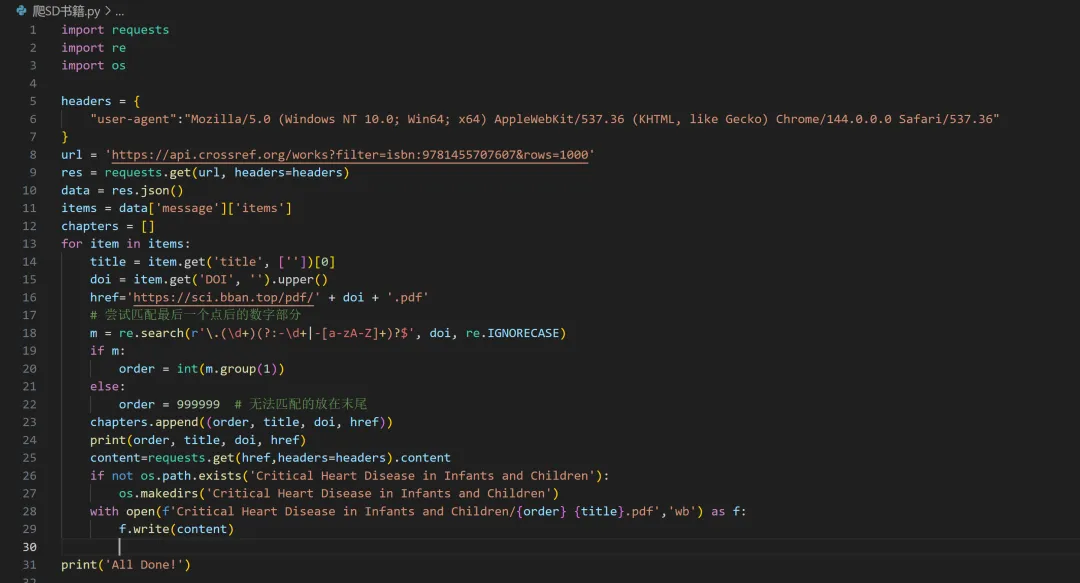
如何用python下载ScienceDirect的原版书籍
最近在查阅文献的时候,无意间搜到了一本书的某个章节,里面的插图很漂亮,就想把整本书白嫖下来。因为对爬虫感兴趣,我曾系统学习过python,水平不敢说很高,但有一定的爬虫基础。不过好久不玩了,有些生疏,需要回忆一下,哈哈。价格不能说很贵,但想让我掏钱的话是不可能的。那么如何免费下载整本书呢?我的思路是这样的:ScienceDirect(以下简称SD)把每本书籍按章节分为不同的pdf文件,而每个pdf文件都有一个doi(文献标识符),根据doi从sci-hub下载原文。