1. 冒泡排序(Bubble Sort)
算法思路
核心:相邻元素两两比较,将较大元素逐步“冒泡”到数组末尾,每一轮遍历确定一个最大值。时间复杂度O(n²),空间复杂度O(1),稳定排序,适合小规模数据。
Python手撕代码
def bublesort(a): n = len(a) # 外层循环:控制排序轮次,共n-1轮(最后一个元素无需比较) for i in range(n-1): # 内层循环:每轮遍历未排序部分,相邻元素比较交换 # 每轮结束后,最大元素已沉到末尾,无需再比较 for j in range(n-i-1): # 若前一个元素大于后一个,交换位置(冒泡核心) if a[j] > a[j+1]: a[j], a[j+1] = a[j+1], a[j] return a
2. 插入排序(Insert Sort)
算法思路
核心:将数组分为有序区和无序区,依次将无序区的元素插入到有序区的合适位置,类比整理扑克牌。时间复杂度O(n²),空间复杂度O(1),稳定排序,小规模数据效率优于冒泡。
Python手撕代码
def insertsort(a): n = len(a) # 外层循环:从第2个元素开始(第1个元素默认有序),遍历无序区 for i in range(1, n): key = a[i] # 取出当前要插入的元素(无序区第一个元素) j = i - 1 # 有序区的最后一个元素索引 # 内层循环:在有序区中找到插入位置,将大于key的元素后移 while j >= 0 and a[j] > key: a[j+1] = a[j] # 元素后移,腾出插入位置 j -= 1 a[j+1] = key # 将key插入到正确位置 return a
3. 选择排序(Select Sort)
算法思路
核心:每次从无序区中找到最小(或最大)元素,与无序区第一个元素交换,逐步扩大有序区。时间复杂度O(n²),空间复杂度O(1),不稳定排序,适合数据量小、对稳定性无要求的场景。
Python手撕代码
def selectsort(a): n = len(a) # 外层循环:控制有序区范围,共n-1轮(最后一个元素无需选择) for i in range(n-1): index = i # 初始化最小元素索引为无序区第一个元素 # 内层循环:遍历无序区,找到最小元素的索引 for j in range(i+1, n): if a[j] < a[index]: index = j # 更新最小元素索引 # 将最小元素与无序区第一个元素交换 a[i], a[index] = a[index], a[i] return a
4. 计数排序(Count Sort)
算法思路
核心:非比较排序,先统计数组中每个元素出现的次数,再根据次数重新构建有序数组。时间复杂度O(n+k)(k为数组最大值),空间复杂度O(k),稳定排序,适合元素范围不大的整数数组。
Python手撕代码(修正原代码笔误)
def countsort(a): n = len(a) if n == 0: # 处理空数组边界情况 return a max_v = max(a) # 找到数组中的最大值,确定计数数组长度 res = [0] * (max_v + 1) # 计数数组,存储每个元素出现次数 for num in a: # 修正原代码nums为a,避免变量名错误 res[num] += 1 tmp = [] # 存储最终有序数组 # 遍历计数数组,按元素大小依次加入结果 for i, r in enumerate(res): while r > 0: tmp.append(i) r -= 1 return tmp
