驾驭AI的Python|项目实战导引 3:AI 批量简历筛选系统
- 2026-07-01 14:02:12
项目实战导引 3:AI 批量简历筛选系统
第 20 课:从草稿到成品—让你的代码走出 Notebook
第 21 课:Python 内置包——让编程更强大的工具箱
第 22 课:使用第三方库——探索中国二手车市场
第 23 课:使用 API 从网络获取数据
第 24 课:独立宣言——构建你自己的 AI 接入能力
山河书籍与朝夕,公众号:山河书籍与朝夕驾驭AI的Python|导学课:零基础面向 AI 时代的 Python 入门与实战课程,不走传统编程学习的弯路。

欢迎来到你的新任务!
🎯 在这个充满挑战的项目中,你将化身为一家公司的 HR 实习生,运用 Python 和 AI 技术来处理真实的招聘场景。
你需要从 15 份格式各异、质量参差不齐的简历中,自动筛选出最优秀的候选人。准备好展示你的编程实力了吗?💪




任务背景 📋
你刚入职一家快速发展的科技公司,老板急需招聘一批技术人才。
他把一个装满简历的文件夹甩给你,里面有 15 份简历(txt 格式)。
然而,这些简历的情况非常复杂:
📝 有的是中文简历,有的是英文简历 🗑️ 有的只有一句话,属于无效简历 ❓ 有的简历没有写姓名 🔀 有的是图片转文字的乱码
手动处理这些简历将耗费大量时间,而且容易出错。是时候让 Python 和 AI 来拯救你了!🚀

🎯 任务目标
编写一个 Python 程序,自动完成以下工作:
- 📂 遍历读取
: 读取 resumes文件夹中的所有.txt文件 - 🧹 清洗过滤
: 跳过字数少于 50 字的"垃圾文件" - 🤖 AI 分析
: 让 AI 提取每份简历的: 姓名 (Name) 毕业院校 (University) 核心技能 (Skills) 匹配度评分 (Score: 0-100) - 💾 保存结果
: 将评分超过 80 分的候选人信息写入 passed_candidates.csv文件
🔥 难度点(坑)
在完成任务的过程中,你需要特别注意以下几个容易踩的坑:
⚠️ 有的简历里没有写名字 → AI 可能返回 Unknown,程序不能崩溃⚠️ 有的简历是纯图片转文字的乱码 → Prompt 需要能够识别并标记"无法判断" ⚠️ 中英文混合 → 需要设计通用的 Prompt ⚠️ 文件编码问题 → 读取文件时可能遇到编码错误 ⚠️ AI 返回格式不统一 → 需要做好异常处理
开始之前 🚦
在开始编写代码之前,我们需要导入必要的测试模块和辅助函数。
运行下面的单元格来加载本次作业所需的函数:
from helper_functions import get_llm_response, print_llm_responsefrom project_functions import check_answer, PROMPT_TEST_Q1, PROMPT_TEST_Q2, PROMPT_TEST_Q3, PROMPT_TEST_Q4, PROMPT_TEST_Q5
✅ 关键提示:
--- 请在下方编写你的代码 ---和--- 代码编写结束 ---注释标记了你需要填写代码的区域。不要修改这些注释之外的任何代码。代码中已经存在的部分,可能包含课程未直接学习过的内容,但不需要焦虑,只需要了解他们的功能即可。
设计项目时难免遇到未涉足的领域,学会解决这些未知也是技能的一部分。你可以在测后通过 AI 对这些内容做更深入的了解。
除了需要你填写解决方案的单元格外,不要修改其他单元格,否则可能导致运行异常。
每个练习后面都有使用
check_answer的测试单元格。务必运行这些单元格,它们基于AI反馈,会为你的解决方案提供即时评分。评分系统只会评估已经提供给你的单元格,因此请确保在这些单元格中填写你的解决方案代码。
练习目录
练习 1: 遍历文件夹 - 获取所有简历文件路径 📂 练习 2: 读取与过滤 - 清洗无效简历 🧹 练习 3: 设计 AI Prompt - 提取简历关键信息 🤖 练习 4: 批量处理 - 分析所有有效简历 ⚙️ 练习 5: 筛选与保存 - 导出优秀候选人 💾
练习 1: 自动化读取 - 批量加载简历数据 📂
为了实现 HR 办公自动化,我们首先需要让程序能够自动“走进”存放简历的文件夹,把里面所有的 .txt 简历内容读出来。
在实际场景中,HR 只需要将新收到的简历放入 resumes 文件夹。在这个练习中,我会为你处理好“寻找文件”的繁琐步骤,你的任务是编写核心的读取逻辑。
你的任务:
完善 load_all_resumes 函数中的核心部分:
- 打开并读取
: 使用 Python 的文件操作语法,读取每一个 .txt文件的文本内容。 - 存入列表
: 将获取的文件名和内容包装成字典,添加进我们准备好的 resumes_list中。
要求:
- 返回值
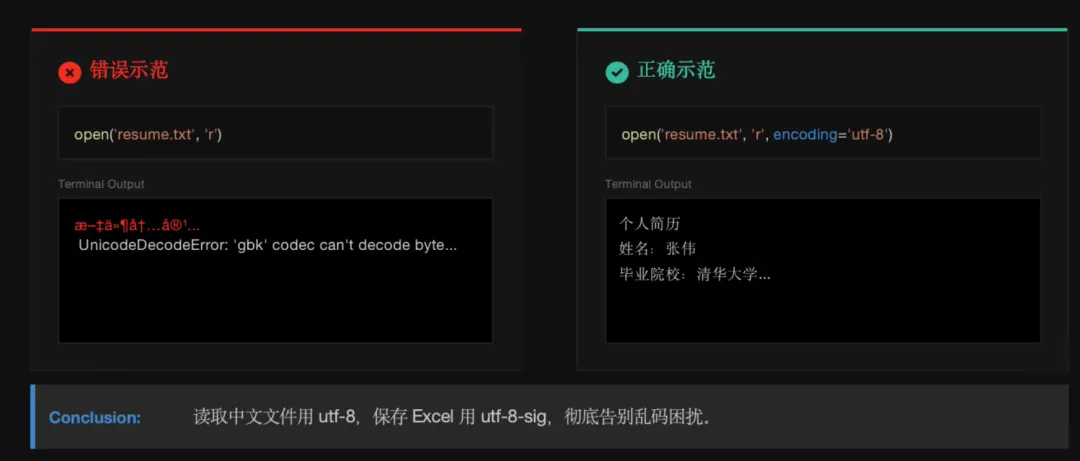
: 函数最终应返回一个字典列表,格式如: [{"filename": "resume_001.txt", "content": "..."} , ...]。 - 字符编码
: 读取时请务必指定 encoding='utf-8',以确保中文简历不会变成乱码。
核心提示:
使用 with open(文件路径, 'r', encoding='utf-8') as f:来安全地读取。使用 f.read()获取文件全部文本。使用 列表.append({"filename": ..., "content": ...})来保存结果。
import osdef load_all_resumes(folder_path):"""自动读取文件夹内的所有 .txt 简历"""resumes_list = []# 【已提供】获取文件夹下所有文件的名称all_files = os.listdir(folder_path)for file_name in all_files:# 【已提供】只处理以 .txt 结尾的文件if file_name.endswith('.txt'):# 【已提供】将文件夹路径和文件名拼接成完整的“文件路径”full_path = os.path.join(folder_path, file_name)# --- 请在下方编写你的代码 ---# 1. 使用 with open 打开 full_path 并读取内容# 💡 提示:记得指定 encoding='utf-8',否则中文会变成乱码哦# 2. 将提取到的信息以字典形式 {"filename": ..., "content": ...} 添加进 resumes_list# 💡 提示:使用列表的 .append() 方法# --- 代码编写结束 ---return resumes_list
import osdef load_all_resumes(folder_path):"""自动读取文件夹内的所有 .txt 简历"""resumes_list = []# 【已提供】获取文件夹下所有文件的名称all_files = os.listdir(folder_path)for file_name in all_files:# 【已提供】只处理以 .txt 结尾的文件if file_name.endswith('.txt'):# 【已提供】将文件夹路径和文件名拼接成完整的“文件路径”full_path = os.path.join(folder_path, file_name)# --- 请在下方编写你的代码 ---# 1. 使用 with open 打开 full_path 并读取内容# 💡 提示:记得指定 encoding='utf-8',否则中文会变成乱码哦with open(full_path,"r",encoding="utf-8") as f :file_content = f.read()# 2. 将提取到的信息以字典形式 {"filename": ..., "content": ...} 添加进 resumes_list# 💡 提示:使用列表的 .append() 方法resumes_dict = {"filename" : file_name,"content" : file_content}resumes_list.append(resumes_dict)# --- 代码编写结束 ---return resumes_list
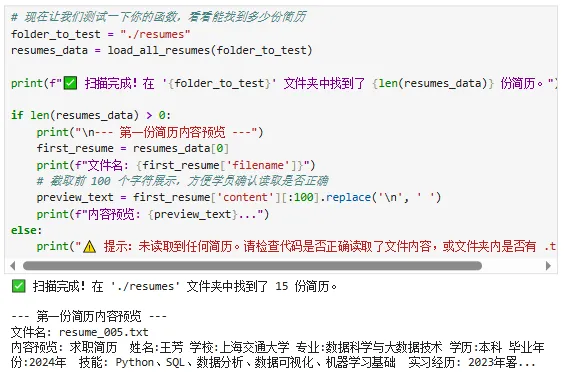
# 现在让我们测试一下你的函数,看看能找到多少份简历folder_to_test = "./resumes"resumes_data = load_all_resumes(folder_to_test)print(f"✅ 扫描完成!在 '{folder_to_test}' 文件夹中找到了 {len(resumes_data)} 份简历。")if len(resumes_data) > 0:print("\n--- 第一份简历内容预览 ---")first_resume = resumes_data[0]print(f"文件名: {first_resume['filename']}")# 截取前 100 个字符展示,方便学员确认读取是否正确preview_text = first_resume['content'][:100].replace('\n', ' ')print(f"内容预览: {preview_text}...")else:print("⚠️ 提示:未读取到任何简历。请检查代码是否正确读取了文件内容,或文件夹内是否有 .txt 文件。")
练习 2: 数据清洗 - 筛选无效简历 🧹