看了一下,这本书一共有76章,这要一个个下不得累死,于是决定试试用python批量下载。用python试着提取每一个章节的title和doi,但SD的反爬太难搞了,没成功。只好另辟蹊径,寻找其他办法。Crossref
Crossref 是一家非营利性开放数字基础设施组织,服务于全球学术研究社区。它是全球最大的International DOI Foundation数字对象唯一标识符(DOI)注册机构,负责持久记录并连接学术成果的开放元数据。通过其系统,学术出版物、数据集、基金项目等研究对象得以相互链接、引用与追踪。
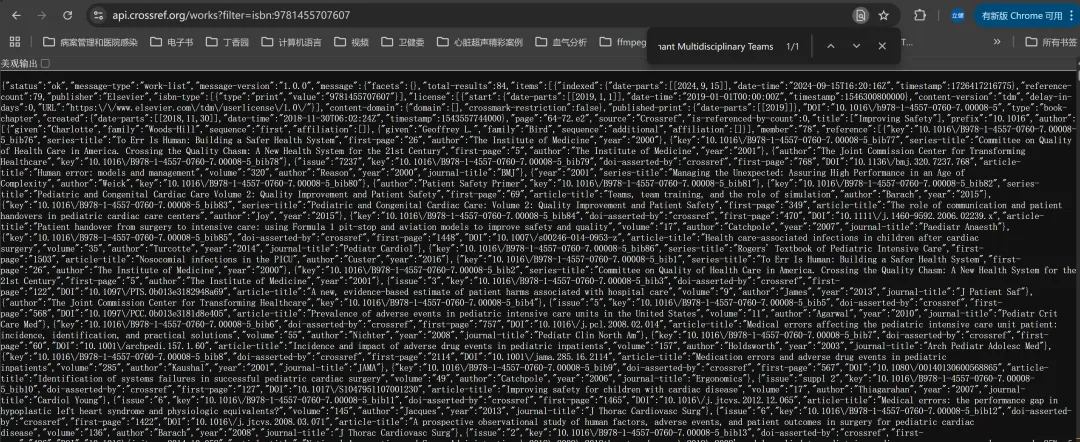
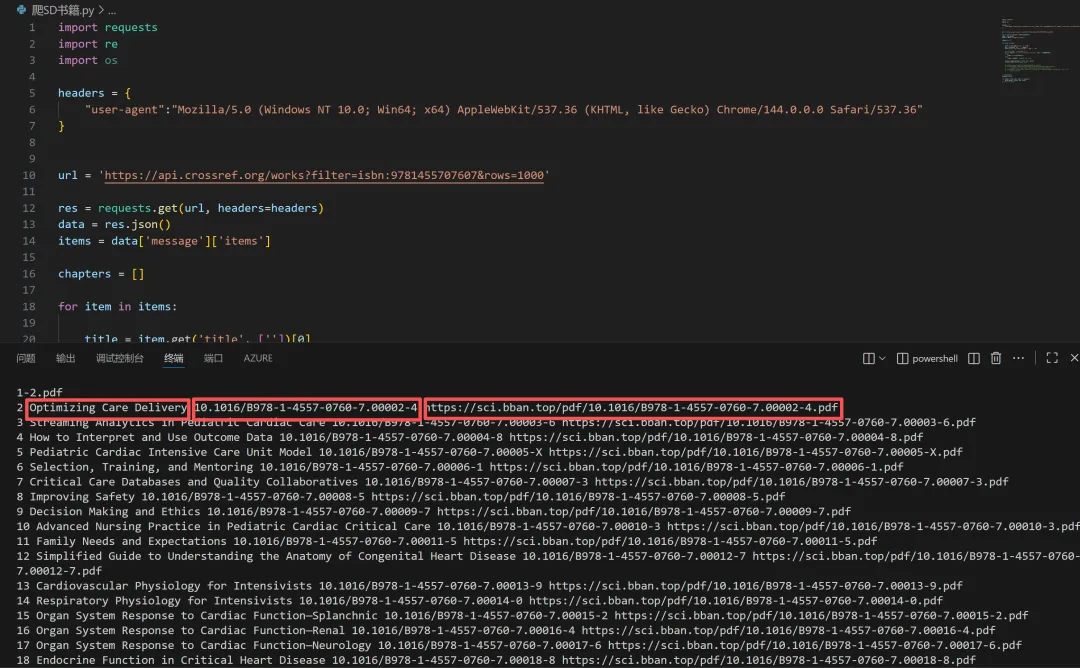
