Linux 系统性能调优与监控
- 2026-07-03 17:22:36
Linux 系统性能调优与监控
目录
1. 引言:为什么需要系统性能调优 2. 性能分析方法论:从猜测到数据驱动 3. perf 工具实战:内核级性能剖析 4. eBPF 与 BCC:下一代动态追踪 5. CPU 性能调优:从火焰图到调度优化 6. 内存与 I/O 优化实战 7. 生产环境最佳实践与避坑指南
1. 引言:为什么需要系统性能调优
1.1 技术背景
在现代云计算和微服务架构中,Linux 系统性能调优已成为基础设施工程师的核心技能。随着系统规模扩大和业务复杂度增加,性能问题往往隐藏在系统各个层面:从硬件中断到内核调度,从应用代码到数据库查询。
根据 Netflix 性能工程团队的经验,80% 的性能问题可以通过系统级分析定位,而非盲目优化应用代码。
1.2 本文目标
• 掌握 Linux 性能分析的核心方法论(USE 方法、RED 方法) • 熟练使用 perf 工具进行 CPU、内存、I/O 剖析 • 了解 eBPF/BCC 在现代性能监控中的应用 • 学会从火焰图、热点函数中定位性能瓶颈 • 掌握生产环境的性能调优最佳实践
2. 性能分析方法论:从猜测到数据驱动
2.1 USE 方法(Utilization-Saturation-Errors)
由 Brendan Gregg 提出的 USE 方法,是系统资源分析的黄金标准:
实战示例:检查 CPU 饱和度
# 查看运行队列长度(r)和不可中断睡眠进程(b)$ vmstat 1 5procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 2345678 123456 5678900 0 0 0 0 234 567 5 2 93 0 0 3 0 0 2345600 123456 5678900 0 0 0 12 456 890 15 5 80 0 0# 解读:r 列 > CPU 核心数表示 CPU 饱和# 本例中 r=2-3,若系统有 4 核,则 CPU 未饱和2.2 RED 方法(Rate-Errors-Duration)
适用于微服务和应用层性能分析:
• Rate: 每秒请求数 • Errors: 错误率 • Duration: 请求延迟分布
2.3 性能分析的工作流程
1. 定义目标 → 2. 选择指标 → 3. 采集数据 → 4. 分析瓶颈 → 5. 验证优化3. perf 工具实战:内核级性能剖析
3.1 perf 简介
perf(Performance Counters for Linux)是 Linux 内核自带的性能剖析工具,位于 tools/perf 目录。它提供了一套统一的事件采样框架,支持:
• 硬件事件: CPU 性能监控计数器(PMCs) • 软件事件: 内核计数器(上下文切换、页错误等) • Tracepoints: 内核静态追踪点 • 动态追踪: kprobes/uprobes
3.2 快速入门:One-Liners
3.2.1 查看可用事件
# 列出所有可用事件$ sudo perf list# 列出调度相关 tracepoints$ sudo perf list 'sched:*'# 列出系统调用 tracepoints$ sudo perf list 'syscalls:*'3.2.2 CPU 统计分析
# 对指定命令进行 CPU 计数统计$ sudo perf stat gzip largefile Performance counter stats for'gzip largefile': 2,456.78 msec task-clock # 0.999 CPUs utilized 1,234 context-switches # 0.502 K/sec 5 cpu-migrations # 0.002 K/sec 12,345 page-faults # 0.005 M/sec 7,234,567,890 cycles # 2.945 GHz 15,678,901,234 instructions # 2.17 insn per cycle 3,456,789,012 branches # 1407.123 M/sec 45,678,901 branch-misses # 1.32% of all branches 2.457890123 seconds time elapsed 2.345678901 seconds user 0.111111111 seconds sys关键指标解读:
• IPC (Instructions Per Cycle): 2.17 表示每周期执行 2.17 条指令,越高越好 • Branch miss rate: 1.32% 表示分支预测失败率,一般应 < 5% • Context switches: 上下文切换次数,过多可能导致性能下降
3.2.3 CPU Profiling:找出热点函数
