说实话,LetCode有手就行!Python | 算法设计与分析(03)| 归并排序复刻:链表排序LCR 077. 排序链表一题吃透分治
很多同学一看到“排序链表”,第一反应是:
小华学长也是,但能不能做?肯定是能的。但这题真正想考的,不是你会不会调库,而是你会不会把 归并排序 + 分治思想 用到链表上。
这也是算法课里非常典型的一类题:
数组适合随机访问,链表适合拆分与合并。
题目重述:
给定链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表。
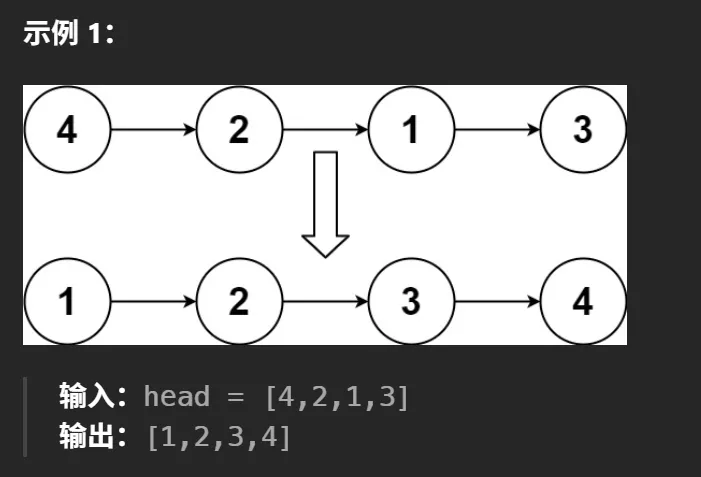
示例 1
输入:head = [4,2,1,3]输出:[1,2,3,4]
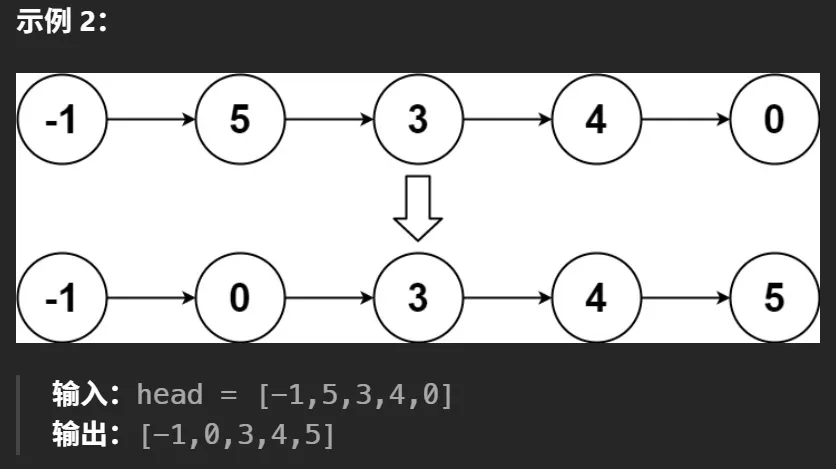
示例 2
输入:head = [-1,5,3,4,0]输出:[-1,0,3,4,5]
示例 3
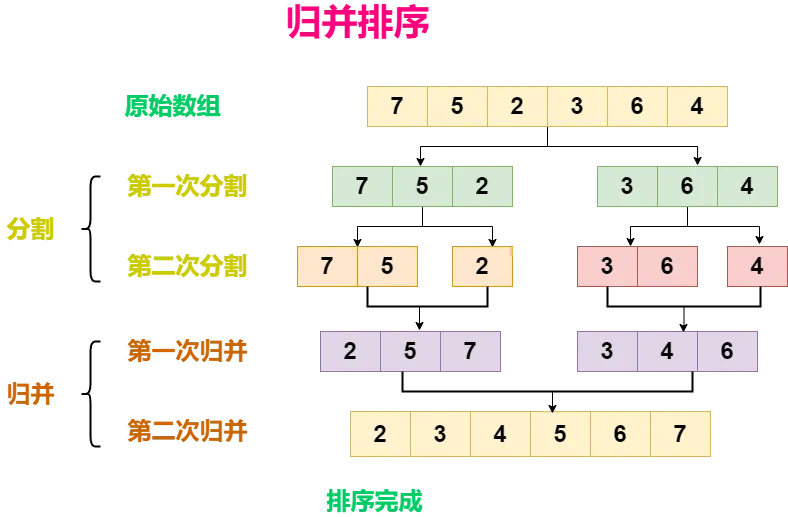
这题为什么用归并排序?
因为链表不适合快速排序那种“按下标交换”的操作,但非常适合归并排序的两步:
从中间断开,分成左右两半
递归排序后合并
所以整题思路可以概括成一句话:
先分,再排,最后合。
核心思路:
第一步:快慢指针找中点
用 slow 和 fast 找链表中点:
当 fast 走到末尾时,slow 基本就在中间。
然后把链表从中间断开:
mid = slow.nextslow.next = None
第二步:递归排序左右两部分
对左半链表、右半链表分别递归调用排序函数。
第三步:合并两个有序链表
这一步和“合并两个有序链表”是同一个模板题。谁小接谁,最后把剩余部分接上去即可。
Python 实现:
# Definition for singly-linked list.class ListNode: def __init__(self, val=0, next=None): self.val = val self.next = nextclass Solution: def sortList(self, head): # 递归终止:空链表 or 只有一个节点 if not head or not head.next: return head # 1. 快慢指针找中点 slow, fast = head, head while fast.next and fast.next.next: slow = slow.next fast = fast.next.next # 2. 从中间断开 mid = slow.next slow.next = None # 3. 递归排序左右两部分 left = self.sortList(head) right = self.sortList(mid) # 4. 合并两个有序链表 return self.merge(left, right) def merge(self, l1, l2): dummy = ListNode() cur = dummy while l1 and l2: if l1.val <= l2.val: cur.next = l1 l1 = l1.next else: cur.next = l2 l2 = l2.next cur = cur.next cur.next = l1 if l1 else l2 return dummy.next
为什么这段代码是对的?
因为它完整符合归并排序的结构,只要 merge 是对的,整个递归结构就是成立的:
分:找到中点,把链表拆成两半
治:递归排序左边和右边
合:把两个有序链表合并成一个有序链表
复杂度分析
(1)时间复杂度为O(nlogn)
原因:
1.每一层递归都会遍历并合并所有节点一次,代价是 O(n)
2.递归层数大约是 log n
所以,总复杂度是:O(n log n)
(2)空间复杂度也为O(nlogn)
严格说递归会占用栈空间,所以是 O(log n)。
这题最容易错的3个点
1. 忘记断链
这一句不能漏,如果不断开,递归会一直连着原链表,最后很容易死循环:
2. 中点找错导致无法收缩
循环条件建议写成下面这样,这样 slow 会停在前半段尾部,便于断开:
while fast.next and fast.next.next:
3. merge 时指针推进顺序写乱
接完节点后,记得这样写,否则链表不会正确向后连接:
这题表面上是在排链表,本质上考的是:
你会不会把归并排序写到链表结构里。
所以真正该记住的不是“这题答案”,而是这套套路:
以后只要遇到 链表排序、链表分治、链表有序合并,都能直接套。很多同学第一次写这题,错的都不是思路,而是断链和边界。
小华学长这里留下一个问题:
为什么链表排序更适合归并,而不是快排?
想明白这个问题,这题就真的吃透了。
guan注小华学长,获取下期预告:
Python | 算法设计与分析(04)| 逆序对实战:归并排序不只是排序,还能边排边统计