【Qwen3-Max】太棒了!欢迎来到 【跟着AI学Python】进阶第3天:迭代器与生成器!🎉今天我们将揭开 Python 中高效处理数据流的秘密武器 —— 迭代器(Iterator)和生成器(Generator)!
💡 核心价值:
🎯 今日目标
✅ 理解 迭代器协议(__iter__, __next__)✅ 掌握 生成器函数(yield)的使用✅ 区分 列表推导式 vs 生成器表达式✅ 实战:用生成器优化大数据处理
📘 一、核心概念速览
| | | |
|---|
| 列表(List) | | | |
| 迭代器(Iterator) | | | |
| 生成器(Generator) | | | |
🔑 关键区别:
- 列表:
[x*2 for x in range(10)] → 立即创建完整列表 - 生成器:
(x*2 for x in range(10)) → 只在需要时计算
🔧 二、实践 1:实现斐波那契数列生成器
方式 1:普通函数(内存爆炸 ❌)
def fib_list(n): """返回前 n 项斐波那契数列(列表)""" a, b = 0, 1 result = [] for _ in range(n): result.append(a) a, b = b, a + b return result# 问题:fib_list(1000000) 会占用大量内存!
方式 2:生成器函数(内存友好 ✅)
def fib_generator(): """无限斐波那契数列生成器""" a, b = 0, 1 while True: yield a # 暂停并返回当前值 a, b = b, a + b# 使用示例fib = fib_generator()print(next(fib)) # 0print(next(fib)) # 1print(next(fib)) # 1print(next(fib)) # 2# 或用 for 循环(安全停止)for i, num in enumerate(fib_generator()): if i >= 10: # 只取前10项 break print(num)
✅ 优势:
🔧 三、实践 2:自定义迭代器类
实现一个 倒序计数器,展示迭代器协议:
class Countdown: def __init__(self, start): self.start = start def __iter__(self): """返回迭代器对象(通常就是自己)""" return self def __next__(self): """返回下一个值,结束时抛出 StopIteration""" if self.start <= 0: raise StopIteration self.start -= 1 return self.start + 1# 使用for num in Countdown(3): print(num) # 输出: 3, 2, 1
🔍 对比生成器:生成器更简洁,但自定义迭代器适合复杂状态管理。
🔧 四、实践 3:生成器优化大数据处理
场景:处理 1GB 的日志文件,提取错误行
❌ 低效方式(内存溢出风险)
def get_error_lines_bad(filename): with open(filename) as f: lines = f.readlines() # 一次性读入全部内容! return [line for line in lines if "ERROR" in line]
✅ 高效方式(生成器逐行处理)
def get_error_lines_good(filename): """生成器:逐行读取,只保留错误行""" with open(filename) as f: for line in f: # 文件对象本身是迭代器! if "ERROR" in line: yield line.strip()# 使用(内存恒定)for error in get_error_lines_good("huge_log.txt"): print(error) # 或写入新文件
💡 为什么高效?
🔍 五、列表推导式 vs 生成器表达式
| | |
|---|
| [x*2 for x in range(5)] | (x*2 for x in range(5)) |
| list | generator |
| | |
| | |
示例对比
✅ 何时用哪个?
