Linux与外部设备(磁盘、网卡等)是如何高效的进行数据交互的?
- 2026-07-05 01:23:48

大家好,我是情报小哥~
Linux I/O 是操作系统与外部设备(磁盘、网卡等)进行数据交互的核心机制,其性能直接决定系统整体吞吐量与响应速度。那么今小哥将围绕 Linux I/O展开聊聊:
一、传统 System Call I/O
传统 System Call I/O 是 Linux 最基础、最通用的 I/O 模式,适用于绝大多数简单 I/O 场景(如普通文件读写),其核心特征是通过系统调用触发内核态与用户态的交互,完成数据传输。
1. 核心调用
通过 read()/write() 系统调用完成核心数据交互,此外 open()(打开文件描述符)、close()(关闭文件描述符)、lseek()(调整读写偏移)等系统调用辅助完成 I/O 操作,构成完整的 I/O 调用链路。
2. 总开销
传统 System Call I/O 的性能瓶颈主要源于较高的传输开销,其总开销可概括为:4次数据拷贝(2次CPU拷贝+2次DMA拷贝)+4次上下文切换。该开销直接决定了其在高并发、大数据量场景下的性能局限性。
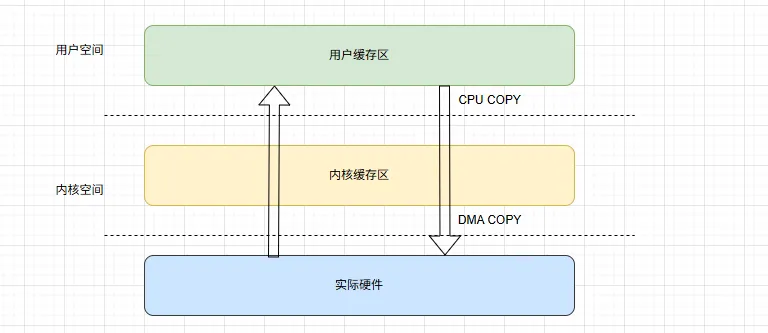
3. 关键概念
CPU拷贝:由CPU直接负责数据的读取与写入,数据从一个内存区域(如内核缓冲区)直接传输至另一个内存区域(如用户缓冲区),此过程会占用CPU计算资源,影响系统并发处理能力。
DMA拷贝:Direct Memory Access(直接内存访问)拷贝,CPU仅需向DMA控制器发送数据传输指令,后续数据传输(如磁盘→内核缓冲区、内核缓冲区→网卡)由DMA控制器独立完成,无需CPU参与,可显著降低CPU负载。
上下文切换:系统调用触发的用户态↔内核态切换。每次
read()或write()调用,都会从用户态切换至内核态(内核执行数据读取/写入逻辑),完成后再切换回用户态(用户程序继续执行),单次系统调用触发2次上下文切换,4次切换对应2次系统调用(如读+写)的完整流程。
二、传统I/O 读/写操作流程与开销
传统 I/O 的读、写操作流程遵循固定链路,不同场景(磁盘、网络)的流程核心一致,仅数据的起始/终点不同,以下详细拆解读、写操作的完整流程及对应开销。
1. 读操作(以磁盘读为例)
流程拆解:用户程序在用户态调用
read()系统调用 → 触发上下文切换(用户态→内核态)→ 内核发起磁盘读请求,由DMA控制器将磁盘数据读取至内核Read Buffer(内核缓冲区)→ CPU将内核Read Buffer中的数据拷贝至用户态Buffer(用户程序可访问的缓冲区)→ 触发上下文切换(内核态→用户态),用户程序获取数据并继续执行。核心开销:2次上下文切换(用户态↔内核态各1次)、1次DMA拷贝(磁盘→内核Read Buffer)、1次CPU拷贝(内核Read Buffer→用户态Buffer)。
补充逻辑:数据读取时会优先检查用户页内存(用户态缓存),若数据已命中用户页内存,则直接读取;若未命中,则先将数据从磁盘加载至内核缓存(内核Read Buffer),再通过CPU拷贝至用户态Buffer。
2. 写操作(以网络写为例)
流程拆解:用户程序在用户态调用
write()系统调用 → 触发上下文切换(用户态→内核态)→ CPU将用户态Buffer中的数据拷贝至内核Socket Buffer(网络场景专用内核缓冲区)→ DMA控制器将内核Socket Buffer中的数据拷贝至网卡NIC(网络接口控制器),由网卡发送至网络 → 触发上下文切换(内核态→用户态),用户程序完成写操作。核心开销:2次上下文切换(用户态↔内核态各1次)、1次CPU拷贝(用户态Buffer→内核Socket Buffer)、1次DMA拷贝(内核Socket Buffer→网卡NIC)。
3. 网络I/O与磁盘I/O的共性与差异
两者均基于传统 read()/write() 系统调用流程,核心链路、开销计算完全一致,唯一差异在于数据的最终终点不同:
网络I/O:数据最终传输至网卡,用于网络通信(如TCP/UDP数据发送);
磁盘I/O:数据最终传输至磁盘(写操作)或从磁盘读取(读操作),用于文件存储。
三、高性能I/O优化技术
传统I/O的高开销(CPU拷贝、上下文切换)限制了系统在高并发、大数据量场景下的性能,因此Linux提供了多种高性能I/O优化技术,核心目标是减少不必要的开销、提升I/O吞吐量。
1. 零拷贝(Zero-Copy)
核心目标是减少数据的CPU拷贝次数(无需完全消除拷贝,重点消除冗余的CPU拷贝),通过内核优化,让数据直接从内核缓冲区传输至目标设备(如网卡),跳过用户态与内核态之间的CPU拷贝。常见实现方式包括 sendfile()、mmap()(间接实现零拷贝)等,适用于大数据量传输场景(如文件服务器、视频流传输)。
2. 多路复用(I/O Multiplexing)
核心目标是用单线程(或少量线程)处理多个I/O连接,避免为每个I/O连接创建独立线程(减少线程切换开销)。通过内核提供的复用机制(如 select()、poll()、epoll()),监听多个I/O文件描述符,当某个文件描述符就绪(有数据可读/可写)时,再触发对应的I/O操作。其中 epoll() 是Linux主流复用机制,适用于高并发网络场景(如Web服务器)。
3. 页缓存(PageCache)
页缓存是Linux内核提供的文件缓存机制,核心作用是减少磁盘I/O次数,提升数据读取效率,其核心细节如下:
定位:属于操作系统层面的文件缓存,以页(Page)为单位(Linux默认页大小为4KB),缓存磁盘文件的内容,存储在内核空间。
读策略:数据读取时,优先查询PageCache,若数据命中(缓存中有对应数据),则直接从PageCache读取,无需访问磁盘;若未命中,则从磁盘读取数据,并预读后续若干页的数据存入PageCache,为后续读取操作提速。
写策略:数据写入时,并非直接写入磁盘,而是先写入PageCache,并将对应的页标记为脏页(缓存数据与磁盘数据不一致),再由内核的
flusher线程异步将脏页数据回写至磁盘,平衡写性能与数据安全性。脏页回写触发条件:当系统空闲内存不足(无法分配新的页缓存)、脏页存在时间超时(避免数据长期驻留缓存导致丢失)、用户主动调用
sync()(同步所有脏页)或fsync()(同步指定文件的脏页)时,触发脏页回写。
四、Linux 存储设备I/O栈(三层结构)
Linux 存储设备的I/O传输并非直接由应用程序对接硬件设备,而是通过分层架构(I/O栈)实现数据的层层传递与处理,确保I/O操作的标准化、可扩展,整体分为三层,从上层到下层依次为:
1. 文件系统层(FileSystem Layer)
I/O栈的最上层,对接应用程序,负责文件的组织与管理(如文件权限、目录结构、文件格式)。应用程序的I/O请求(如 read()/write())首先到达该层,该层将数据拷贝至自身的文件系统Cache(与PageCache关联),再将处理后的I/O请求向下传递至块层。
2. 块层(Block Layer)
I/O栈的中间层,是连接文件系统层与设备层的核心。该层以“块”为单位处理I/O请求,核心功能包括:管理I/O请求队列、对多个I/O请求进行合并(将多个连续的小请求合并为一个大请求,减少硬件交互次数)、排序(按磁盘扇区顺序排序请求,优化磁盘寻道时间,即I/O调度),最终将优化后的I/O请求传递至设备层。
3. 设备层(Device Layer)
I/O栈的最下层,对接存储硬件设备(如磁盘、SSD)。该层通过设备驱动程序与硬件设备通信,接收块层传递的I/O请求,通过DMA控制器完成设备与内存(内核缓冲区)之间的数据传输,最终实现硬件层面的数据读写。
五、核心I/O机制对比
Linux 提供了多种I/O机制,适用于不同的业务场景,核心差异在于数据传输路径、拷贝次数及使用限制,以下对比三种最常用的I/O机制:
1. 传统Buffered IO(缓冲I/O)