在练习 1 中,我们已经把所有简历内容“搬”进了电脑内存,存放在了 resumes_data 列表中。
但在现实场景中,文件夹里经常混入无效文件(如空白文档或损坏的简历)。为了节省 AI 的处理额度并提高效率,我们需要在正式分析前进行一次“数据清洗”:只保留内容充实(不少于 50 个字符)的简历。
你的任务:
完善 filter_resumes 函数,对已加载的简历数据进行筛选:
- 遍历名单
: 使用 for循环检查输入的resumes_list。 - 内容判断
: 提取每份简历的 content(内容)。如果内容不少于 50 个字符,则认为它是有效的,将其保留。 如果内容少于 50 个字符,则直接跳过。 - 返回结果
: 函数最终返回一个只包含“有效简历”的新列表。
要求:
- 逻辑要求
: 只有当长度达到标准时,才使用 .append()将该简历字典添加到新列表中。 - 字典操作
: 记住每份简历都是一个字典,你需要通过键名 'content'来获取文字内容。
提示:
使用 len(字符串)来计算内容长度。使用 if语句进行逻辑判断。你的代码逻辑应该在函数定义的内部完成。
def filter_resumes(resumes_list):"""清洗数据:剔除字数不足 50 字的无效简历"""# 准备一个空列表,用来存放通过筛选的有效简历clean_results = []# --- 请在下方编写你的代码 ---# 1. 使用 for 循环遍历输入的 resumes_list# 2. 获取该份简历的内容 (提示:从字典中通过键名 'content' 取值)# 3. 判断:如果内容长度 >= 50,则使用 .append() 添加到 clean_results 中# 💡 提示:使用 len() 函数来获取字符串的长度# --- 代码编写结束 ---return clean_results
def filter_resumes(resumes_list):"""清洗数据:剔除字数不足 50 字的无效简历"""# 准备一个空列表,用来存放通过筛选的有效简历clean_results = []# --- 请在下方编写你的代码 ---# 1. 使用 for 循环遍历输入的 resumes_listfor resume in resumes_list :# 2. 获取该份简历的内容 (提示:从字典中通过键名 'content' 取值)resume_content = resume["content"]# 3. 判断:如果内容长度 >= 50,则使用 .append() 添加到 clean_results 中# 💡 提示:使用 len() 函数来获取字符串的长度if len(resume_content) >= 50 :clean_results.append(resume)# --- 代码编写结束 ---return clean_results
# --- 运行看效果 ---# 我们把练习 1 得到的 resumes_data 传进去进行清洗filtered_resumes = filter_resumes(resumes_data)print(f"📊 数据清洗报告:")print(f" - 原始简历总数: {len(resumes_data)} 份")print(f" - 过滤后有效数: {len(filtered_resumes)} 份")print(f" - 自动剔除无效数: {len(resumes_data) - len(filtered_resumes)} 份")
练习 3: 设计 AI Prompt - 提取简历关键信息 🤖
现在是最关键的一步!我们需要设计一个强大的 Prompt(提示词),让 AI 能够从杂乱的简历文本中精准提取出关键信息。
虽然我们最终的目标是生成一个 Excel/CSV 报表,但在与 AI 沟通时,JSON 格式是最稳定的“结构化语言”。它能确保 AI 提取的数据能够严丝合缝地填入我们未来的表格中。(提示: 如果你想了解什么是 JSON 以及它的适用场景,可以现在就询问一下 AI!)
