现在可以提取由 JS 动态生成的内容yield {'dynamic_content': response.css('#js-generated::text').get(), }
3. 分布式爬虫(使用 Redis)
# 安装 scrapy-redispip install scrapy-redis# settings.pySCHEDULER = "scrapy_redis.scheduler.Scheduler"DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"REDIS_URL = 'redis://localhost:6379'# 爬虫类继承 RedisSpiderfrom scrapy_redis.spiders import RedisSpiderclass MyRedisSpider(RedisSpider):name = 'myspider_redis'redis_key = 'myspider:start_urls'def parse(self, response):# 处理逻辑pass# 在 Redis 中添加起始 URL# redis-cli> lpush myspider:start_urls https://example.com
4. 动态修改爬取规则(爬虫运行时)
import scrapyfrom scrapy.http import Requestclass DynamicSpider(scrapy.Spider):name = 'dynamic'def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)self.allowed_domains = kwargs.get('domains', '').split(',')self.start_urls = kwargs.get('urls', '').split(',')self.rules = kwargs.get('rules', '')def start_requests(self):for url in self.start_urls:yield Request(url, callback=self.parse_generic)def parse_generic(self, response):# 根据传入的规则动态提取if 'title' in self.rules:yield {'title': response.css('title::text').get()}if 'links' in self.rules:for link in response.css('a::attr(href)').getall():yield {'link': response.urljoin(link)}# 启动时传入参数# scrapy crawl dynamic -a domains=example.com -a urls=https://example.com/page1,https://example.com/page2 -a rules=title,links
9. 与同类工具对比
| 特性 | Scrapy | BeautifulSoup + Requests | Selenium | PySpider | Colly (Go) |
|---|---|---|---|---|---|
| 类型 | 完整框架 | 库组合 | 浏览器自动化 | 分布式框架 | Go 爬虫框架 |
| 并发 | 异步高并发 | 同步(可加线程) | 同步 | 异步 | 高并发 |
| JavaScript支持 | 需集成 Splash/Selenium | 需额外工具 | 原生支持 | 需 PhantomJS | 需集成 |
| 学习曲线 | 中等 | 平缓 | 中等 | 中等 | 陡峭 |
| 扩展性 | 极高(中间件/管道) | 需自行实现 | 低 | 高 | 中等 |
| 分布式 | 通过扩展实现 | ❌ | ❌ | ✅ | ✅ |
| 适用场景 | 大规模结构化数据抓取 | 小型项目、一次性抓取 | 动态页面测试/抓取 | 中型分布式 | 高性能 Go 项目 |
10. 企业级应用案例
电商价格监控:
知名比价网站如 PriceRunner、Shopzilla 使用 Scrapy 定期抓取竞争对手的商品价格。
淘宝/京东的第三方数据分析工具利用 Scrapy 采集商品信息和用户评价。
新闻聚合与舆情分析:
新闻网站如 BuzzFeed 使用 Scrapy 抓取社交媒体内容进行趋势分析。
舆情监测公司部署数千个 Scrapy 爬虫实时监控新闻和论坛。
搜索引擎数据源:
Common Crawl 项目使用 Scrapy 抓取海量网页数据,构建公开数据集。
垂直搜索引擎(如法律文书搜索)使用 Scrapy 抓取专业网站内容。
学术研究与数据科学:
研究人员使用 Scrapy 采集 Twitter、Reddit 等平台数据用于自然语言处理研究。
经济学者抓取房产网站数据建立价格模型。
总结
Scrapy 是 Python 生态中最强大、最成熟的大规模网页抓取框架,核心价值在于:
一站式解决方案:从请求调度、数据提取到存储输出,提供完整闭环。
异步高性能:基于 Twisted 的非阻塞 I/O,轻松实现每秒数百请求。
极强扩展性:中间件、管道、扩展机制让开发者可以定制任意环节。
社区与生态:拥有丰富的插件(如 scrapy-splash, scrapy-redis)和详尽的文档。
技术亮点:
事件驱动架构:无需多线程即可高效利用网络资源。
选择器与 Item 系统:分离数据提取与数据处理逻辑。
内置去重与调度:自动处理 URL 去重和请求优先级。
统计与监控:提供实时统计信息,便于调优。
适用场景:
大规模数据采集:电商、新闻、社交媒体内容抓取。
定期增量抓取:价格监控、舆情监测。
数据迁移与备份:将网站内容转为结构化数据。
学术研究:获取特定领域的数据集。
何时可能不适用:
小型一次性抓取任务:Scrapy 的项目结构可能显得过重。
强依赖 JavaScript 的单页应用:需要额外集成浏览器渲染工具。
需要实时响应的交互式爬虫(如测试自动化)。
安装使用:
pip install scrapyscrapy startproject myprojectcd myprojectscrapy crawl myspider
学习资源:
官方教程:https://docs.scrapy.org/en/latest/intro/tutorial.html
Scrapy 实战:https://www.zyte.com/blog/
中文社区:https://scrapy-chs.readthedocs.io/
截至 2024 年,Scrapy 在 GitHub 收获 53k+ Star,月下载量超 数百万次,是 Python 数据采集领域的工业级标准。项目遵循 BSD 开源协议,可免费用于商业和非商业项目。