5. 归并排序(Merge Sort)
算法思路
核心:分治思想,将数组递归拆分为两个子数组,分别排序后再合并,合并时保持有序。时间复杂度O(nlogn),空间复杂度O(n),稳定排序,适合大规模数据,兼顾效率和稳定性。
Python手撕代码
def mergesort(a): # 辅助函数:递归拆分+合并 def merge_sort_(a, res, start, end): if start >= end: # 递归终止条件:子数组长度为1(已有序) return # 分:将数组拆分为左右两个子数组,分别递归排序 mid = (start + end) // 2 merge_sort_(a, res, start, mid) merge_sort_(a, res, mid + 1, end) # 合:将两个有序子数组合并为一个有序数组 i, j, k = start, mid+1, start # i左子数组指针,j右子数组指针,k结果指针 while i <= mid and j <= end: # 比较左右子数组元素,将较小值存入结果数组 if a[i] <= a[j]: res[k] = a[i] i += 1 else: res[k] = a[j] j += 1 k += 1 # 将左子数组剩余元素存入结果 while i <= mid: res[k] = a[i] i += 1 k += 1 # 将右子数组剩余元素存入结果 while j <= end: res[k] = a[j] j += 1 k += 1 # 将结果数组的值复制回原数组(完成当前区间排序) for k in range(start, end + 1): a[k] = res[k] n = len(a) if n == 0: return a res = [0] * n # 辅助结果数组,存储合并后的有序数据 merge_sort_(a, res, 0, n-1) return a
6. 快速排序(Quick Sort)
算法思路
核心:分治思想,选择一个基准元素(pivot),将数组分为两部分,左部分小于基准,右部分大于等于基准,再递归排序左右两部分。时间复杂度O(nlogn)(最坏O(n²)),空间复杂度O(logn)(递归栈),不稳定排序,实际应用中效率最高。
Python手撕代码
def quicksort(a): # 辅助函数:分区操作,返回基准元素的最终位置 def partition(nums, left, right): pivot = nums[left] # 选择左边界元素作为基准 # 双指针交换,将小于基准的元素移到左边,大于等于的移到右边 while left < right: # 从右往左找,找到第一个小于基准的元素 while left < right and nums[right] >= pivot: right -= 1 nums[left] = nums[right] # 移到左指针位置 # 从左往右找,找到第一个大于基准的元素 while