你的任务:
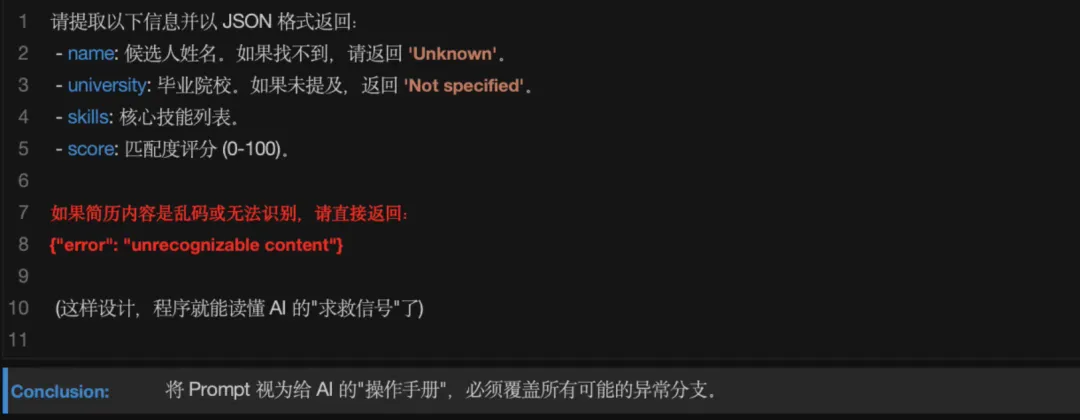
完善 prompt 字符串,要求 AI 从简历中提取以下四个字段:
- name
(姓名:如果没有,返回 "Unknown") - university
(毕业院校:如果没有,返回 "Unknown") - skills
(核心技能:请让 AI 总结 3-5 个关键词,用逗号分隔) - score
(匹配度评分:0-100 的整数,评估候选人与技术岗位的匹配程度)
AI 需要满足的要求:
- 多语言处理
: 能够同时处理中文和英文简历。 - 异常识别
: 如果简历内容是乱码或无意义文字,将所有字段标记为 "无法判断",评分为 0。 - 严格格式
: 必须返回标准的 JSON 格式,以便我们在练习 5 中顺利导出为 CSV 文件。
编写建议:
在 Prompt 中明确告诉 AI:“请只返回 JSON 格式,不要有任何多余的解释文字。” 给出具体的评分标准(例如:重点考察候选人的 Python 基础和项目逻辑)。 使用 Python 的 f-string语法将简历变量{content}嵌入到你的 Prompt 中。
# 示例简历内容 (取出练习 2 清洗后的第一份简历用于测试)sample_resume = filtered_resumes[0]["content"]# --- 请在下方编写你的代码 ---# 编写你的 Prompt# 💡 提示:# 1. 引号开头必须加 f (f-string),否则 {sample_resume} 会被当成普通文字# 2. 在【输出格式】中,我们使用了双大括号 {{ }},这是为了让 Python 知道我们要显示真的大括号prompt = f"""你是一位专业的 HR 助手,需要从简历中提取关键信息并评估候选人。【提取要求】1. 姓名 (name): 如果简历中没有明确的姓名,返回 "Unknown"2. 毕业院校 (university):3. 核心技能 (skills):4. 匹配度评分 (score):【评分标准】- 90-100分: 顶尖候选人(名校背景 + 丰富经验 + 核心技能强)- 80-89分: 优秀候选人()- 60-79分: 合格候选人()- 0-59分: 不符合要求()【输出格式】请直接返回内容,绝对不要包含 ```json 这种格式符,只需输出如下格式:{{"name": "姓名或Unknown","university": " ","skills": " ","score": 0}}【简历内容】{}"""# --- 代码编写结束 ---# --- 下方为验证逻辑,无需修改 ---print("📝 你的 Prompt 预览 (前 500 个字符):")print("-" * 30)print(prompt[:500] + "...")print("-" * 30)if "{" + "sample_resume" + "}" in prompt:print("❌ 提醒:变量未成功填充,请检查引号前是否漏写了小写字母 'f'。")elif "university" not in prompt or "score" not in prompt:print("❌ 提醒:Prompt 中似乎漏掉了关键的提取项或 JSON 字段。")else:print("✨ 检查通过:Prompt 骨架已补全,逻辑连贯!")
