写在前面
设备偶现频繁出现“诡异”的卡顿,系统负载忽高忽低,但内存和CPU看起来都挺充裕。查看free -h,第一句:“Swap用了不少啊。”然后随手把vm.swappiness调成了0,重启了应用。问题确实“缓解”了,但我心里一直有个疙瘩:Swap到底是什么?它到底该不该开?开了之后怎么管?调成0真的正确吗?
带着这些问题,我断断续续啃了一些内核代码和文档,踩过一些坑,也有了一些自己的理解。今天想把这些内容整理出来,希望能帮到和曾经的我一样困惑的朋友。
这篇文章不是“标准答案”——实际上Linux内存管理本身就没有标准答案。我们尽量把Swap涉及的各个概念、原理讲透,至于怎么配置,你得根据你自己的场景去判断。
第一章:Swap的前世今生
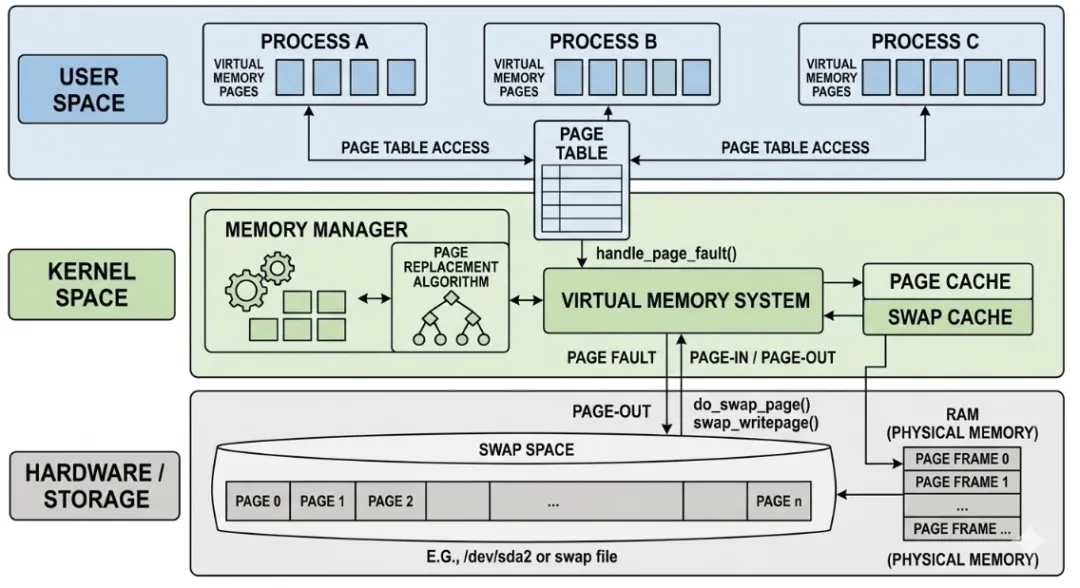
swap交换空间架构图
1.1 为什么要Swap?
故事要从计算机的资源分层说起。
CPU的速度是纳秒级,内存是微秒级,而磁盘是毫秒级——这几个数量级的差距,决定了现代操作系统必须有一套复杂的存储层次体系。当物理内存(RAM)不够用时,我们不能让系统直接崩溃,必须有个后备方案。
这就是Swap的初衷——把暂时不用的内存数据挪到磁盘上,腾出空间给更需要的进程。
听起来挺简单?但实际上这里有个根本性的矛盾:内存是为了快而存在的,磁盘天生就慢。如果把内存数据交换到磁盘,那访问这些数据时就要承受磁盘的慢。这就像为了腾出客厅的空间,把家具搬到了邻居家——每次要用的时候还得去敲门借回来。
所以Swap本质上是在容量和速度之间做权衡,是一种用时间换空间的无奈之举。
1.2 不只是“后备内存”
随着Linux内核的演进,Swap的角色也在变化:
早期内核(2.4之前):内存普遍较小,Swap是必需品,没有Swap系统很容易OOM。
2.6内核时期:内存逐渐变大,但Swap依然重要,特别是支持休眠(suspend to disk)需要Swap。
4.x内核至今:内存越来越大,Swap的角色开始分化——有人主张完全禁用,有人主张合理利用。Kubernetes社区甚至长期要求节点禁用Swap,不过从v1.22开始,情况又有所松动。
1.3 匿名页和文件页:理解Swap的关键
要真正理解Swap,必须先分清两种内存页:
文件页(File-backed Pages):这部分内存的内容对应着磁盘上的某个文件,比如程序代码、共享库、文件缓存。如果你打开一个可执行文件,它被加载到内存里,这部分就是文件页。特点是干净的文件页可以直接丢弃,需要时再从磁盘读回来;脏的文件页需要先写回磁盘再丢弃。
匿名页(Anonymous Pages):这部分内存没有对应的磁盘文件,比如进程的堆、栈,用malloc()分配的内存,mmap映射的匿名内存。这些数据只存在于内存中,如果想回收它们,必须找个地方存起来——这个“地方”就是Swap空间。
这是理解Swap最重要的一步:
文件页的回收不涉及Swap,匿名页的回收才需要Swap。
如果你把Swap完全禁掉,内核回收内存时只能处理文件页,匿名页就动不了。当内存压力持续增大,匿名页占满内存,文件页又被回收得差不多时,就只能OOM杀进程了。
第二章:Swap工作机制深度解析
2.1 交换区:Swap的物理载体
先搞清楚概念:我们常说的Swap,其实有两个层面的含义:
一个系统可以同时有多个交换区,每个交换区有自己的优先级。内核会优先使用优先级高的交换区。
交换分区 vs 交换文件
创建交换文件的经典操作:
# 创建4GB交换文件sudo fallocate -l 4G /swapfile # 速度快,但某些文件系统不支持# 或者用dd(兼容性好)sudo dd if=/dev/zero of=/swapfile bs=1M count=4096# 设置权限(重要!)sudo chmod 600 /swapfile# 格式化为交换空间sudo mkswap /swapfile# 启用sudo swapon /swapfile# 永久启用(添加到/etc/fstab)echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
2.2 页表与交换项:内存地址如何映射到磁盘