left < right and nums[left] <= pivot: left += 1 nums[right] = nums[left] # 移到右指针位置 nums[left] = pivot # 将基准元素放到最终位置 return left # 返回基准元素索引 # 辅助函数:递归排序 def sort_(nums, left, right): if left >= right: # 递归终止条件:子数组长度<=1 return mid = partition(nums, left, right) # 分区,得到基准位置 sort_(nums, left, mid-1) # 递归排序左半部分 sort_(nums, mid+1, right) # 递归排序右半部分 if len(a) == 0: return a sort_(a, 0, len(a)-1) return a
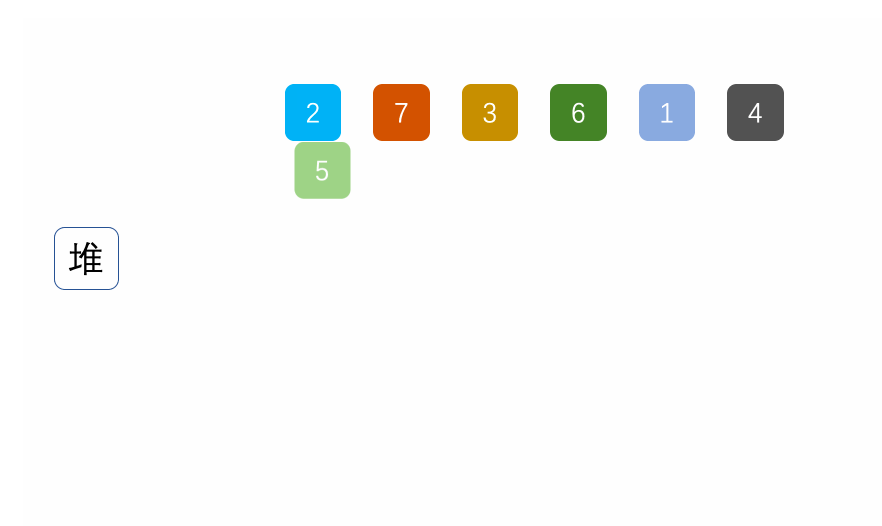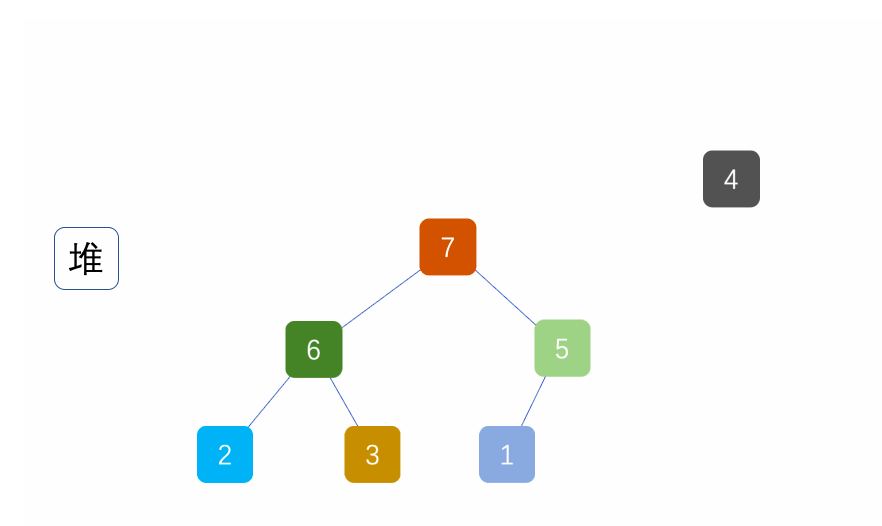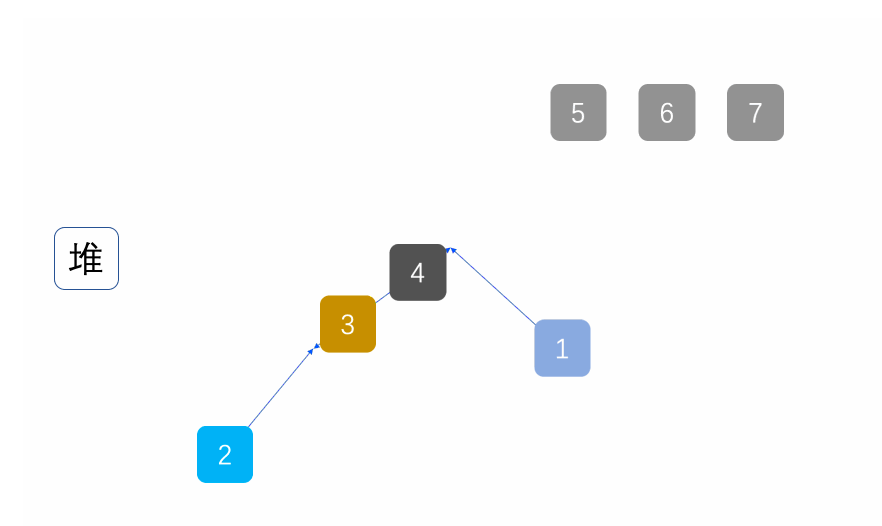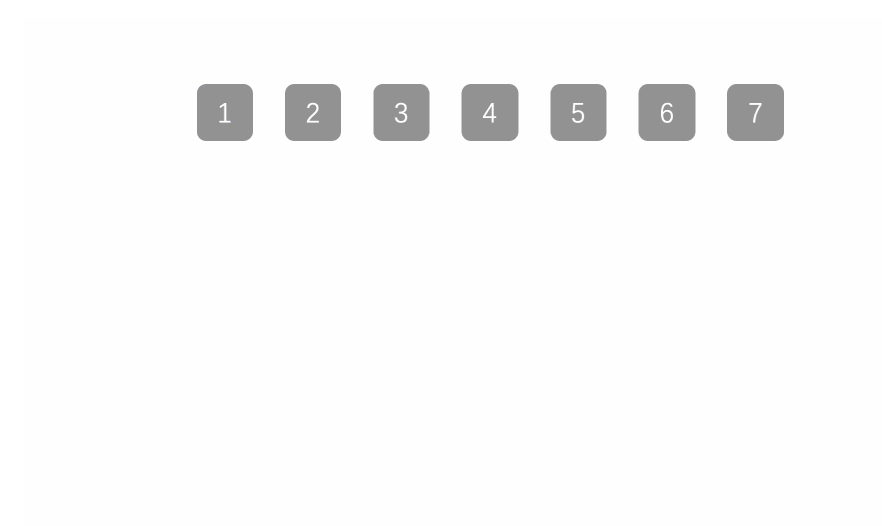
7. 堆排序(Heap Sort)
算法思路
核心:利用大顶堆(或小顶堆)的特性,每次取出堆顶元素(最大值),与数组末尾元素交换,再调整剩余元素为大顶堆,重复直至排序完成。时间复杂度O(nlogn),空间复杂度O(1),不稳定排序,适合大规模数据排序。
Python手撕代码
def heap_sort(arr): arr_copy = arr.copy() # 复制数组,避免修改原数组 n = len(arr_copy) if n <= 1: return arr_copy # 第一步:构建大顶堆(从最后一个非叶子节点开始调整) for i in range(n // 2 - 1, -1, -1): adjust_heap(arr_copy, i, n) # 第二步:逐个交换堆顶元素和末尾元素,然后调整剩余堆 for j in range(n - 1, 0, -1): # 交换堆顶(最大值)和当前未排序部分的最后一个元素 arr_copy[0], arr_copy[j] = arr_copy[j], arr_copy[0] # 对剩余未排序部分(0到j-1)重新调整为大顶堆 adjust_heap(arr_copy, 0, j) return arr_copy# 辅助函数:调整堆结构,使当前父节点满足大顶堆特性(父节点>子节点)def adjust_heap(arr, parent_idx, heap_size): # 保存父节点值(用于后续赋值,避免多次交换) temp = arr[parent_idx] # 左子节点索引(完全二叉树特性:左子节点=2*父节点+1,右子节点=2*父节点+2) child_idx = 2 * parent_idx + 1 # 循环遍历子节点,找到最大的子节点,完成堆调整 while child_idx < heap_size: # 如果右子节点存在,且右子节点值 > 左子节点值,切换到右子节点 if child_idx + 1 < heap_size and arr[child_idx] < arr[child_idx + 1]: child_idx += 1 # 如果子节点值 > 父节点值,将子节点值赋值给父节点(无需交换,先覆盖) if arr[child_idx] > temp: arr[parent_idx] = arr[child_idx] # 父节点索引更新为当前子节点索引,继续向下调整 parent_idx = child_idx child_idx = 2 * parent_idx + 1 else: # 父节点值 ≥ 子节点值,无需调整,退出循环 break # 将最初保存的父节点值赋值到最终位置 arr[parent_idx] = temp
LeetCode 16.16 部分排序
给定一个整数数组,编写一个函数,找出索引m和n,只要将索引区间[m,n]的元素排好序,整个数组就是有序的。注意:n-m尽量最小,也就是说,找出符合条件的最短序列。函数返回值为[m,n],若不存在这样的m和n(例如整个数组是有序的),请返回[-1,-1]。
示例:
输入: [1,2,4,7,10,11,7,12,6,7,16,18,19] 输出: [3,9]
提示:
0 <= len(array) <= 1000000
解题思路
核心:贪心思想,分两步找边界:
1. 从左到右遍历,记录当前最大值,若当前元素小于最大值,说明该元素在无序区间内,更新右边界end;
2. 从右到左遍历(或通过左遍历记录最小值),找到无序区间的最小元素,再从左到右找到第一个大于该最小值的元素,即为左边界start;
3. 若start仍为-1,说明数组有序,返回[-1,-1],否则返回[start, end]。时间复杂度O(n),空间复杂度O(1),高效适配大数据量。
Python解题代码
def part_sort(array): if len(array) <= 1: # 数组长度<=1,本身有序 return [-1, -1] max_v = float('-inf') # 记录左到右遍历的最大值 min_v = float('inf') # 记录无序区间的最小值 start = -1 # 无序区间左边界 end = -1 # 无序区间右边界 # 第一步:从左到右遍历,找无序区间的右边界end,同时记录无序区间的最小值min_v for i, value in enumerate(array): if max_v < value: max_v = value # 更新当前最大值(处于有序区间) if max_v > value: end = i # 出现比当前最大值小的元素,更新右边界 if min_v > value: min_v = value # 更新无序区间的最小值 # 第二步:从左到右遍历,找无序区间的左边界start(第一个大于min_v的元素) for i, value in enumerate(array): if min_v < value: start = i break # 若start仍为-1,说明数组有序(min_v未更新,即无无序元素) return [start, end] if start != -1 else [-1, -1]
例题来自力扣网https://leetcode-cn.com/

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