# 示例简历内容 (取出练习 2 清洗后的第一份简历用于测试)sample_resume = filtered_resumes[0]["content"]# --- 请在下方编写你的代码 ---# 编写你的 Prompt# 💡 提示:# 1. 引号开头必须加 f (f-string),否则 {sample_resume} 会被当成普通文字# 2. 在【输出格式】中,我们使用了双大括号 {{ }},这是为了让 Python 知道我们要显示真的大括号prompt = f"""你是一位专业的 HR 助手,需要从简历中提取关键信息并评估候选人。【多语言处理要求】- 同时支持中英文简历的信息提取,姓名、院校名称等可保留原文语言。【乱码与无效内容处理规则】- 若简历中出现乱码、无意义字符或无法识别的内容,要求返回"无法判断",评分为 0。【提取要求】1. 姓名 (name):- 提取简历中明确的姓名,中英文均可。- 若简历中无明确姓名,返回"Unknown"。2. 毕业院校 (university):- 提取完整的院校名称,中英文均可。- 若无院校信息,返回"Unknown"。3. 核心技能 (skills):- 提取3-5项核心专业技能,用逗号分隔。- 若无有效技能信息,返回"Unknown"。4. 匹配度评分 (score):- 严格按照评分标准给出0-100的整数分数。- 若简历为乱码/无意义文字,直接返回 0 分。【评分标准】- 90-100分: 顶尖候选人(名校背景 + 丰富经验 + 核心技能强,综合相关性比较)- 80-89分: 优秀候选人(名校背景 + 丰富经验 + 核心技能强,综合相关性比较)- 60-79分: 合格候选人(名校背景 + 丰富经验 + 核心技能强,综合相关性比较)- 0-59分: 不符合要求(无院校信息/无相关经验/无核心技能/简历为乱码)【输出格式】请直接返回内容,绝对不要包含 ```json 这种格式符,请只返回 JSON 格式,不要有任何多余的解释文字。只需输出如下格式:{{"name": "姓名或Unknown","university": "毕业院校或Unknown","skills": "核心技能或Unknown","score": 0}}【简历内容】{sample_resume}"""# --- 代码编写结束 ---# --- 下方为验证逻辑,无需修改 ---print("📝 你的 Prompt 预览 (前 500 个字符):")print("-" * 30)print(prompt[:500] + "...")print("-" * 30)if "{" + "sample_resume" + "}" in prompt:print("❌ 提醒:变量未成功填充,请检查引号前是否漏写了小写字母 'f'。")elif "university" not in prompt or "score" not in prompt:print("❌ 提醒:Prompt 中似乎漏掉了关键的提取项或 JSON 字段。")else:print("✨ 检查通过:Prompt 骨架已补全,逻辑连贯!")

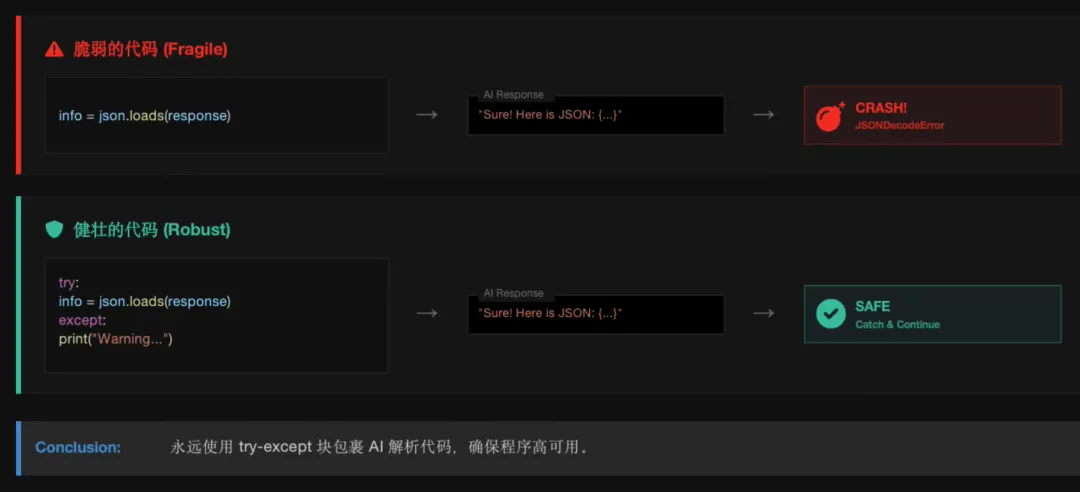
import json# 1. 调用 AI 助手response = get_llm_response(prompt)# 2. 尝试解析并直接打印try:# 这一步将字符串变成 Python 字典candidate_info = json.loads(response)print("✅ AI 成功提取信息:")# 直接打印字典对象print(candidate_info)except json.JSONDecodeError:print("❌ 错误:AI 返回的内容格式不正确")print(f"原始回复是:{response}")

练习 4: 批量处理 - 分析所有有效简历 ⚙️
太棒了!现在我们既有了经过清洗的简历数据(练习 2),又在练习 3 中设计好了强大的 AI 提示词模板。接下来的目标是开启“工业化”模式:通过 Python 的 for 循环,让 AI 一口气处理完所有简历。
在这个练习中,你将亲身体会到 Python 自动化带来的效率革命。
你的任务:
完善 analyze_all_resumes 函数,使其能够循环处理简历列表中的每一项。你只需要完成最核心的“连接”工作:
- 编写循环
: 使用 for循环遍历resumes_list(这是你在练习 2 中洗出的“干净名单”)。 - 构建提示词
: 在循环内部,将每份简历的内容嵌入到你的 Prompt 模板中。 - 调用 AI
: 使用 get_llm_response()函数将生成的 Prompt 发送给 AI 并获取回复。