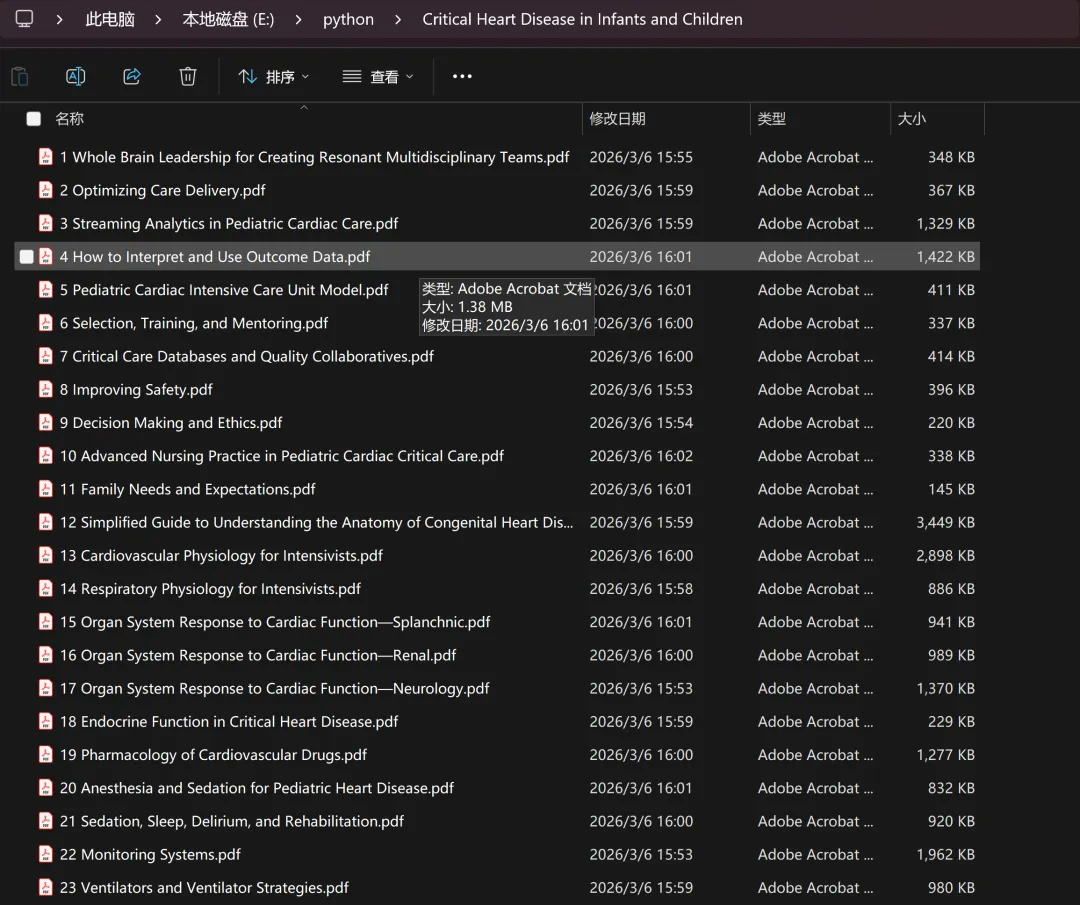
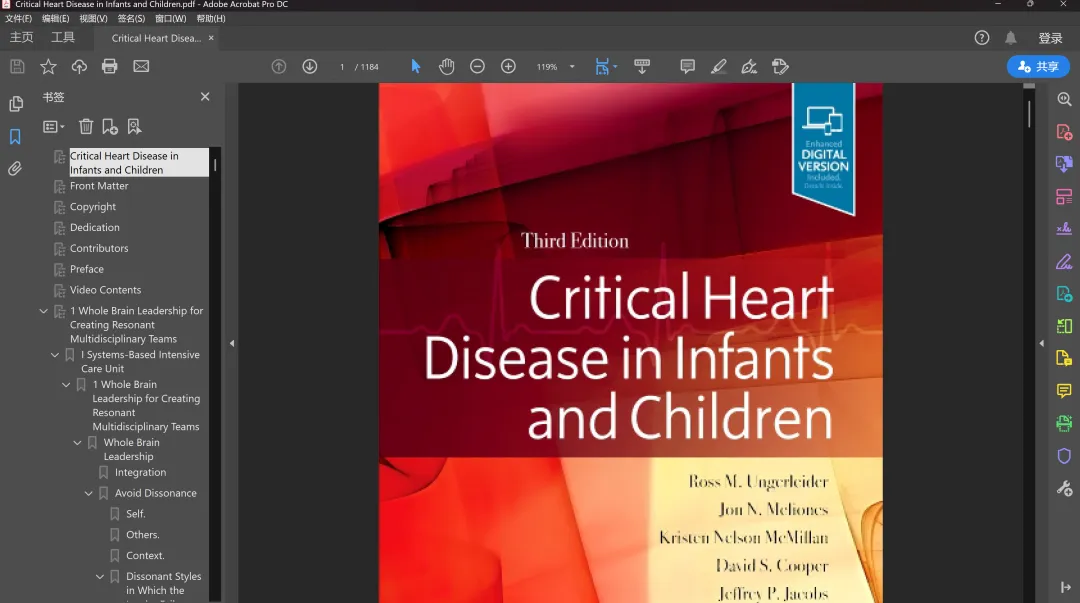
根据这本书的ISBN(SD网站上有)可以查阅到这本书的章节信息,类似下面的信息。不要被密密麻麻的数据吓到,这不过是json结构化数据,用python可以轻易提取到每个章节的title和doi,见下图:sci-hub的pdf文章的下载地址其实是有规律的,下载地址隐含着doi信息,所以根据doi可以生成下载地址。好了,现在我们已经批量拿到了每个章节的序号、title和doi,剩下的就交给python好了。很快,全部70多个章节就下载完了,然后用acrobat合并章节就可以了。