# 以 99Hz 采样所有 CPU 的 on-CPU 函数(持续 10 秒)# 99Hz 避免与定时器中断冲突$ sudo perf record -F 99 -ag -- sleep 10# 生成报告$ sudo perf report# 输出示例:# Overhead Command Shared Object Symbol# -------- ------- ------------------ ------------------# 32.13% dd [kernel.kallsyms] [k] blk_peek_request# |# --- blk_peek_request# virtblk_request# __blk_run_queue# | # |--98.31%-- queue_unplugged# | blk_flush_plug_list3.3 高级用法:带栈追踪的采样
3.3.1 采集火焰图数据
# 采集 30 秒的 CPU 栈追踪$ sudo perf record -F 99 -a -g -- sleep 30# 导出为折叠格式(用于生成火焰图)$ sudo perf script | ./stackcollapse-perf.pl > out.folded# 生成 SVG 火焰图$ ./flamegraph.pl out.folded > kernel.svg3.3.2 分析缓存未命中
# 统计 L1 数据缓存加载和未命中$ sudo perf stat -e L1-dcache-loads,L1-dcache-load-misses,L1-dcache-stores ./myapp# 采样 LLC(Last Level Cache)未命中事件$ sudo perf record -e LLC-load-misses -c 100 -ag -- sleep 53.4 动态追踪:kprobes
# 添加 tcp_sendmsg 内核函数探针$ sudo perf probe --add tcp_sendmsg# 追踪该函数(带栈回溯)$ sudo perf record -e probe:tcp_sendmsg -ag -- sleep 10# 查看报告$ sudo perf report# 删除探针$ sudo perf probe --del tcp_sendmsg3.5 Tracepoints:内核静态追踪
# 追踪所有块设备 I/O 请求$ sudo perf record -e block:block_rq_issue -ag -- sleep 10# 追踪调度器事件$ sudo perf stat -e 'sched:*' -a sleep 5# 追踪文件系统事件(ext4)$ sudo perf stat -e 'ext4:*' -a sleep 10# 追踪进程执行$ sudo perf record -e sched:sched_process_exec -a -- sleep 304. eBPF 与 BCC:下一代动态追踪
4.1 什么是 eBPF?
eBPF(extended Berkeley Packet Filter)是 Linux 内核的一项革命性技术,允许在内核空间运行沙盒程序,无需修改内核源码或加载内核模块。
核心优势:
• 安全: 通过验证器确保代码不会崩溃内核 • 高效: JIT 编译为本地机器码,性能接近原生 • 灵活: 可动态挂载到内核任意位置
4.2 BCC 工具集
BCC(BPF Compiler Collection)是开源的 eBPF 工具集,提供了丰富的即用型工具:
# 安装 BCC(Ubuntu/Debian)$ sudo apt-get install bpfcc-tools linux-headers-$(uname -r)# 常用 BCC 工具$ ls /usr/share/bcc/tools/biolatency biosnoop biotop bitesize bpflistcachestat cachetop cpudist cpuunclaimed dcsnoopexecsnoop ext4dist ext4slower filelife fileslowerfunccount funclatency gethostlatency hardirqs injectkillsnoop llcstat mdflush memleak mountsnoopnetqtop offcputime offwaketime oomkill opensnooppidpersec profile runqlat runqlen slabratetopsoftirqs stackcount statsnoop syncsnoop syscounttcplife tcpretrans tcptop vfsstat wakeuptimexfsdist xfsslower zfsdist zfsslower4.3 BCC 实战案例
4.3.1 分析磁盘 I/O 延迟