当匿名页被换出时,内核并不是简单地把数据写出去就完事。最关键的一步是修改页表项(Page Table Entry, PTE)。
正常情况下,PTE指向物理内存页帧号(PFN)。当一个页被换出后,PTE被替换为一个交换项(Swap Entry),里面包含两个关键信息:
交换区ID:这个页被换到了哪个交换区
交换偏移量:在这个交换区中的哪个位置(哪个槽位)
这样,当进程再次访问这个地址时,CPU触发缺页异常(Page Fault),缺页异常处理程序读取PTE中的交换项,就能知道去哪块磁盘把数据读回来。
这个过程有点像图书馆的索引系统:书不在书架上(内存),但在索引卡(页表)上记录了它在哪个仓库(交换区)的哪个架位(偏移量),需要时可以去取。
2.3 Swap Cache:避免不必要的回读
换出之后,内存页的内容实际上还保留在内存中(直到被覆盖),内核会把它标记为Swap Cache。这是一种优化:如果这个页在换出后很快又被访问,而它的物理内存页还没被复用,就可以直接恢复,避免从磁盘读回。
只有当内存压力持续,这部分Swap Cache的物理页被回收后,数据才真正只存在于磁盘上。
2.4 LRU链表:哪些页该换出
内核怎么知道该换出哪些页?答案是LRU(Least Recently Used)算法,但在实现上用了更精细的双链表结构:活跃链表和不活跃链表。
对于匿名页和文件页,内核分别维护了两套LRU链表:
匿名页活跃链表
匿名页不活跃链表
文件页活跃链表
文件页不活跃链表
回收时,扫描程序会:
先从活跃链表中找出最近不常用的页,移到不活跃链表
从不活跃链表的尾部开始,尝试回收或换出
这个机制保证了那些经常被访问的页可以留在内存里,而不活跃的页被优先处理。
第三章:swappiness的真面目
3.1 最常见的误解
说到Swap调优,大家第一个想到的肯定是vm.swappiness。最常见的说法是:“这个值代表系统使用Swap的百分比,值越大越爱用Swap,越小越不爱用。”
这种说法不准确,甚至有点误导。
3.2 swappiness到底控制什么
准确地说,swappiness控制的是内核回收内存时,在“回收匿名页”和“回收文件页”之间的偏好。
当内存压力达到一定程度,内核需要腾出空间,它有两个选择:
swappiness的值就是用来告诉内核,更倾向于选哪个。在较新的内核中,swappiness的范围是0-200(旧内核是0-100):
值越高:越倾向于回收匿名页(即使用Swap)
值越低:越倾向于回收文件页(即尽可能保留匿名页)
默认值通常是60,表示在同等条件下,回收文件页的比例会稍高于匿名页。swappiness设为100时,匿名页和文件页具有完全相同的回收优先级。
3.3 典型误区澄清
误区1:swappiness=0意味着禁用Swap错。即使设为0,当内存极度紧张、文件页又回收得差不多时,内核依然会使用Swap。真正的禁用Swap是swapoff -a。
误区2:swappiness控制Swap使用的快慢错。它不直接控制Swap的触发时机,只控制内存回收时的倾向性。
误区3:值越小性能越好不一定。如果系统有大量文件缓存需求(比如数据库),适当提高swappiness让匿名页早点换出,反而能为文件缓存腾出更多内存,可能提升整体性能。
3.4 调整方法
# 查看当前值sysctl vm.swappiness# 临时修改(重启失效)sudo sysctl vm.swappiness=10# 永久修改echo "vm.swappiness=10" >> /etc/sysctl.confsudo sysctl -p
第四章:kswapd与水印机制
4.1 内存回收的两种方式
内核回收内存主要有两种途径:
4.2 内存水印(Watermark)
内核为每个内存区域(zone)定义了三个水位线:
pages_min:最低水位。空闲内存达到这个值时,内存压力非常大。
pages_low:低水位。低于这个值时,kswapd被唤醒开始回收。
pages_high:高水位。高于这个值时,kswapd可以休眠。
这个机制有点像家里的米缸:
4.3 相关内核参数
除了swappiness,还有几个关键参数影响Swap行为:
在Kubernetes场景下,合理调整这两个参数可以有效避免内存压力陡增时Pod被提前驱逐。
第五章:Swap多大合适?