温馨提示:
- 分工明确
: 我们在代码中已经为你处理好了 解析 JSON 和 保存到结果列表 的复杂部分。 - 变量替换
: 在练习 3 中你使用的是测试变量 sample_resume,但在现在的循环里,请记得改用循环变量content。 - 实时反馈
: 记得使用我们在代码块中提供的 print语句来观察进度,这样你就知道 AI 正在处理哪一份简历了。
import jsondef analyze_all_resumes(resumes_list):"""批量调用 AI 分析列表中的所有简历"""final_results = []# --- 请在下方编写你的代码 ---# 1. 编写 for 循环:遍历我们在练习 2 中得到的 resumes_list# 2. 变量提取:从当前的简历字典中提取 filename 和 content# 3. 打印进度:提示用户“正在分析: xxx...”# 4. 构建 Prompt:复用练习 3 的逻辑,别忘了嵌入当前的 {content}# 5. 调用 AI:使用 get_llm_response() 获取结果并存入变量 response# --- 代码编写结束 ---# --- 【老师提供的解析逻辑】 ---# 💡 特别提醒:为了让程序跑通,下面这段解析代码必须缩进在你的 for 循环内部!try:# 将 AI 返回的 JSON 字符串转换为 Python 字典info = json.loads(response)# 将解析后的结果添加进 final_results 列表final_results.append(info)except:# 如果 AI 返回格式有误,打印警告并继续处理下一份print(f"❌ 警告:无法解析文件 {filename} 的响应内容")return final_results
import jsondef analyze_all_resumes(resumes_list):"""批量调用 AI 分析列表中的所有简历"""final_results = []# --- 请在下方编写你的代码 ---# 1. 编写 for 循环:遍历我们在练习 2 中得到的 resumes_listfor resume in resumes_list:# 2. 变量提取:从当前的简历字典中提取 filename 和 contentfilename = resume["filename"]content = resume["content"]# 3. 打印进度:提示用户“正在分析: xxx...”print(f"正在分析: {filename}...")# 4. 构建 Prompt:复用练习 3 的逻辑,别忘了嵌入当前的 {content}prompt = f"""你是一位专业的 HR 助手,需要从简历中提取关键信息并评估候选人。【多语言处理要求】- 同时支持中英文简历的信息提取,姓名、院校名称等可保留原文语言。【乱码与无效内容处理规则】- 若简历中出现乱码、无意义字符或无法识别的内容,则返回"无法判断",评分返回 0。【提取要求】1. 姓名 (name):- 提取简历中明确的姓名,中英文均可。- 若简历中无明确姓名,返回 "Unknown"。2. 毕业院校 (university):- 提取完整的院校名称,中英文均可。- 若无院校信息,返回 "Unknown"。3. 核心技能 (skills):- 提取3-5项核心专业技能,用逗号分隔。- 若无有效技能信息,返回 "Unknown"。4. 匹配度评分 (score):- 严格按照评分标准给出0-100的整数分数。- 若简历为乱码/无意义文字,直接返回 0 分。【评分标准】- 90-100分: 顶尖候选人(名校背景 + 5年以上相关工作经验 + 核心技能覆盖3项以上)- 80-89分: 优秀候选人(本科及以上院校 + 3-5年相关经验 + 核心技能覆盖2-3项)- 60-79分: 合格候选人(大专及以上院校 + 1-3年相关经验 + 核心技能覆盖1-2项)- 0-59分: 不符合要求(无院校信息/无相关经验/无核心技能/简历为乱码)【输出格式】请直接返回内容,绝对不要包含 ```json 这种格式符,请只返回 JSON 格式,不要有任何多余的解释文字,只需输出如下格式:{{"name": "姓名或Unknown","university": "毕业院校或Unknown","skills": "核心技能或Unknown","score": 0}}【简历内容】{content}"""# 5. 调用 AI:使用 get_llm_response() 获取结果并存入变量 responseresponse = get_llm_response(prompt)# --- 代码编写结束 ---# --- 【老师提供的解析逻辑】 ---# 💡 特别提醒:为了让程序跑通,下面这段解析代码必须缩进在你的 for 循环内部!try:# 将 AI 返回的 JSON 字符串转换为 Python 字典info = json.loads(response)# 将解析后的结果添加进 final_results 列表final_results.append(info)except:# 如果 AI 返回格式有误,打印警告并继续处理下一份print(f"❌ 警告:无法解析文件 {filename} 的响应内容")return final_results