# 查看磁盘 I/O 延迟分布(直方图)$ sudo biolatencyTracing block device I/O... Hit Ctrl-C to end.^C usecs : count distribution 0 -> 1 : 0 | | 2 -> 3 : 0 | | 4 -> 7 : 0 | | 8 -> 15 : 12 |*** | 16 -> 31 : 234 |*************************************| 32 -> 63 : 89 |************* | 64 -> 127 : 45 |****** | 128 -> 255 : 12 |** | 256 -> 511 : 3 | | 512 -> 1023 : 1 | |# 解读:大部分 I/O 在 16-63 usec 完成,性能良好4.3.2 追踪文件打开
# 实时监控文件打开操作$ sudo opensnoopPID COMM FD ERR PATH1234 nginx 10 0 /var/log/nginx/access.log1234 nginx 9 0 /var/log/nginx/error.log5678 python3 12 0 /etc/passwd5678 python3 13 0 /proc/cpuinfo4.3.3 分析 CPU 调度延迟
# 查看 CPU 运行队列延迟分布$ sudo runqlatTracing run queue latency... Hit Ctrl-C to end.^C usecs : count distribution 0 -> 1 : 1234 |*************************************| 2 -> 3 : 567 |****************** | 4 -> 7 : 234 |******* | 8 -> 15 : 89 |*** | 16 -> 31 : 34 |* | 32 -> 63 : 12 | |# 解读:大部分任务等待时间 < 1 usec,调度正常4.3.4 分析 TCP 连接生命周期
# 追踪 TCP 连接建立和关闭$ sudo tcplifePID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS1234 curl 192.168.1.100 45678 93.184.216.34 443 12 2456 23455678 python3 127.0.0.1 54321 127.0.0.1 6379 1 89 56004.4 编写自定义 eBPF 程序
#!/usr/bin/env python3# filetrace.py - 追踪文件读写操作from bcc import BPF# eBPF 程序bpf_text = """#include <uapi/linux/ptrace.h>#include <linux/fs.h>#include <linux/sched.h>struct data_t { u32 pid; u64 ts; char comm[TASK_COMM_LEN]; char fname[256]; ssize_t size;};BPF_PERF_OUTPUT(events);int trace_vfs_read(struct pt_regs *ctx, struct file *file, char __user *buf, size_t count, loff_t *pos) { struct data_t data = {}; u32 pid = bpf_get_current_pid_tgid() >> 32; data.pid = pid; data.ts = bpf_ktime_get_ns(); data.size = count; bpf_get_current_comm(&data.comm, sizeof(data.comm)); bpf_probe_read_str(&data.fname, sizeof(data.fname), file->f_path.dentry->d_name.name); events.perf_submit(ctx, &data, sizeof(data)); return 0;}"""# 加载 BPF 程序b = BPF(text=bpf_text)b.attach_kprobe(event="vfs_read", fn_name="trace_vfs_read")print("%-10s %-16s %-6s %-10s %s" % ("TIME(s)", "COMM", "PID", "SIZE", "FILE"))# 处理事件defprint_event(cpu, data, size): event = b["events"].event(data)print("%-10.6f %-16s %-6d %-10d %s" % ( event.ts / 1000000000.0, event.comm.decode('utf-8', 'replace'), event.pid, event.size, event.fname.decode('utf-8', 'replace') ))b["events"].open_perf_buffer(print_event)whileTrue:try: b.perf_buffer_poll()except KeyboardInterrupt: exit()运行效果:
$ sudo python3 filetrace.pyTIME(s) COMM PID SIZE FILE1234.567 nginx 1234 4096 access.log1234.568 python3 5678 1024 data.csv1234.569 mysqld 3456 16384 ibdata15. CPU 性能调优:从火焰图到调度优化
5.1 生成和分析火焰图
火焰图(Flame Graph)是可视化 CPU 使用情况的强大工具,y 轴表示调用栈深度,x 轴表示样本数量。
# 1. 安装 FlameGraph 工具$ git clone https://github.com/brendangregg/FlameGraph.git$ cd FlameGraph# 2. 采集数据$ sudo perf record -F 99 -a -g -- sleep 60# 3. 生成火焰图$ sudo perf script | ./stackcollapse-perf.pl > out.folded$ ./flamegraph.pl out.folded > cpu_flamegraph.svg# 4. 在浏览器中打开 SVG 文件查看$ firefox cpu_flamegraph.svg火焰图解读:
• 顶部宽条: 表示消耗 CPU 时间最多的函数,优化优先级最高 • 调用栈: 从下往上表示调用关系 • 颜色: 不同颜色无特殊含义,仅用于区分
5.2 CPU 调度调优
5.2.1 查看调度延迟
# 使用 perf sched 分析调度延迟$ sudo perf sched record -- sleep 10$ sudo perf sched latency5.2.2 调整调度器参数
# 查看当前调度器设置$ cat /proc/sys/kernel/sched*# 调整 CPU 亲和力(affinity)$ taskset -c 0-3 ./high_priority_app# 使用 nice 调整进程优先级$ nice -n -10 ./cpu_intensive_app # 高优先级$ nice -n 10 ./background_task # 低优先级# 使用 chrt 设置实时调度策略$ sudo chrt -f 99 ./realtime_app # FIFO 实时调度,优先级 995.3 中断优化
# 查看中断分布$ cat /proc/interrupts# 查看软中断统计$ cat /proc/softirqs# 使用 BCC 分析硬中断$ sudo hardirqs$ sudo hardirqs 5 3 # 5 秒采样,输出 3 次6. 内存与 I/O 优化实战
6.1 内存分析
6.1.1 使用 perf kmem 分析内核内存
# 记录内核内存分配$ sudo perf kmem record -- sleep 30# 生成统计报告$ sudo perf kmem stat6.1.2 使用 BCC 检测内存泄漏
# 监控内存分配和释放$ sudo memleak -p $(pgrep myapp)# 或跟踪内核内存泄漏$ sudo memleak6.1.3 页面缓存分析
# 使用 cachestat 监控页面缓存命中率$ sudo cachestat HITS MISSES DIRTIES HITRATIO BUFFERS_MB CACHED_MB 1234 123 45 90.92% 234 5678 2345 234 67 90.92% 234 5678# 清理页面缓存(谨慎使用)$ sudosync && echo 3 | sudotee /proc/sys/vm/drop_caches6.2 I/O 优化
6.2.1 使用 iostat 分析磁盘 I/O
