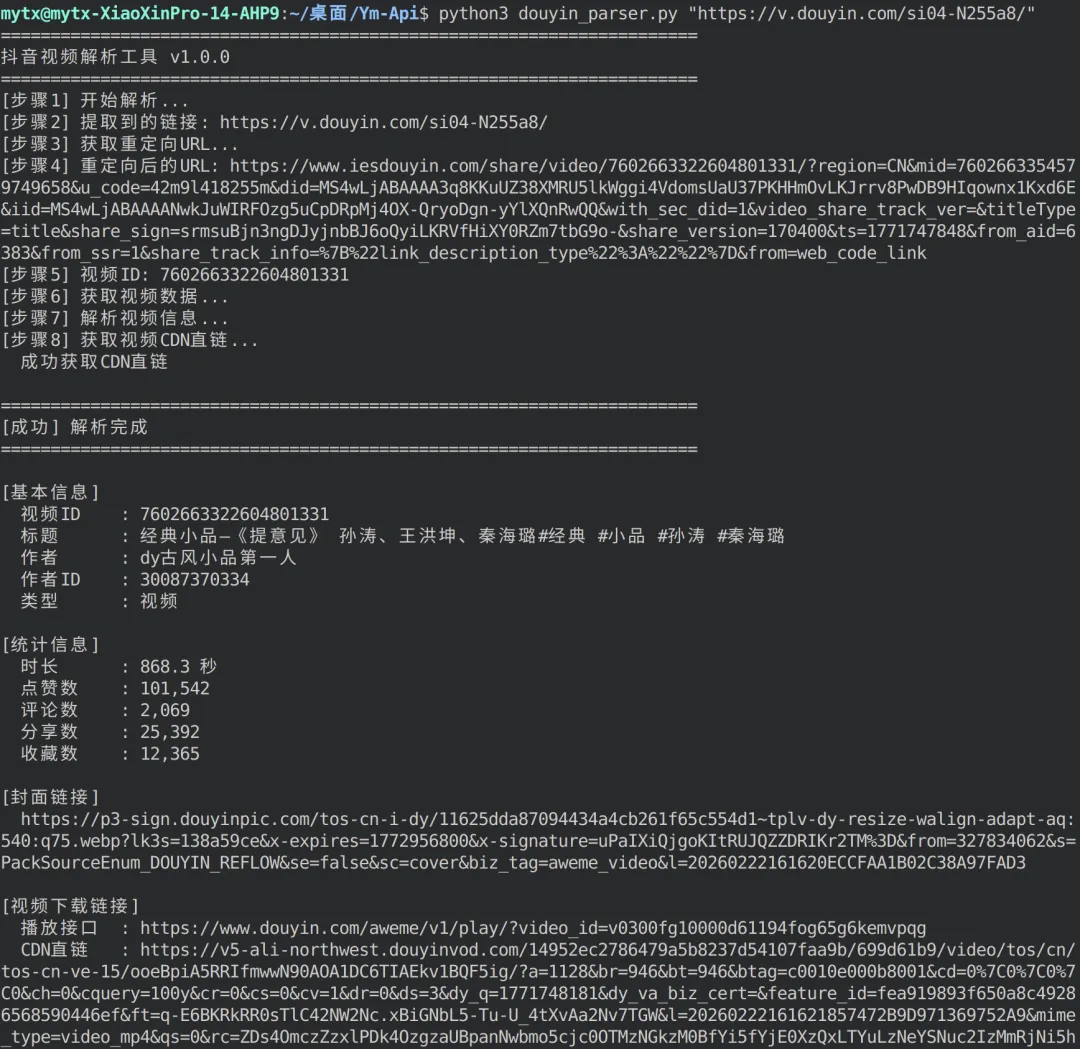
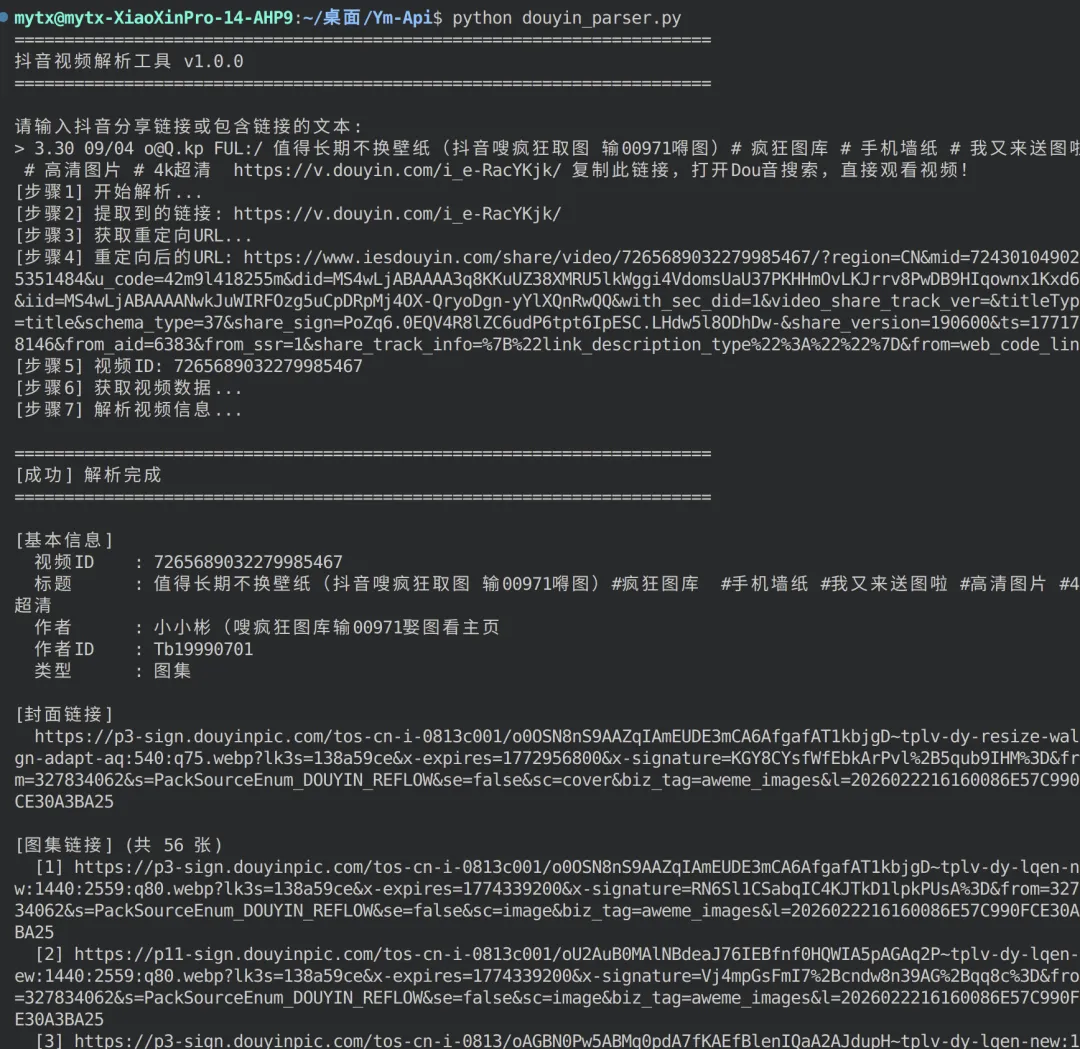
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""抖音视频解析工具 - 独立版本功能:解析抖音分享链接,获取视频信息和无水印下载地址作者:千秋Api版本:1.0.0"""import reimport jsonimport sysfrom urllib.parse import urlparse, parse_qsimport urllib.requestimport urllib.error# ============================================================================# 链接提取与处理# ============================================================================def extract_douyin_url(text): """ 从文本中提取抖音链接 参数: text: 包含抖音链接的文本 返回: str: 提取到的抖音链接,未找到则返回None """ pattern = r'https?://v\.douyin\.com/[A-Za-z0-9_-]+/?' match = re.search(pattern, text) if match: return match.group(0) return Nonedef get_redirect_url(short_url, timeout=5): """ 获取短链接重定向后的真实URL 参数: short_url: 抖音短链接 timeout: 请求超时时间(秒) 返回: str: 重定向后的完整URL,失败返回None """ try: req = urllib.request.Request( short_url, headers={ 'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15' } ) with urllib.request.urlopen(req, timeout=timeout) as response: return response.url except Exception as e: print(f"[错误] 获取重定向URL失败: {e}") return Nonedef extract_video_id(url): """ 从URL中提取视频ID 参数: url: 完整的抖音视频URL 返回: str: 19位视频ID,未找到返回None """ # 尝试多种匹配模式 patterns = [ r'/video/(\d{19})', # 标准格式 r'/(\d{19})', # 简化格式 r'modal_id=(\d{19})', # 参数格式 ] for pattern in patterns: match = re.search(pattern, url) if match: return match.group(1) # 尝试从查询参数中获取 parsed = urlparse(url) query_params = parse_qs(parsed.query) if 'modal_id' in query_params: return query_params['modal_id'][0] return None# ============================================================================# 视频数据获取与解析# ============================================================================def fetch_video_data(video_id, timeout=8): """ 从抖音服务器获取视频详细数据 参数: video_id: 19位视频ID timeout: 请求超时时间(秒) 返回: dict: 视频数据字典,失败返回None """ url = f'https://www.iesdouyin.com/share/video/{video_id}/' try: req = urllib.request.Request( url, headers={ 'User-Agent': 'Mozilla/5.0 (Linux; Android 8.0.0; SM-G955U Build/R16NW) AppleWebKit/537.36', 'Referer': 'https://www.douyin.com/?is_from_mobile_home=1&recommend=1' } ) with urllib.request.urlopen(req, timeout=timeout) as response: html = response.read().decode('utf-8') # 查找数据标记位置 start_marker = 'window._ROUTER_DATA' start_idx = html.find(start_marker) if start_idx == -1: print("[错误] 未找到视频数据标记") print("[提示] 