5.1 历史经验值
早年间的教科书上常写:Swap应该是物理内存的2倍。这个建议在内存只有几百兆的年代是有道理的——那时的内存真的很小,Swap是必要的补充。
但现在,这个建议已经过时了。
5.2 现代系统的参考建议
综合多个来源和实际经验,我整理了一个相对合理的参考:
关键考量因素:
是否有休眠需求:如果要用“suspend to disk”,Swap至少要和内存一样大。
磁盘类型:如果是SSD甚至NVMe,Swap性能好很多,可以适当大一些;HDD的话,Swap太大会严重影响性能。
应用特性:数据库、Java应用等内存大户,如果偶尔有内存峰值,Swap可以留大一些作为缓冲。
5.3 我的原则
我个人的原则是:宁缺毋滥,够用就好。
Swap不是越多越好。太大会让人忽视内存不足的问题,也浪费磁盘空间。我更倾向于合理监控,如果Swap使用率长期超过50%,应该考虑升级内存,而不是扩大Swap。
第六章:Swap对系统的深层影响
6.1 性能的双刃剑
Swap是一把双刃剑:
正面:在内存不足时,防止系统崩溃,提供缓冲。
负面:速度差异巨大。从NVMe SSD读数据延迟是0.1ms级别,HDD是10ms级别,而内存是纳秒级别。这中间差了几个数量级。如果应用程序的工作集(working set)被大量换出,性能会直接断崖式下跌,这就是所谓的抖动(Thrashing)。
6.2 I/O与CPU的连锁反应
当系统频繁Swap时,你会发现:
我在生产环境见过一次:某台机器Swap用了不到2GB,但iowait持续30%以上,业务接口耗时从50ms飙升到3秒。后来发现是因为某个进程内存泄漏,大量匿名页被换出,频繁的换入换出把磁盘拖垮了。
6.3 与OOM Killer的关系
很多人认为有了Swap就不会触发OOM Killer。错。
OOM Killer触发的前提是:内核尝试回收内存失败,仍然无法满足内存分配请求。如果Swap用完了,或者磁盘I/O太慢导致回收无法及时完成,OOM Killer依然会被唤醒。
更糟糕的是,当系统陷入“频繁Swap”状态时,OOM Killer可能反应迟钝,或者杀掉错误的进程。
6.4 现代存储设备的改变
SSD的普及让Swap的“罪名”减轻了一些。毕竟SSD的随机读写性能比HDD好太多。
但即便如此,内存和SSD之间仍有几个数量级的差距。而且频繁的Swap写入确实会影响SSD寿命——虽然现代SSD的寿命已经很长,但Swap依然属于写放大比较严重的负载。
如果你不得不用Swap,尽量把它放在SSD上。
第七章:如何定位和分析Swap问题
7.1 基础监控命令
free -h # 重点关注Swap行的used值
swapon -scat /proc/swaps- **实时监控Swap活动**:```bashvmstat 1# si: swap in, so: swap out
7.2 进程层面分析
smem -rs swap
VmSwap: 1024 kB
每个进程匿名页换出情况。
7.3 高级分析
pswpin, pswpout
记录总的交换进/出次数。
分析Swap性能瓶颈时,一定要结合iowait、load average、进程内存占用趋势一起看,否则容易误判。
第八章:调优策略总结
确保物理内存够用:Swap只是缓冲,不能替代内存不足。
合理设置swappiness:工作负载是文件缓存密集型还是匿名页密集型,设置不同的值。
优先使用SSD:避免HDD Swap成为性能瓶颈。
监控Swap使用率:长期占用高,应排查内存泄漏或增容。
结合水印参数调整:vm.min_free_kbytes和watermark_scale_factor可微调kswapd触发时机。
合理配置Swap大小:大多数现代系统不需要超过物理内存两倍,甚至固定8~32GB即可。
容器场景:K8s推荐节点禁用Swap或开启--fail-swap-on=false,确保调度准确。
第九章:总结与实践建议
Swap是内存管理的后备机制,本质是用磁盘换内存。
匿名页是Swap的核心对象,文件页一般不进入Swap。--这里你应该关注
swappiness影响内核回收倾向,而不是直接控制Swap使用速度。
kswapd和水印机制让内核尽量异步回收,减少阻塞。
Swap过多或过少都有问题,需根据业务场景合理配置。
现代SSD环境下,Swap速度快,但仍然远低于RAM,频繁Swap会影响性能。
日常运维中,监控Swap使用率、I/O、负载和进程占用是必不可少的。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