现在让我们处理所有简历(这可能需要半分钟时间):
# --- 运行看效果:开启批量分析任务 ---# 1. 传入练习 2 得到的“干净名单”进行 AI 分析# 这会触发你在练习 4 中编写的 for 循环流程all_candidates = analyze_all_resumes(filtered_resumes)print("\n" + "="*40)print(f"✨ 批量分析任务已完成!")print(f"📊 成功从 {len(filtered_resumes)} 份有效简历中提取了 {len(all_candidates)} 项信息。")print("="*40)# 2. 预览前 3 个提取结果,确认 AI 是否听话if all_candidates:print("\n--- 提取结果快照 (前 3 项) ---")for i, candidate in enumerate(all_candidates[:3]):# 这里直接打印字典内容,展示最真实的 Python 数据结构print(f"【候选人 {i+1}】")print(candidate)print("-" * 20)else:print("⚠️ 提示:没有提取到任何有效数据,请检查练习 3 的 Prompt 是否正确。")

练习 5: 筛选与保存 - 导出优秀候选人 💾
最后一步!现在我们手里已经有了 14 份(或更多)候选人的 AI 分析数据。为了方便 HR 查阅,我们需要筛选出其中的“佼佼者”(评分达到 80 分及以上的候选人),并把他们的信息保存到一份正式的 CSV 表格中。
在这个练习中,你将完成从“数据分析”到“办公交付”的最后闭环,真正解决 HR 的核心痛点。
你的任务:
完善 save_passed_candidates 函数,将筛选出的优秀人才导出为文件:
- 筛选名单
: 使用 for循环遍历所有的候选人。 - 条件判断
: 只有当评分 score >= 80时,才将该候选人加入passed_candidates列表。 - 返回结果
: 函数最后需要返回入选的人数,以便我们生成最后的统计报表。
要求:
- 筛选逻辑
: 确保只有分数大于或等于 80 的人才会被选中。 - 文件查看
: 生成的文件我们将采用特殊的 utf-8-sig编码,确保你能用 Excel 直接打开且不乱码。
核心提示:
- 基础循环
: 使用 for candidate in candidates_list:。 - 字典取值
: 使用 candidate['score']来获取 AI 打出的分数。 - 添加数据
: 使用 .append(candidate)将符合条件的候选人加入列表。
# output_file="passed_candidates.csv" 是一个“默认参数”# 就像餐厅的“招牌套餐”:如果你调用时不给文件名,程序就自动用这个名字存盘def save_passed_candidates(candidates_list, output_file="passed_candidates.csv"):"""筛选优秀候选人并保存为 CSV 报表"""passed_candidates = []# --- 请在下方编写你的代码 ---# 1. 使用 for 循环遍历 candidates_list (练习 4 得到的 AI 分析结果)for candidate in candidates_list:# 2. 判断该候选人的 'score' 是否大于等于 80 分# 💡 提示:从字典中取出分数,并进行比较运算score = candidate['score']if score >= 80:# 3. 将符合要求的候选人字典添加进 passed_candidates 名单中passed_candidates.append(candidate)# --- 代码编写结束 ---# --- 【已提供部分】保存为 CSV 文件 ---import csv# 定义表头:我们将保存姓名、院校、技能和分数这四项关键信息fieldnames = ['name', 'university', 'skills', 'score']try:# 使用 utf-8-sig 编码,确保导出的 CSV 文件在 Excel 中打开时中文不乱码with open(output_file, mode='w', newline='', encoding='utf-8-sig') as f:# --- 这一部分是“办公自动化”黑科技,直接运行即可 ---# 1. 