页面可能已改版或需要登录") return None # 定位JSON数据起始位置 json_start = html.find('{', start_idx) if json_start == -1: print("[错误] 无法找到JSON数据") return None # 匹配大括号,找到JSON结束位置 brace_count = 0 json_end = json_start max_search = min(json_start + 500000, len(html)) for i in range(json_start, max_search): if html[i] == '{': brace_count += 1 elif html[i] == '}': brace_count -= 1 if brace_count == 0: json_end = i + 1 break if json_end == json_start: print("[错误] 无法解析完整JSON") return None # 解析JSON数据 json_str = html[json_start:json_end] try: router_data = json.loads(json_str) except json.JSONDecodeError as e: print(f"[错误] JSON解析失败: {e}") print(f"[调试] JSON片段: {json_str[:200]}...") return None # 提取视频信息 - 使用更灵活的路径 try: # 尝试标准路径 loader_data = router_data.get('loaderData', {}) if not loader_data: print("[错误] loaderData为空") print(f"[调试] router_data键: {list(router_data.keys())}") return None # 查找包含videoInfoRes的键 - 遍历所有键查找有效数据 video_key = None video_data = None for key in loader_data.keys(): data = loader_data.get(key) if data and isinstance(data, dict) and 'videoInfoRes' in data: video_key = key video_data = data break if not video_key or not video_data: print(f"[错误] 未找到包含videoInfoRes的数据") print(f"[调试] loaderData中的键: {list(loader_data.keys())}") return None if isinstance(video_data, dict): video_info = video_data.get('videoInfoRes', {}) if not video_info: print(f"[错误] videoInfoRes为空") print(f"[调试] video_data键: {list(video_data.keys())}") return None item_list = video_info.get('item_list', []) if not item_list: print("[错误] 视频列表为空") return None return item_list[0] else: print(f"[错误] video_data类型错误: {type(video_data)}") return None except (KeyError, IndexError) as e: print(f"[错误] 数据结构错误: {e}") print(f"[调试] router_data键: {list(router_data.keys())}") if 'loaderData' in router_data: print(f"[调试] loaderData键: {list(router_data['loaderData'].keys())}") return None except urllib.error.HTTPError as e: print(f"[错误] HTTP错误 {e.code}: {e.reason}") return None except urllib.error.URLError as e: print(f"[错误] 网络错误: {e.reason}") return None except Exception as e: print(f"[错误] 获取视频数据失败: {e}") import traceback traceback.print_exc() return Nonedef get_real_download_url(play_url, timeout=5): """ 获取视频的真实CDN下载地址 参数: play_url: 播放接口URL timeout: 请求超时时间(秒) 返回: str: CDN直链地址,失败返回原播放URL """ try: req = urllib.request.Request( play_url, headers={ 'User-Agent': 'Mozilla/5.0 (Linux; Android 