核心流程:磁盘数据 → DMA拷贝至PageCache(内核缓存)→ CPU拷贝至用户态Buffer → 应用程序读取数据;写入流程相反。
核心特点:读写操作灵活,支持任意偏移量、任意长度的读写,无需考虑数据页对齐;存在2次数据拷贝(1次DMA+1次CPU),开销中等。
适用场景:普通文件读写、小数据量I/O、对性能要求不高的场景(如日志写入、配置文件读取)。
2. mmap(内存映射I/O)
核心原理:通过
mmap()系统调用,将内核态的PageCache直接映射到用户态的地址空间,使应用程序可直接访问PageCache中的数据,无需通过CPU拷贝将数据从内核态传递至用户态。核心优势:省略了PageCache→用户态Buffer的CPU拷贝,仅保留1次DMA拷贝(磁盘→PageCache),减少1次数据拷贝,提升大数据量传输性能。
核心限制:数据传输需按页对齐(必须是4KB的整数倍);映射区域的大小受限于可用内存;不适用于小数据量、频繁读写的场景(映射开销高于拷贝开销)。
适用场景:大数据量文件读写、进程间共享内存、数据库索引读取等场景。
3. Direct IO(直接I/O)
核心原理:跳过内核态的PageCache,应用程序直接对接块I/O层,通过DMA控制器将数据从用户态Buffer直接传输至磁盘(写操作),或从磁盘直接传输至用户态Buffer(读操作),完全绕开内核缓存。
核心优势:无需写入PageCache,减少内核缓存的占用,写效率极高;避免了PageCache与磁盘数据的同步开销,适用于自身具备缓存机制的应用。
核心限制:数据传输需按存储块大小/页对齐(如磁盘扇区大小、Page大小);应用程序需自行管理缓存(如数据库的Buffer Pool),开发复杂度高;小数据量读写性能较差(无PageCache预读优化)。
适用场景:数据库(MySQL、PostgreSQL)、大数据处理等具备自研缓存机制的应用,需避免内核缓存与应用缓存的双重冗余。
六、I/O Buffering(双层缓冲机制)
Linux I/O 存在双层缓冲机制(用户态缓冲+内核态缓冲),核心目的是减少系统调用次数、降低I/O开销,两层缓冲相互配合,构成完整的缓冲体系。
1. 用户态缓冲(stdio buffer)
由C标准库(stdio)实现,位于用户态,属于应用程序层面的缓冲,核心作用是聚合小粒度的读写操作,减少系统调用次数(系统调用开销远高于用户态缓冲拷贝开销)。
缓冲策略:默认情况下,stdio缓冲会缓存一定量的数据(如4KB),当缓冲满、触发
fflush()函数、关闭文件(fclose())时,才会将缓冲中的数据一次性写入内核态缓冲(或直接写入设备)。配置方式:支持通过
fflush()主动刷新缓冲(将缓冲数据同步至内核),通过setbuf()函数配置缓冲大小(或关闭缓冲),满足不同场景的需求。
2. 内核态缓冲
由Linux内核实现,位于内核态,分为两种类型,分别对应不同的缓存场景,相互补充:
PageCache(页缓存):缓存文件内容,与文件系统强相关,是内核态缓冲的核心,用于优化文件读写性能(前文已详细说明),所有基于文件的I/O操作都会用到PageCache。
BufferCache(块缓存):缓存磁盘设备块数据,包括文件系统的元数据(如inode、目录项)、未被文件系统管理的裸设备块数据,与文件系统无关,主要用于优化磁盘块的读写效率,减少磁盘寻道次数。
Linux I/O 的核心是“数据传输与开销控制”,掌握以上这些知识,基本上可以快速理解Linux I/O的工作原理,为高性能I/O开发与优化提供基础。
最 后
小哥搜集了一些嵌入式学习资料,公众号内回复【1024】即可找到下载链接!
推荐好文点击蓝色字体即可跳转
☞专辑|Linux应用程序编程大全 ☞ 专辑|学点网络知识 ☞ 专辑|手撕C语言 ☞ 专辑|手撕C++语言
☞ 专辑|经验分享 ☞ 专辑|从单片机到Linux ☞ 专辑|电能控制技术 ☞ 专辑|嵌入式必备数学知识 ☞ MCU进阶专辑
☞ 经验分享









