很多老工程师对 Python 有一个刻板印象:“Python 虽然好写,但跑起来肯定比 Tcl 或者 C++ 慢得多。”
如果你用写 Tcl 的思维去写 Python,那确实会很慢。处理 100 万个节点,新手写的脚本可能要跑 30 分钟,而高手写的脚本只需 3 秒。
这巨大的差异并不在于电脑配置,而在于你是否掌握了现代编程的终极心法——批量处理(Batching)与数据结构优化。今天,我们将揭秘如何打破性能瓶颈,让你的脚本“原地起飞”。
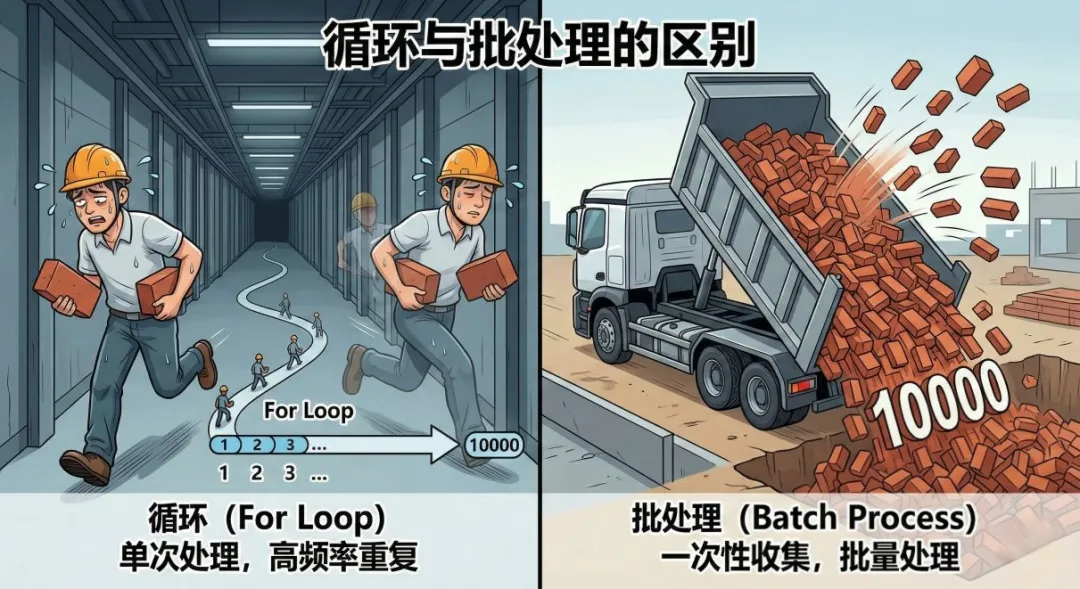
在处理网格时,最直觉的写法就是写一个 for 循环。比如我们要把 10000 个节点的 Z 坐标加上 5.0。❌ 新手写法(极慢):
nodes = hm.Collection(model, ent.Node)
for node in nodes:
# 每次调用 node.z,Python 都要通过底层接口和 HM 核心交互一次
node.z = node.z + 5.0
为什么慢?在脚本和 HyperMesh 底层数据库之间,存在一扇“门”。上面的代码相当于:你为了搬 10000 块砖,推开门拿一块,关上门;再推开门拿一块,再关上门……这 10000 次“开门/关门”的通信成本,占据了 99% 的时间。
2. 核心秘诀:向量化与批量化 (Vectorization / Batching)真正的高手,会把所有的指令打包,一次性发给 HyperMesh。
在 HyperMesh 2026 的 Python API 中,许多方法都原生支持集合操作 (Collection-based operations)。
✅ 高手写法(极快):
# 假设我们要移动一组节点
nodes = hm.Collection(model, ent.Node)
# 不要循环!直接对整个 Collection 调用平移方法
# 这一次操作在底层由 C++ 高速完成
model.translate(collection=nodes, vector=(0, 0, 1), distance=5.0)
性能差异:新手写法可能需要 10 秒,高手写法只需要 0.05 秒。这就是 200 倍的差距!心法:能用 Collection 整体操作的,绝对不要拆开写 for 循环。
3. 巧用 Python 的内置“神器”:Set 和 Dict
除了和 HM 交互的瓶颈,很多时候脚本慢是因为查找数据的方式不对。
假设你有一个包含 50 万个节点 ID 的列表,你想检查某个节点 ID 是否在里面。
❌ 列表查找 O(N)(慢):
# target_list 是一个 list: [1, 2, 3, ..., 500000]
if node.id in target_list: # 每次都要从头翻到尾,极其耗时
pass
✅ 集合/字典查找 O(1)(快如闪电):
# 将 list 转换为 set
target_set = set(target_list)
# set 的底层是哈希表,无论里面有 10 个还是 100 万个数据,查找时间永远是瞬间
if node.id in target_set:
pass
仅仅是加了一个 set() 转换,在嵌套循环中,你的脚本运行时间就能从几小时缩短到几秒钟。
历时 10 期,我们完成了一次华丽的蜕变。
从第一期的 “拥抱面向对象”,到 Collection 的魔法,再到 录制器生成代码、UI 界面交互、Pandas 数据处理,直到今天的 性能极限优化。
Python 在 HyperMesh 中的引入,绝不仅仅是换了一种语法。它是工程自动化的降维打击。
Tcl 让你成为了一个熟练的“操作员”,而 Python 将把你武装成一个真正的“软件开发者”和“数据科学家”。
不要害怕那些庞大的 API 文档,记住我们这 10 期教给你的核心逻辑:
万物皆对象 (Entity)。
批量处理靠集合 (Collection)。
不懂 API 就录制 (Recording)。
数据繁杂找 Pandas。
祝您在未来的自动化开发之路上一骑绝尘!
至此,我们的十期连载圆满结束!感谢您的持续关注和共同探索。