🧪 六、综合实战:银行交易流水生成器
结合前两天的银行系统,实现 交易记录生成器:
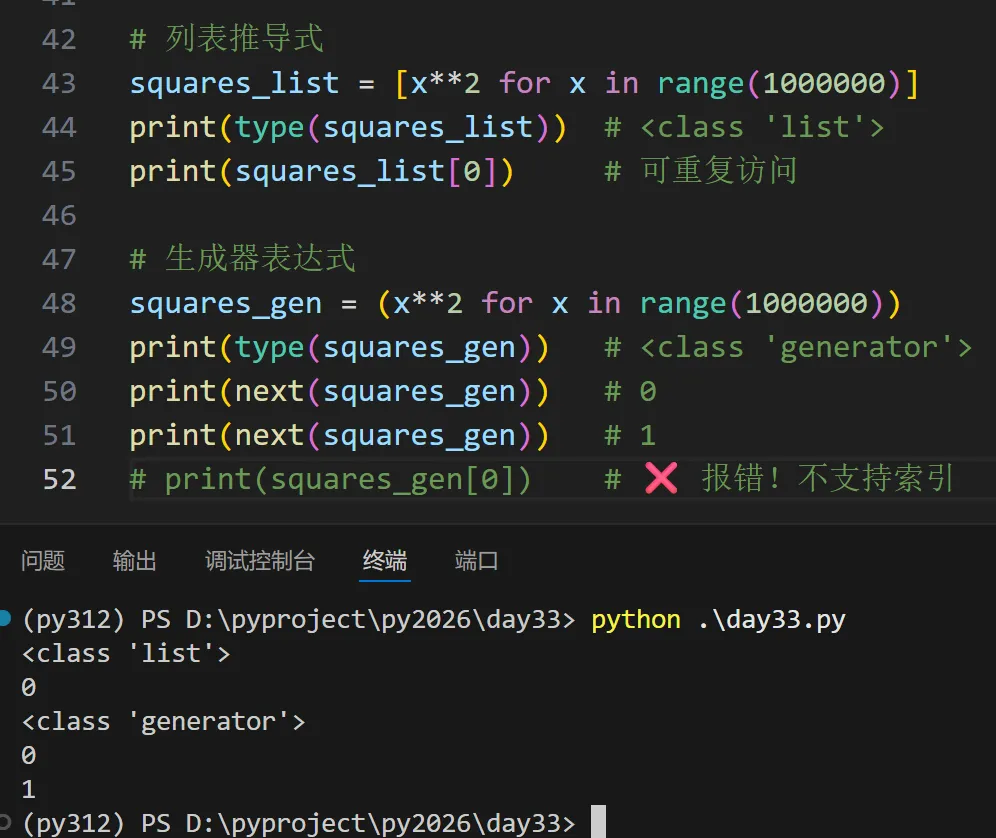
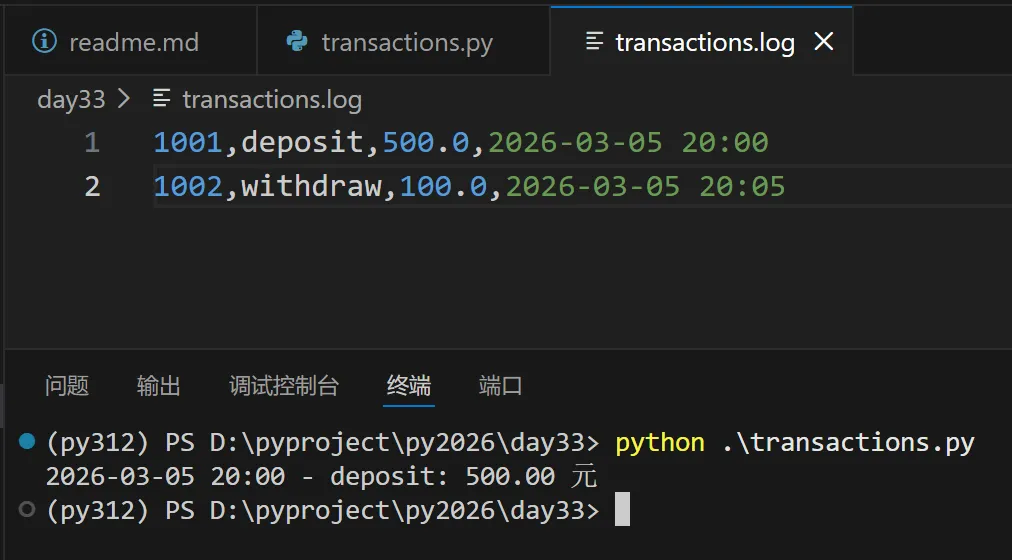
# 假设我们有交易日志文件 transactions.log# 格式: 账号,类型,金额,时间# 1001,deposit,500.0,2026-03-05 20:00# 1002,withdraw,100.0,2026-03-05 20:05def parse_transactions(filename): """解析交易日志,生成结构化数据""" with open(filename) as f: for line in f: parts = line.strip().split(',') if len(parts) == 4: yield { "account_id": int(parts[0]), "type": parts[1], "amount": float(parts[2]), "timestamp": parts[3] }def filter_by_account(transactions, account_id): """筛选指定账号的交易""" for tx in transactions: if tx["account_id"] == account_id: yield tx# 使用all_tx = parse_transactions("transactions.log")alice_tx = filter_by_account(all_tx, 1001)for tx in alice_tx: print(f"{tx['timestamp']} - {tx['type']}: {tx['amount']:.2f} 元")
✅ 优势:
🧠 七、关键知识点总结
1. 生成器三大特性
- 惰性求值:调用时才计算
- 状态保存:yield 后暂停,下次从断点继续
- 单次消费:用完即废(可重新创建)
2. 何时必须用生成器?