8.0.0; SM-G955U Build/R16NW) AppleWebKit/537.36', 'Referer': 'https://www.douyin.com/' } ) with urllib.request.urlopen(req, timeout=timeout) as response: real_url = response.url # 检查是否为CDN链接 if 'douyinvod.com' in real_url or 'douyinstatic.com' in real_url: return real_url return play_url except Exception as e: print(f"[提示] 获取CDN直链失败,使用播放接口: {e}") return play_urldef parse_video_info(item): """ 解析视频数据,提取关键信息 参数: item: 从API获取的原始视频数据 返回: dict: 包含视频信息的字典,失败返回None """ try: # 检查是否为图集 images = item.get('images', []) is_image = bool(images) # 提取封面图片 cover_url = '' if item['video']['cover']['url_list']: cover_url = item['video']['cover']['url_list'][0] # 提取统计数据 statistics = item.get('statistics', {}) # 构建基本结果字典 result = { 'video_id': item['aweme_id'], 'title': item.get('desc', '抖音视频'), 'author': item['author']['nickname'], 'author_id': item['author'].get('unique_id', ''), 'cover': cover_url, 'type': 'image' if is_image else 'video', 'duration': item['video'].get('duration', 0) / 1000, 'like_count': statistics.get('digg_count', 0), 'comment_count': statistics.get('comment_count', 0), 'share_count': statistics.get('share_count', 0), 'collect_count': statistics.get('collect_count', 0), } # 处理图集 if is_image: print("[步骤8] 解析图集链接...") image_list = [] for idx, img in enumerate(images, 1): if img.get('url_list'): img_url = img['url_list'][0] image_list.append(img_url) print(f" 图片 {idx}: {img_url[:80]}...") result['image_list'] = image_list result['video_url'] = None result['real_video_url'] = None else: # 处理视频 video_uri = item['video']['play_addr']['uri'] video_url = f"https://www.douyin.com/aweme/v1/play/?video_id={video_uri}" result['video_url'] = video_url result['image_list'] = [] # 获取真实CDN下载地址 print("[步骤8] 获取视频CDN直链...") real_url = get_real_download_url(video_url) result['real_video_url'] = real_url if real_url != video_url: print(f" 成功获取CDN直链") else: print(f" 使用播放接口链接") return result except Exception as e: print(f"[错误] 解析视频信息失败: {e}") import traceback traceback.print_exc() return None# ============================================================================# 主解析流程# ============================================================================def parse_douyin(url_or_text): """ 解析抖音视频的主函数 参数: url_or_text: 抖音链接或包含链接的文本 返回: dict: 解析结果,失败返回None """ print("[步骤1] 开始解析...") # 提取链接 url = extract_douyin_url(url_or_text) if not url: url = url_or_text print(f"[步骤2] 提取到的链接: {url}") # 获取重定向URL print("[步骤3] 获取重定向URL...") redirect_url = get_redirect_url(url) if not redirect_url: return None print(f"[步骤4] 重定向后的URL: {redirect_url}") # 提取视频ID video_id = extract_video_id(redirect_url) if not video_id: print("[错误] 无法提取视频ID") return None print(f"[步骤5] 视频ID: {video_id}") # 获取视频数据 print("[步骤6] 获取视频数据...") item = fetch_video_data(video_id) if not item: return None # 解析视频信息 print("[步骤7] 解析视频信息...") result = parse_video_info(item) return result# ============================================================================# 结果输出# ============================================================================def print_result(result): """ 格式化打印解析结果 参数: result: 解析得到的视频信息字典 """ if not result: print("\n" + "="*70) print("[失败] 解析失败") print("="*70) return print("\n" + "="*70) print("[成功] 解析完成") print("="*70) # 基本信息 print("\n[基本信息]") print(f" 视频ID : {result['video_id']}") print(f" 标题 : {result['title']}") print(f" 作者 : {result['author']}") if result['author_id']: print(f" 作者ID : {result['author_id']}") print(f" 类型 : {'图集'if result['type'] == 'image'else'视频'}") # 统计信息 print("\n[统计信息]") if result['type'] == 'video': print(f" 时长 : {result['duration']:.1f} 秒") print(f" 点赞数 : {result['like_count']:,}") print(f" 评论数 : {result['comment_count']:,}") print(f" 分享数 : {result['share_count']:,}") print(f" 收藏数 : {result['collect_count']:,}") # 封面链接 if result['cover']: print("\n[封面链接]") print(f" {result['cover']}") # 视频下载链接 if result['type'] == 'video': print("\n[视频下载链接]") print(f" 播放接口 : {result['video_url']}") if result['real_video_url'] and result['real_video_url'] != result['video_url']: print(f" CDN直链 : {result['real_video_url']}") # 图集链接 elif result['image_list']: print(f"\n[图集链接] (共 {len(result['image_list'])} 张)") for i, img in enumerate(result['image_list'], 1): print(f" [{i}] {img}") print("\n" + "="*70)# ============================================================================# 程序入口# ============================================================================def main(): """主函数""" print("="*70) print("抖音视频解析工具 v1.0.0") print("="*70) # 获取输入 if len(sys.argv) > 1: # 从命令行参数获取 url = sys.argv[1] else: # 交互式输入 print("\n请输入抖音分享链接或包含链接的文本:") url = input("> ").strip() if not url: print("[错误] 未输入链接") return # 执行解析 result = parse_douyin(url) # 输出结果 print_result(result)if __name__ == '__main__': main()