设置表格模板:把 Python 的字典和 Excel 的列对齐writer = csv.DictWriter(f, fieldnames=fieldnames)# 2. 写入第一行:表格的标题头writer.writeheader()# 3. 批量填表:把筛选出的所有优秀候选人一次性存入文件writer.writerows(passed_candidates)print(f"✅ 报表生成成功!已挑选出 {len(passed_candidates)} 位优秀候选人。")except Exception as e:print(f"❌ 保存文件时出错: {e}")# 返回入选人数,供最后的总结报表使用return len(passed_candidates)
# --- 🏁 最终运行:保存结果并查看统计报表 ---# 1. 执行筛选与保存函数,获取入选人数# 这一步会生成 CSV 文件并返回符合条件的人数passed_count = save_passed_candidates(all_candidates)print("-" * 30)# 这里的提示语可以和函数内部的 ✅ 相互配合print(f"🎉 筛选流程全部结束!目标文件: passed_candidates.csv")# 2. 显示全流程“数据漏斗”统计 (Visual Feedback)print(f"\n📊 简历筛选全流程统计报告:")print(f" --------------------------------")print(f" • 文件夹扫描总数: {len(resumes_data):>3} 份") # :>3 是右对齐,让数字排得更整齐print(f" • 有效简历(初筛): {len(filtered_resumes):>3} 份")print(f" • AI 解析成功数: {len(all_candidates):>3} 份")print(f" • 最终入围(≥80分): {passed_count:>3} 份")print(f" --------------------------------")# 3. 计算通过率,体现职场专业感if len(all_candidates) > 0:success_rate = (passed_count / len(all_candidates)) * 100print(f"🚀 人才库匹配率: {success_rate:.1f}%")else:print("🚀 人才库匹配率: 0.0%")
这时,你的目录中应该已经出现了一份完整的候选人清单。
恭喜你!你已经成功利用 Python 和 AI 打造了一套全自动的简历筛选系统。
🎉 任务完成!
恭喜你亲手打造了一套 AI 简历筛选自动化系统!🎊 通过这个实战项目,你不仅写出了能够运行的代码,更掌握了 AI 时代核心的自动化生产力:
✅ 文件自动化管理:实现了对大量简历文件的路径提取与批量加载。 ✅ 数据清洗思维:学会了在投喂 AI 之前进行“质量检查”,自动剔除无效数据。 ✅ 提示词工程 (Prompt Engineering):掌握了如何让 AI 按严格的 JSON 格式 输出结构化信息。 ✅ 工业化批量处理:通过 Python 循环实现了“一人抵百人”的高效筛选流程。 ✅ 业务成果交付:完成了数据筛选并导出了符合 Excel 规范、无乱码的 CSV 报表。
这个项目证明了:当 Python 的逻辑力遇上大模型的理解力,原本需要 HR 耗费数天的繁琐工作,现在只需几秒钟即可完成。
💡 进阶挑战
如果你觉得意犹未尽,可以在这个系统的基础上尝试以下优化,挑战更高级的自动化场景:
- 更精细的筛选器
:尝试修改练习 5 的逻辑,不仅看总分,还要求“核心技能”中必须包含特定的关键词(如 "Python" 或 "AI")。 - 多维度数据提取
:在练习 3 的 Prompt 中尝试增加提取“工作年限”或“期望薪资”,看 AI 是否能精准识别并输出。 - 格式大通关
:挑战自己,查阅资料学习如何利用 Python 第三方库(如 PyPDF2或python-docx)直接读取.pdf或.docx格式的简历。 - 可视化报表
:尝试使用 Python 将筛选后的候选人分数分布画成一个简单的柱状图,直观展示人才分布。
继续保持学习的热情,在这个 AI 工具大爆发的时代,用代码创造属于你的高效工作法!🚀✨

