删掉 40% 的代码,8 个模式重构 Python 逻辑
- 2026-06-28 02:51:24
很多python开发者都有一种错觉,代码量越多,对系统的控制力就越强(就像写作文,写得越长老师就越会给高分一样)。实际上,多余的逻辑判断、繁重的样板代码和过度嵌套的函数往往是系统维护难、排查 Bug 慢的根源。
资深开发者更倾向于编写精简且职责清晰的代码。通过以下 8 个 Python 编程模式,可以有效减少代码冗余,提升项目的可维护性。

使用 Data Classes 替代手动建模
在存储数据对象时,传统的类定义需要手动编写 __init__、__repr__ 等方法。这产生了大量重复的样板代码。
旧的写法
class Product: def __init__(self, name, price, stock): self.name = name self.price = price self.stock = stock def __repr__(self): return f"Product(name={self.name}, price={self.price}, stock={self.stock})"推荐写法
from dataclasses import dataclass@dataclassclass Product: name: str price: float stock: int通过 dataclass 装饰器,Python 会自动处理初始化和对象表示。这种方式让代码意图更明确,即这个类主要用于承载数据。
使用提前返回扁平化逻辑
深层嵌套的 if 语句通常被称为嵌套地狱。采用提前返回(Early Returns)模式可以保持主逻辑在代码最左侧,增加可读性。
旧的写法
def process_payment(account): if account is not None: if account.is_active: if account.balance >= 100: return execute_transaction(account) return False推荐写法
def process_payment(account): if not account or not account.is_active: return False if account.balance < 100: return False return execute_transaction(account)用推导式代替循环
列表或字典推导式提供了一种声明式的编程风格。相比于先创建空容器再遍历填充,推导式能直接描述数据的转换过程。
旧的写法
prices = [10, 25, 40, 60]expensive_prices = []for p in prices: if p > 30: expensive_prices.append(p * 0.9)推荐写法
prices = [10, 25, 40, 60]expensive_prices = [p * 0.9 for p in prices if p > 30]让 Python 大声报错
防御性编程有时会过度。到处使用 if key in data 或者空 try-except 会掩盖真实的逻辑错误。
旧的写法
def get_config(settings, key): if key in settings: return settings[key] return None推荐写法
def get_config(settings, key): return settings[key]直接访问键值。如果键不存在,程序抛出异常能让人在开发阶段迅速定位配置缺失的问题,而不是带着一个 None 值继续运行到更深层的业务逻辑里。
使用 defaultdict 消除键检查
在统计频率或对数据分组时,手动判断键是否存在不仅繁琐,还容易出错。
旧的写法
logs = ["error", "info", "error", "debug"]counts = {}for level in logs: if level not in counts: counts[level] = 0 counts[level] += 1推荐写法
from collections import defaultdictlogs = ["error", "info", "error", "debug"]counts = defaultdict(int)for level in logs: counts[level] += 1defaultdict 会在键缺失时自动初始化默认值,从而省去了所有的逻辑分支。
利用 any 和 all 简化判断
检查集合中是否存在符合条件的元素时,不需要手动维护布尔标志位。
旧的写法
orders = [order1, order2, order3]has_pending = Falsefor o in orders: if o.status == "pending": has_pending = True break推荐写法
has_pending = any(o.status == "pending" for o in orders)使用 zip 合并迭代对象
同时处理两个相关的列表时,下标索引操作既不直观也容易导致越界。
旧的写法
headers = ["ID", "Name"]rows = [101, "Alice"]data = {}for i in range(len(headers)): data[headers[i]] = rows[i]推荐写法
data = dict(zip(headers, rows))zip 将多个序列打包成元组流,避免了对长度的硬编码。
使用 set 快速去重
在处理数据集合时,去重是一个高频需求。利用集合的特性比手动遍历检查效率更高。
旧的写法
tags = ["python", "code", "python", "dev"]unique_tags = []for t in tags: if t not in unique_tags: unique_tags.append(t)推荐写法
unique_tags = list(set(tags))高效环境助力 Python 开发
掌握了上述编程模式后,高效的开发环境同样不可或缺。地球人都知道,处理不同项目间的 Python 版本冲突和路径配置费的时间可不少。
而有了 ServBay 之后情况就不同了,它支持一键安装 Python 环境,省去了手动编译和配置路径的麻烦。
ServBay 还能支持多个 Python 版本同时并存。在处理老旧项目的维护以及新项目的技术栈升级时,开发者可以根据需求灵活切换不同的 Python 版本,而无需担心环境冲突。
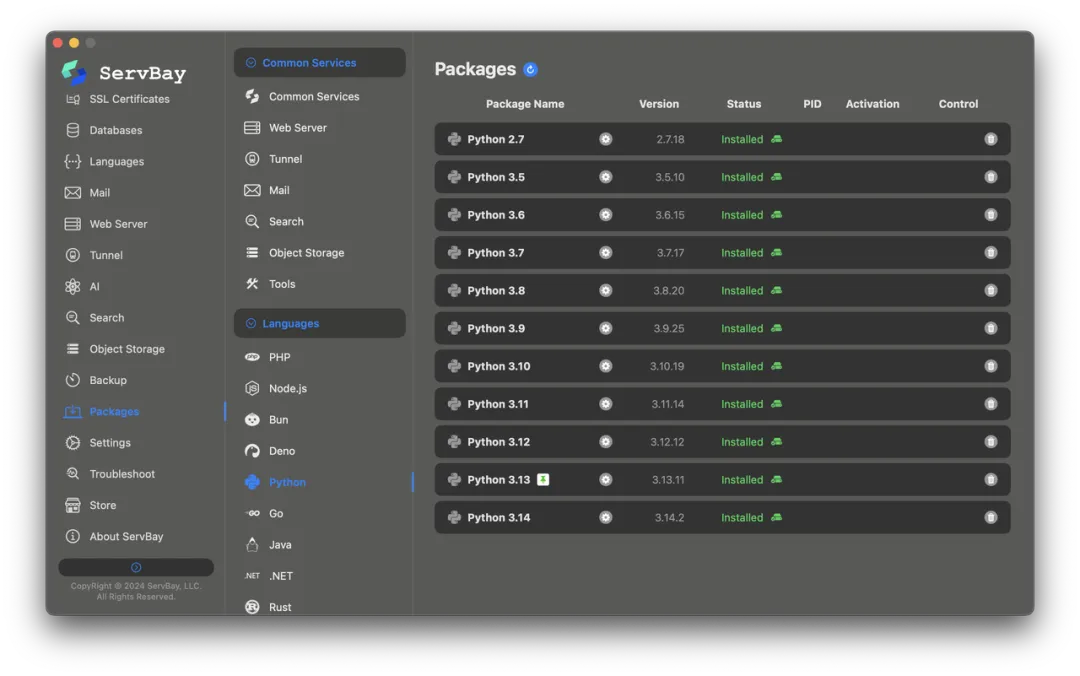
这种隔离且统一的管理方式,让开发者可以将精力集中在代码逻辑优化上,而不是环境调试中。
总结
话说多错多,代码同样。写的代码越少,出错的机会就越少,这样维护起来才会更加容易。
#ServBay #python #python环境 #python变量
欢迎关注ServBay 服务号👇

立即下载ServBay,加速你的工作效率