- 构建数据处理管道(
gen1 → gen2 → gen3)
3. 性能对比(实测)
import sys# 列表lst = [x for x in range(1000000)]print(sys.getsizeof(lst)) # ~8MB# 生成器gen = (x for x in range(1000000))print(sys.getsizeof(gen)) # ~104 字节!
✅ 今日小任务
1、实现素数生成器:
def prime_generator(): """高效素数生成器:利用已发现的素数加速判断""" primes = [] # 存储已找到的素数(内存随素数增长,但远小于全量列表) num = 2 while True: is_prime = True sqrt_num = num ** 0.5 # 只用已知素数试除(且不超过 √num) for p in primes: if p > sqrt_num: break if num % p == 0: is_prime = False break if is_prime: primes.append(num) yield num num += 1# 测试:获取前20个素数gen = prime_generator()first_20 = [next(gen) for _ in range(20)]print(first_20)# 输出: [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71]
2、优化银行系统:
- 将
load_posts() 改为生成器,逐条读取 JSON(假设每行一条记录)
# bank.py(新增函数)def load_accounts(): """ 生成器:逐行读取 accounts.jsonl,返回账户对象 内存恒定,适合大文件 """ filepath = "data/accounts.jsonl" if not os.path.exists(filepath): return # 文件不存在则无账户 with open(filepath, "r", encoding="utf-8") as f: for line_num, line in enumerate(f, 1): line = line.strip() if not line: continue # 跳过空行 try: data = json.loads(line) yield BankAccount.from_dict(data) except (json.JSONDecodeError, KeyError, ValueError) as e: logger.warning(f"跳过无效行 #{line_num}: {e}") continue
def save_accounts(accounts): """将账户列表保存为 JSONL 格式""" filepath = "data/accounts.jsonl" os.makedirs(os.path.dirname(filepath), exist_ok=True) with open(filepath, "w", encoding="utf-8") as f: for acc in accounts: f.write(json.dumps(acc.to_dict(), ensure_ascii=False) + "\n")
# bank.py(新增方法到 BankAccount 基类)import jsonclass BankAccount(ABC): # ... [原有代码] ... def to_dict(self) -> dict: """将账户转为字典(用于保存)""" return { "id": self.account_id, "owner": self.owner, "balance": self._balance, "type": self.__class__.__name__, "created_at": self.created_at } @classmethod def from_dict(cls, data: dict): """从字典重建账户对象""" if data["type"] == "SavingsAccount": account = SavingsAccount(data["owner"]) elif data["type"] == "CheckingAccount": account = CheckingAccount(data["owner"]) else: raise ValueError(f"未知账户类型: {data['type']}") # 恢复状态 account.account_id = data["id"] account._balance = data["balance"] account.created_at = data["created_at"] return account# main.py(新增功能)from bank import load_accountsdef get_high_balance_accounts(min_balance=1000.0): """ 生成器表达式:惰性过滤高余额账户 """ return (acc for acc in load_accounts() if acc.balance >= min_balance)# 使用示例print("=== 高余额账户(>=1000元)===")for account in get_high_balance_accounts(1000): print(account)
📝 小结:生成器思维
“不要把所有数据搬进内存,而是让数据流向你的代码”
生成器让你:
🎉 恭喜完成迭代器与生成器进阶!你已掌握 Python 高效数据处理的核心范式!
继续加油,你的代码正在变得越来越高效!⚡🧠
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