# 实时显示磁盘 I/O 统计(每 2 秒)$ iostat -xz 2# 关键指标:# - %util: 设备利用率,> 60% 表示饱和# - await: 平均 I/O 等待时间(ms)# - svctm: 平均服务时间(ms)# - avgqu-sz: 平均队列长度6.2.2 使用 BCC 深入分析 I/O
# 分析 I/O 延迟分布$ sudo biolatency -D# 跟踪每个 I/O 请求$ sudo biosnoop# 查看 I/O 热点进程$ sudo biotop6.2.3 I/O 调度器选择
# 查看当前 I/O 调度器$ cat /sys/block/sda/queue/scheduler[mq-deadline] kyber bfq none# 临时切换调度器$ echo bfq | sudotee /sys/block/sda/queue/scheduler# 永久修改(添加到 /etc/default/grub)GRUB_CMDLINE_LINUX_DEFAULT="elevator=bfq"调度器选择建议:
• mq-deadline: 默认,适合大多数场景,提供良好的延迟和吞吐量平衡 • bfq: 适合桌面和交互式应用,提供最佳响应性 • kyber: 适合 NVMe 等高速设备 • none: 适合虚拟化场景(由宿主机管理 I/O)
6.3 网络 I/O 优化
# 使用 ss 查看连接状态$ ss -s# 使用 nstat 查看网络统计$ nstat# 使用 BCC 分析 TCP 重传$ sudo tcpretrans# 分析网络延迟$ sudo gethostlatency7. 生产环境最佳实践与避坑指南
7.1 性能监控检查清单
在生产环境进行性能分析前,检查以下事项:
• 内核版本: perf 和 eBPF 需要 Linux 4.1+,建议使用 5.x 或更新版本 • 调试符号: 安装内核调试包(kernel-debuginfo)以获得完整的栈追踪 • 帧指针: 确保内核编译时启用了 CONFIG_FRAME_POINTER=y• 权限: 性能分析通常需要 root 权限 • 采样频率: 避免过高的采样频率(建议 99Hz),以减少开销
7.2 常见陷阱
陷阱 1:忽略 frame pointer
# 问题:栈追踪不完整,显示 [unknown]# 解决:重新编译时添加 -fno-omit-frame-pointer$ gcc -O2 -fno-omit-frame-pointer -o myapp myapp.c陷阱 2:perf overhead 过高
# 问题:perf record 本身消耗大量 CPU# 解决:降低采样频率,或使用 BPF 进行聚合$ sudo perf record -F 49 -ag -- sleep 30 # 降低频率陷阱 3:在云环境中缺少 PMC 访问
# 问题:云实例(AWS/Azure/GCP)通常禁用性能监控计数器# 解决:使用软件事件或 tracepoints$ sudo perf stat -e cpu-clock,cache-misses -a sleep 5陷阱 4:eBPF 验证器限制
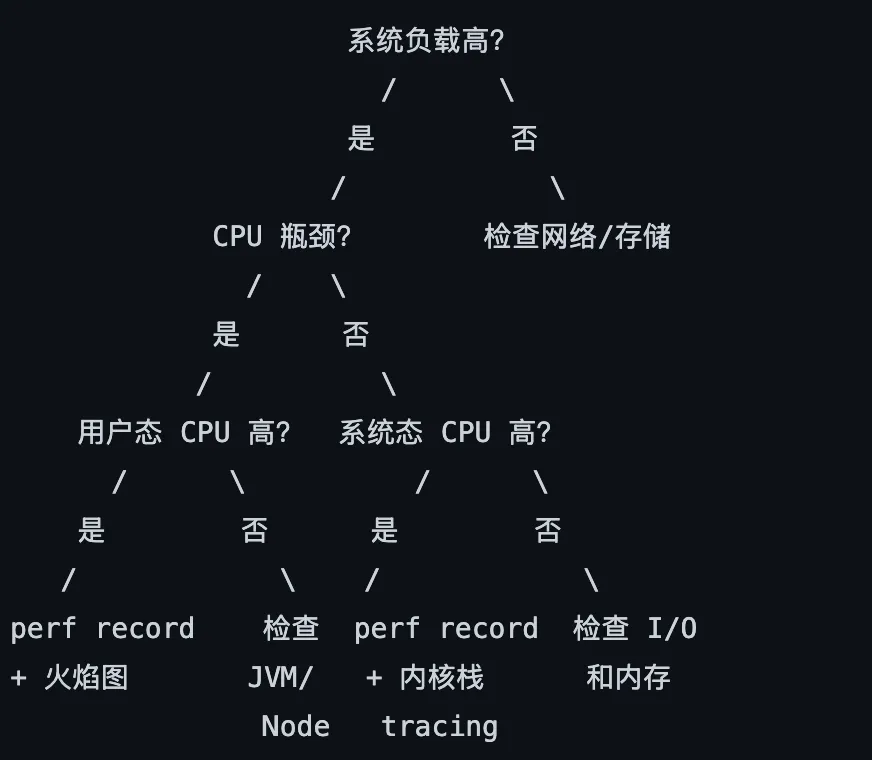
# 问题:复杂的 eBPF 程序被验证器拒绝# 解决:简化程序逻辑,或使用 BCC 提供的现成工具7.3 性能调优决策树
7.4 推荐工具组合
7.5 持续监控建议
# 使用 eBPF Exporter 将指标导出到 Prometheus# GitHub: https://github.com/cloudflare/ebpf_exporter# 关键指标告警规则示例groups:- name: linux_performance rules: - alert: HighCPUUtilizationexpr: 100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80for: 5m annotations: summary: "High CPU utilization on {{ $labels.instance }}" - alert: HighDiskLatencyexpr: rate(node_disk_io_time_seconds_total[5m]) > 0.8for: 5m annotations: summary: "High disk I/O utilization on {{ $labels.instance }}"
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- ArcGIS字段计算器|最全Python2.7字符串方法速查表
- ArcGIS字段计算器|最全Python2.7字符串方法速查表
- ArcGIS 字段计算器 Python 2.7 字符串方法速查(
- ArcGIS 字段计算器 Python 2.7 字符串方法速查(
- Python进阶:3 正则表达式——字符串的魔法棒
- Quandl,一个精益求精的python项目!
- GESP Python三级冲刺:攻克“密码验证”类题目的核心秘籍
- GESP Python三级冲刺:攻克“密码验证”类题目的核心秘籍
- 3python之testing模块模拟请求及流式处理
- Python节点教程:tk.Treeview节点的用法(增删修改+保存+加载)
